This pull request introduces a CommitRequestManager to efficiently manage commit requests from clients and the autocommit state. The manager utilizes a "staged" commit queue to store commit requests made by clients. A background thread regularly polls the CommitRequestManager, which then checks the queue for any outstanding commit requests. When permitted, the CommitRequestManager generates a PollResult which contains a list of UnsentRequests that are subsequently processed by the NetworkClientDelegate.
In addition, a RequestManagerRegistry has been implemented to hold all request managers, including the new CommitRequestManager and the CoordinatorRequestManager. The registry is regularly polled by a background thread in each event loop, ensuring that all request managers are kept up to date and able to handle incoming requests
Reviewers: Jason Gustafson <jason@confluent.io>, Guozhang Wang <wangguoz@gmail.com>
While refactoring the OffsetFetch handling in KafkaApis, we introduced a NullPointerException (NPE). The NPE arises when the FetchOffset API is called with a client using a version older than version 8 and using null for the topics to signal that all topic-partition offsets must be returned. This means that this bug mainly impacts admin tools. The consumer does not use null.
This NPE is here: 24a86423e9 (diff-0f2f19fd03e2fc5aa9618c607b432ea72e5aaa53866f07444269f38cb537f3feR237).
We missed this during the refactor because we had no tests in place to test this mode.
Reviewers: Chia-Ping Tsai <chia7712@gmail.com>, Justine Olshan <jolshan@confluent.io>
After reading data of type BYTES, COMPACT_BYTES, NULLABLE_BYTES or COMPACT_NULLABLE_BYTES returned ByteBuffer might have a capacity that is larger than its limit, thus these data types may access data that lies beyond its size by increasing limit of the returned ByteBuffer. I guess this is not very critical but I think it would be good to restrict increasing limit of the returned ByteBuffer by making its capacity strictly equal to its limit. I think someone might unintentionally mishandle these data types and accidentally mess up data in the ByteBuffer from which they were read.
Reviewers: Luke Chen <showuon@gmail.com>
The `Fetcher` class is used internally by the `KafkaConsumer` to fetch records from the brokers. There is [ongoing work to create a new consumer implementation with a significantly refactored threading model](https://issues.apache.org/jira/browse/KAFKA-14246). The threading refactor work requires a similarly refactored `Fetcher`.
This task covers the work to extract from `Fetcher` the APIs that are related to metadata operations into two new classes: `OffsetFetcher` and `TopicMetadataFetcher`. This will allow the refactoring of `Fetcher` and `MetadataFetcher` for the new consumer.
Reviewers: Philip Nee <pnee@confluent.io>, Guozhang Wang <guozhang@apache.org>, Jason Gustafson <jason@confluent.io>
* assertEquals called on array
* Method is identical to its super method
* Simplifiable assertions
* Unused imports
Reviewers: Mickael Maison <mickael.maison@gmail.com>, Divij Vaidya <diviv@amazon.com>
Extend the implementation of ProcessTerminatingFaultHandler to support calling either Exit.halt or Exit.exit. Change the fault handler used by the Controller thread and the KRaft thread to use a halting fault handler.
Those threads cannot call Exit.exit because Runtime.exit joins on the default shutdown hook thread. The shutdown hook thread joins on the controller and kraft thread terminating. This causes a deadlock.
Reviewers: Colin Patrick McCabe <cmccabe@apache.org>, Jason Gustafson <jason@confluent.io>
Warnings about unused configs are most often spurious. This patch changes the current warning to an info message.
Reviewers: Chris Egerton <chrise@aiven.io>, Jason Gustafson <jason@confluent.io>
We currently cache login managers in static maps for both static JAAS config using system property and for JAAS config specified using Kafka config sasl.jaas.config. In addition to the JAAS config, the login manager callback handler is included in the key, but all other configs are ignored. This implementation is based on the assumption clients that require different logins (e.g. username/password) use different JAAS configs, because login properties are included in the JAAS config rather than as separate top-level configs. The OIDC support added in KIP-768 only allows configuration of token endpoint URL as a top-level config. This results in two clients in a JVM configured with different token endpoint URLs to incorrectly share a login.
This PR includes all SASL configs prefixed with sasl. to be included in the key so that logins are only shared if all the sasl configs are identical.
Reviewers: Manikumar Reddy <manikumar.reddy@gmail.com>, Kirk True <kirk@mustardgrain.com>
## Problem
When consumer is closed, fetch sessions associated with the consumer should notify the server about it's intention to close using a Fetch call with epoch = -1 (identified by `FINAL_EPOCH` in `FetchMetadata.java`). However, we are not sending this final fetch request in the current flow which leads to unnecessary fetch sessions on the server which are closed only after timeout.
## Changes
1. Change `close()` in `Fetcher` to add a logic to send the final Fetch request notifying close to the server.
2. Change `close()` in `Consumer` to respect the timeout duration passed to it. Prior to this change, the timeout parameter was being ignored.
3. Change tests to close with `Duration.zero` to reduce the execution time of the tests. Otherwise the tests will wait for default timeout to exit (close() in the tests is expected to be unsuccessful because there is no server to send the request to).
4. Distinguish between the case of "close existing session and create new session" and "close existing session" by renaming the `nextCloseExisting` function to `nextCloseExistingAttemptNew`.
## Testing
Added unit test which validates that the correct close request is sent to the server.
Reviewers: Ismael Juma <ismael@juma.me.uk>, Kirk True <kirk@mustardgrain.com>, Philip Nee <philipnee@gmail.com>, Luke Chen <showuon@gmail.com>, David Jacot <djacot@confluent.io>
This patch does a few things:
1) It introduces a new flag to the request spec: `latestVersionUnstable`. It signifies that the last version of the API is considered unstable (or still in development). As such, the last API version is not exposed by the server unless specified otherwise with the new internal `unstable.api.versions.enable`. This allows us to commit new APIs which are still in development.
3) It adds the ConsumerGroupHeartbeat API, part of KIP-848, and marks it as unreleased for now.
4) It adds the new error codes required by the new ConsumerGroupHeartbeat API.
Reviewers: Justine Olshan <jolshan@confluent.io>, Jeff Kim <jeff.kim@confluent.io>, Jason Gustafson <jason@confluent.io>
When running junit tests, it is not good to block forever on CompletableFuture objects. When there
are bugs, this can lead to junit tests hanging forever. Jenkins does not deal with this well -- it
often brings down the whole multi-hour test run. Therefore, when running integration tests in
JUnit, set some reasonable time limits on broker and controller startup time.
Reviewers: Jason Gustafson <jason@confluent.io>
Removes logging of the HTTP response directly in all known cases to prevent potentially logging access tokens.
Reviewers: Sushant Mahajan <sushant.mahajan88@gmail.com>, Rajini Sivaram <rajinisivaram@googlemail.com>
This patch contains a few cleanups and fixes in the new refactored consumer logic:
- Use `CompletableFuture` instead of `RequestFuture` in `NetworkClientDelegate`. This is a much more extensible API and it avoids tying the new implementation to `ConsumerNetworkClient`.
- Fix call to `isReady` in `NetworkClientDelegate`. We need the call to `ready` to initiate the connection.
- Ensure backoff is enforced even after successful `FindCoordinator` requests. This avoids a tight loop while metadata is converging after a coordinator change.
- `RequestState` was incorrectly using the reconnect backoff as the retry backoff. In fact, we don't currently have a retry backoff max implemented in the consumer, so the use of `ExponentialBackoff` is unnecessary, but I've left it since we may add this with https://cwiki.apache.org/confluence/display/KAFKA/KIP-580%3A+Exponential+Backoff+for+Kafka+Clients.
- Minor cleanups in test cases to avoid unused classes/fields.
Reviewers: Philip Nee <pnee@confluent.i>, Guozhang Wang <guozhang@apache.org>
The current documentation indicates two positions are tracked, but these positions were removed a few years ago. Now we use a single position to track the last consumed record. Updated the documentation to reflect to the current state.
Reviewers: Guozhang Wang <wangguoz@gmail.com>
This test is supposed to be a sanity check that rebalancing with a large number of partitions/consumers won't start to take obscenely long or approach the max.poll.interval.ms -- bumping up the timeout by another 30s still feels very reasonable considering the test is for 1 million partitions
Reviewers: Matthias J. Sax <mjsax@apache.org>
This patch adds `OffsetDelete` to the new `GroupCoordinator` interface and updates `KafkaApis` to use it.
Reviewers: Jeff Kim <jeff.kim@confluent.io>, Justine Olshan <jolshan@confluent.io>
While wrapping the caught exception into a custom one, information about the caught
exception is being lost, including information about the stack trace of the exception.
When re-throwing an exception, we either include the original exception or the relevant
information is added to the exception message.
Reviewers: Ismael Juma <ismael@juma.me.uk>, Luke Chen <showuon@gmail.com>, dengziming <dengziming1993@gmail.com>, Matthew de Detrich <mdedetrich@gmail.com>
This should be greater than 1 to be consistent with behavior described inmax.in.flight.requests.per.connection.
Reviewers: Bill Bejeck <bbejeck@apache.org>
This patch adds `TxnOffsetCommit` to the new `GroupCoordinator` interface and updates `KafkaApis` to use it.
Reviewers: Jeff Kim <jeff.kim@confluent.io>, Justine Olshan <jolshan@confluent.io>
This patch adds `OffsetCommit` to the new `GroupCoordinator` interface and updates `KafkaApis` to use it.
Reviewers: Omnia G H Ibrahim <o.g.h.ibrahim@gmail.com>, Jeff Kim <jeff.kim@confluent.io>, Justine Olshan <jolshan@confluent.io>
With the new broker epoch validation logic introduced in #12998, we no longer need the ZK broker epoch to be sent to the KRaft controller. This patch removes that epoch and replaces it with a boolean.
Another small fix is included in this patch for controlled shutdown in migration mode. Previously, if a ZK broker was in migration mode, it would always try to do controlled shutdown via BrokerLifecycleManager. Since there is no ordering dependency between bringing up ZK brokers and the KRaft quorum during migration, a ZK broker could be running in migration mode, but talking to a ZK controller. A small check was added to see if the current controller is ZK or KRaft before decided which controlled shutdown to attempt.
Reviewers: Colin P. McCabe <cmccabe@apache.org>
This patch adds OffsetFetch to the new GroupCoordinator interface and updates KafkaApis to use it.
Reviewers: Philip Nee <pnee@confluent.i>, Jeff Kim <jeff.kim@confluent.io>, Justine Olshan <jolshan@confluent.io>
When writing a ByteBuffer backed by a HeapBuffer to a DataOutputStream, it is necessary to pass in the offset and the position, not just the position. It is also necessary to pass the remain length, not the limit. The current code results in writing the wrong data to DataOutputStream. While the DataOutputStreamWritable is used in the project, I do not see any references that would utilize this code path, so this bug fix is relatively minor.
I added a new test to cover the exact bug. The test fails without this change.
This patch introduces a preliminary state machine that can be used by KRaft
controller to drive online migration from Zk to KRaft.
MigrationState -- Defines the states we can have while migration from Zk to
KRaft.
KRaftMigrationDriver -- Defines the state transitions, and events to handle
actions like controller change, metadata change, broker change and have
interfaces through which it claims Zk controllership, performs zk writes and
sends RPCs to ZkBrokers.
MigrationClient -- Interface that defines the functions used to claim and
relinquish Zk controllership, read to and write from Zk.
Co-authored-by: David Arthur <mumrah@gmail.com>
Reviewers: Colin P. McCabe <cmccabe@apache.org>
Saw this flaky test in recent builds: #1452, #1454,
org.opentest4j.AssertionFailedError: Unexpected channel state EXPIRED ==> expected: <true> but was: <false>
at app//org.junit.jupiter.api.AssertionFailureBuilder.build(AssertionFailureBuilder.java:151)
at app//org.junit.jupiter.api.AssertionFailureBuilder.buildAndThrow(AssertionFailureBuilder.java:132)
at app//org.junit.jupiter.api.AssertTrue.failNotTrue(AssertTrue.java:63)
at app//org.junit.jupiter.api.AssertTrue.assertTrue(AssertTrue.java:36)
at app//org.junit.jupiter.api.Assertions.assertTrue(Assertions.java:210)
at app//org.apache.kafka.common.network.SslTransportLayerTest.testIOExceptionsDuringHandshake(SslTransportLayerTest.java:883)
at app//org.apache.kafka.common.network.SslTransportLayerTest.testUngracefulRemoteCloseDuringHandshakeWrite(SslTransportLayerTest.java:833)
We expected the channel state to be AUTHENTICATE or READY, but got EXPIRED. Checking the test, we're not expecting expired state at all, but set a 5 secs idle timeout in selector, which is not enough when machine is busy. Increasing the connectionMaxIdleMs to 10 secs to make the test reliable.
Reviewers: Ismael Juma <ismael@juma.me.uk>
Also improved `LogValidatorTest` to cover a bug that was originally
only caught by `LogAppendTimeTest`.
For broader context on this change, please check:
* KAFKA-14470: Move log layer to storage module
Reviewers: Jun Rao <junrao@gmail.com>
Add the zk mgiration field which will be used by the KRaft controller to see if the quorum is
ready to handle a zk to kraft migration.
Reviewers: Colin P. McCabe <cmccabe@apache.org>
The failure handling code for fetches could run into an IllegalStateException if a fetch response came back with a failure after the corresponding topic partition has already been removed from the assignment.
Reviewers: David Jacot <djacot@confluent.io>
[KAFKA-14264](https://issues.apache.org/jira/browse/KAFKA-14264)
In this patch, we refactored the existing FindCoordinator mechanism. In particular, we first centralize all of the network operation (send, poll) in `NetworkClientDelegate`, then we introduced a RequestManager interface that is responsible to handle the timing of different kind of requests, based on the implementation. In this path, we implemented a `CoordinatorRequestManager` which determines when to create an `UnsentRequest` upon polling the request manager.
Reviewers: Jason Gustafson <jason@confluent.io>
This PR implements the follower fetch protocol as mentioned in KIP-405.
Added a new version for ListOffsets protocol to receive local log start offset on the leader replica. This is used by follower replicas to find the local log star offset on the leader.
Added a new version for FetchRequest protocol to receive OffsetMovedToTieredStorageException error. This is part of the enhanced fetch protocol as described in KIP-405.
We introduced a new field locaLogStartOffset to maintain the log start offset in the local logs. Existing logStartOffset will continue to be the log start offset of the effective log that includes the segments in remote storage.
When a follower receives OffsetMovedToTieredStorage, then it tries to build the required state from the leader and remote storage so that it can be ready to move to fetch state.
Introduced RemoteLogManager which is responsible for
initializing RemoteStorageManager and RemoteLogMetadataManager instances.
receives any leader and follower replica events and partition stop events and act on them
also provides APIs to fetch indexes, metadata about remote log segments.
Followup PRs will add more functionality like copying segments to tiered storage, retention checks to clean local and remote log segments. This will change the local log start offset and make sure the follower fetch protocol works fine for several cases.
You can look at the detailed protocol changes in KIP: https://cwiki.apache.org/confluence/display/KAFKA/KIP-405%3A+Kafka+Tiered+Storage#KIP405:KafkaTieredStorage-FollowerReplication
Co-authors: satishd@apache.org, kamal.chandraprakash@gmail.com, yingz@uber.com
Reviewers: Kowshik Prakasam <kprakasam@confluent.io>, Cong Ding <cong@ccding.com>, Tirtha Chatterjee <tirtha.p.chatterjee@gmail.com>, Yaodong Yang <yangyaodong88@gmail.com>, Divij Vaidya <diviv@amazon.com>, Luke Chen <showuon@gmail.com>, Jun Rao <junrao@gmail.com>
The OAuth code to generate the Authentication header was incorrectly
using the URL-safe base64 encoder. For client IDs and/or secrets with
dashes and/or plus signs would not be encoded correctly, leading to the
OAuth server to reject the credentials.
This change uses the correct base64 encoder, per RFC-7617.
Co-authored-by: Endre Vig <vendre@gmail.com>
Add comments to clarify that both offsets and partitions are 0-indexed, and fix a minor typo. Clarify which offset will be retrieved by poll() after seek() is used in various circumstances. Also added integration tests.
Reviewers: Luke Chen <showuon@gmail.com>
This PR enables brokers which are upgrading from ZK mode to KRaft mode to forward certain metadata
change requests to the controller instead of applying them directly through ZK. To faciliate this,
we now support EnvelopeRequest on zkBrokers (instead of only on KRaft nodes.)
In BrokerToControllerChannelManager, we can now reinitialize our NetworkClient. This is needed to
handle the case when we transition from forwarding requests to a ZK-based broker over the
inter-broker listener, to forwarding requests to a quorum node over the controller listener.
In MetadataCache.scala, distinguish between KRaft and ZK controller nodes with a new type,
CachedControllerId.
In LeaderAndIsrRequest, StopReplicaRequest, and UpdateMetadataRequest, switch from sending both a
zk and a KRaft controller ID to sending a single controller ID plus a boolean to express whether it
is KRaft. The previous scheme was ambiguous as to whether the system was in KRaft or ZK mode when
both IDs were -1 (although this case is unlikely to come up in practice). The new scheme avoids
this ambiguity and is simpler to understand.
Reviewers: dengziming <dengziming1993@gmail.com>, David Arthur <mumrah@gmail.com>, Colin P. McCabe <cmccabe@apache.org>
Prior to starting a KIP-866 migration, the ZK brokers must register themselves with the active
KRaft controller. The controller waits for all brokers to register in order to verify that all the
brokers can
A) Communicate with the quorum
B) Have the migration config enabled
C) Have the proper IBP set
This patch uses the new isMigratingZkBroker field in BrokerRegistrationRequest and
RegisterBrokerRecord. The type was changed from int8 to bool for BrokerRegistrationRequest (a
mistake from #12860). The ZK brokers use the existing BrokerLifecycleManager class to register and
heartbeat with the controllers.
Reviewers: Mickael Maison <mickael.maison@gmail.com>, Colin P. McCabe <cmccabe@apache.org>
The consumer (fetcher) used to refresh the preferred read replica on
three conditions:
1. the consumer receives an OFFSET_OUT_OF_RANGE error
2. the follower does not exist in the client's metadata (i.e., offline)
3. after metadata.max.age.ms (5 min default)
For other errors, it will continue to reach to the possibly unavailable
follower and only after 5 minutes will it refresh the preferred read
replica and go back to the leader.
Another problem is that the client might have stale metadata and not
send fetches to preferred replica, even after the leader redirects to
the preferred replica.
A specific example is when a partition is reassigned. the consumer will
get NOT_LEADER_OR_FOLLOWER which triggers a metadata update but the
preferred read replica will not be refreshed as the follower is still
online. it will continue to reach out to the old follower until the
preferred read replica expires.
The consumer can instead refresh its preferred read replica whenever it
makes a metadata update request, so when the consumer receives i.e.
NOT_LEADER_OR_FOLLOWER it can find the new preferred read replica without
waiting for the expiration.
Generally, we will rely on the leader to choose the correct preferred
read replica and have the consumer fail fast (clear preferred read replica
cache) on errors and reach out to the leader.
Co-authored-by: Jeff Kim <jeff.kim@confluent.io>
Reviewers: David Jacot <djacot@confluent.io>, Jason Gustafson <jason@confluent.io>
`core` should only be used for legacy cli tools and tools that require
access to `core` classes instead of communicating via the kafka protocol
(typically by using the client classes).
Summary of changes:
1. Convert the command implementation and tests to Java and move it to
the `tools` module.
2. Introduce mechanism to capture stdout and stderr from tests.
3. Change `kafka-metadata-quorum.sh` to point to the new command class.
4. Adjusted the test classpath of the `tools` module so that it supports tests
that rely on the `@ClusterTests` annotation.
5. Improved error handling when an exception different from `TerseFailure` is
thrown.
6. Changed `ToolsUtils` to avoid usage of arrays in favor of `List`.
Reviewers: dengziming <dengziming1993@gmail.com>
This patch does a few cleanups:
* It removes `DescribeGroupsResponse.fromError` and pushes its logic to `DescribeGroupsRequest.getErrorResponse` to be consistent with how we implemented the other requests/responses.
* It renames `DescribedGroup.forError` to `DescribedGroup.groupError`.
The patch relies on existing tests.
Reviewers: Mickael Maison <mickael.maison@gmail.com>
The broker may return the `REQUEST_TIMED_OUT` error in `InitProducerId` responses when allocating the ID using the `AllocateProducerIds` request. The client currently does not handle this. Instead of retrying as we would expect, the client raises a fatal exception to the application.
In this patch, we address this problem by modifying the producer to handle `REQUEST_TIMED_OUT` and any other retriable errors by re-enqueuing the request.
Reviewers: Jason Gustafson <jason@confluent.io>
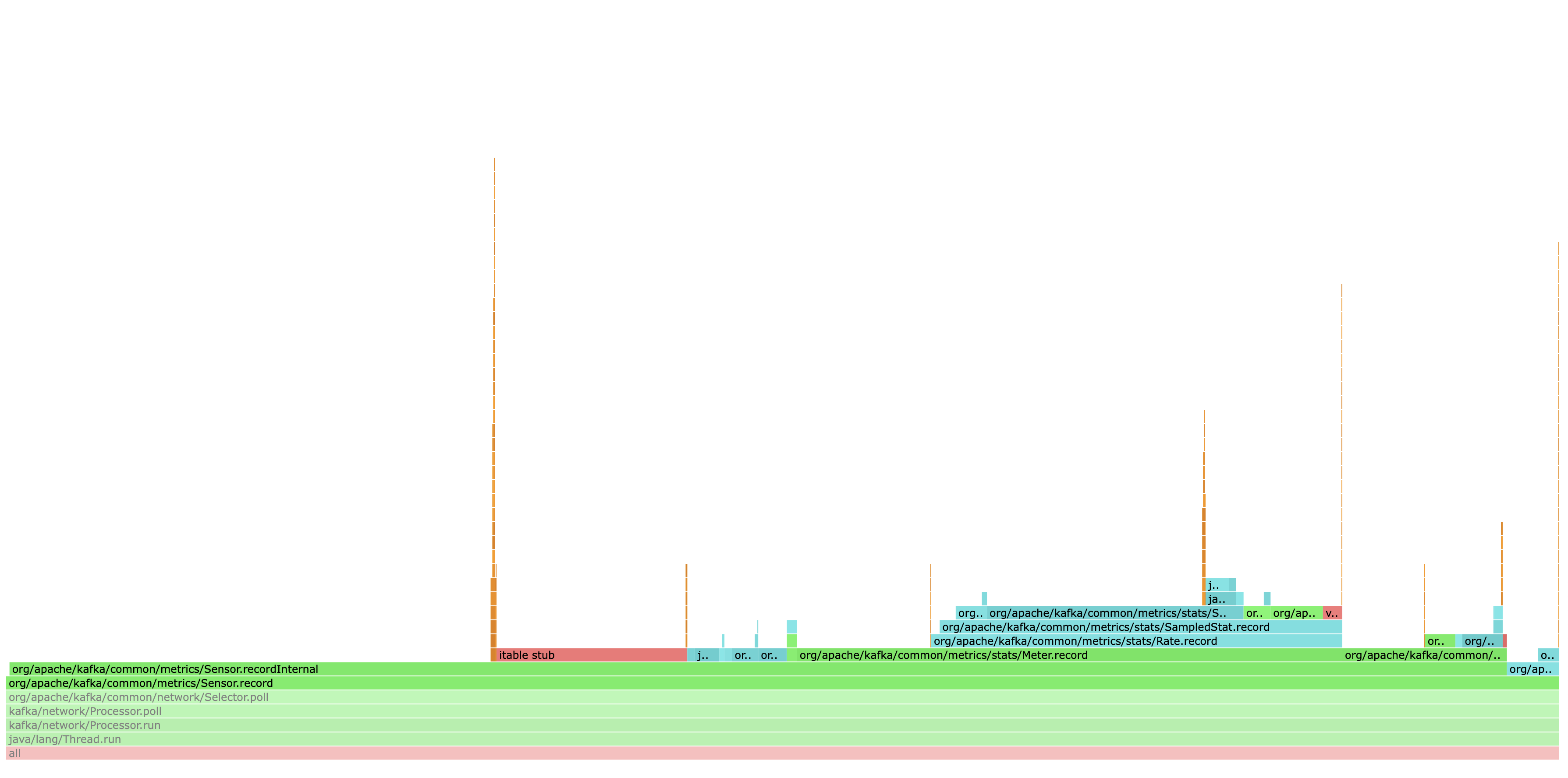
In the selector code path, we record some values for some sensors which do not have any metric associated with them that requires quota. Yet, a redundant check for quotas is made which consumes ~0.7% of CPU time in the hot path as demonstrated by the flame graph below.
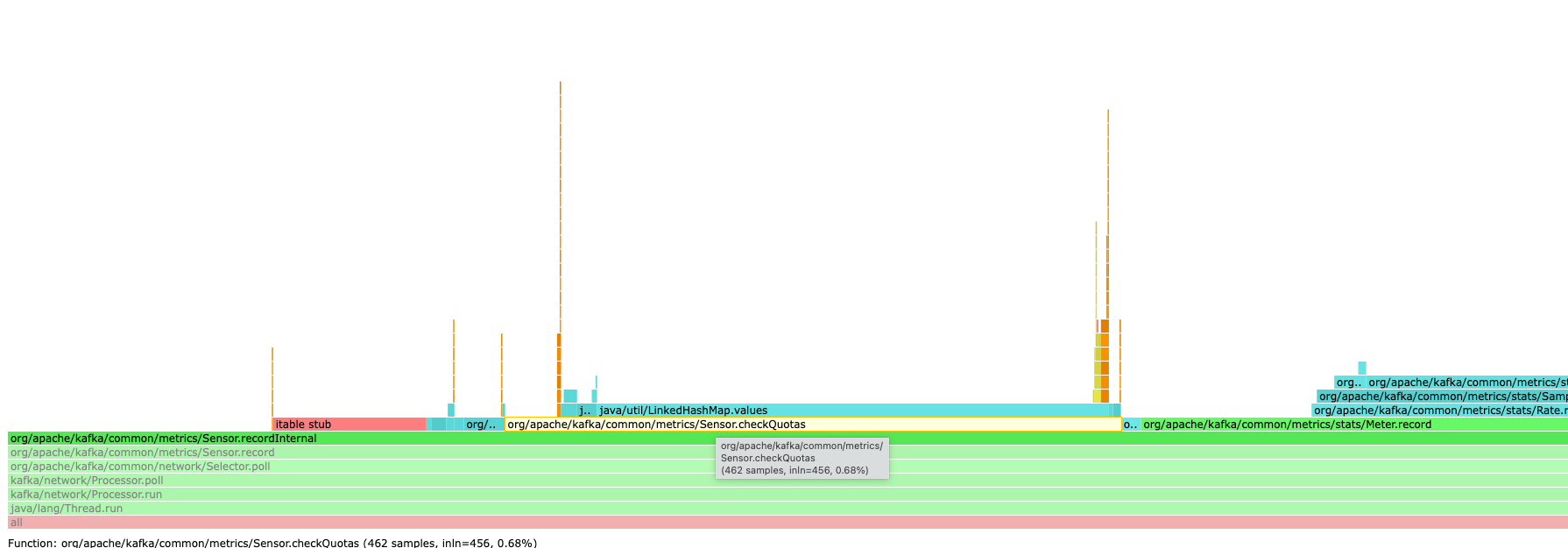
This PR is a minor optimization which removes the redundant check for quotas in cases where it is not required in the hot path.
Flamegraph after this patch (note that checkQuotas CPU utilization has been removed)
<img width="1789" alt="Screenshot 2022-12-02 at 12 00 31" src="https://user-images.githubusercontent.com/71267/205278204-798fbe96-0acf-4fa4-995b-19b66b6c2cbb.png">
Reviewers: Luke Chen <showuon@gmail.com>, David Jacot <djacot@confluent.io>
This patch adds `leaveGroup` to the new `GroupCoordinator` interface and updates `KafkaApis` to use it.
Reviewers: Justine Olshan <jolshan@confluent.io>, Jeff Kim <jeff.kim@confluent.io>, Jason Gustafson <jason@confluent.io>
Extract jointly owned parts of BrokerServer and ControllerServer into SharedServer. Shut down
SharedServer when the last component using it shuts down. But make sure to stop the raft manager
before closing the ControllerServer's sockets.
This PR also fixes a memory leak where ReplicaManager was not removing some topic metric callbacks
during shutdown. Finally, we now release memory from the BatchMemoryPool in KafkaRaftClient#close.
These changes should reduce memory consumption while running junit tests.
Reviewers: Jason Gustafson <jason@confluent.io>, Ismael Juma <ismael@juma.me.uk>
With KRaft the cluster metadata topic (__cluster_metadata) has a different implementation compared to regular topic. The user should not be allowed to create this topic. This can cause issues if the metadata log dir is the same as one of the log dirs.
This change returns an authorization error if the user tries to create the cluster metadata topic.
Reviewers: David Arthur <mumrah@gmail.com>
The IBM Semeru JDK use the OpenJDK security providers instead of the IBM security providers so test for the OpenJDK classes first where possible and test for Semeru in the java.runtime.name system property otherwise.
Reviewers: Mickael Maison <mickael.maison@gmail.com>, Bruno Cadonna <cadonna@apache.org>
Implementation for KIP-792, to add generationId field in ConsumerProtocolSubscription message. So when doing assignment, we'll take from subscription generationId fields it is provided in cooperative rebalance protocol. Otherwise, we'll fall back to original solution to use userData.
Reviewers: David Jacot <djacot@confluent.io>
When a consumer group on a version prior to 2.3 is upgraded to a newer version and static membership is enabled in the meantime, the consumer group remains stuck, iff the leader is still on the old version.
The issue is that setting `GroupInstanceId` in the response to the leader is only supported from JoinGroup version >= 5 and that `GroupInstanceId` is not ignorable nor handled anywhere else. Hence is there is at least one static member in the group, sending the JoinGroup response to the leader fails with a serialization error.
```
org.apache.kafka.common.errors.UnsupportedVersionException: Attempted to write a non-default groupInstanceId at version 2
```
When this happens, the member stays around until the group coordinator is bounced because a member with a non-null `awaitingJoinCallback` is never expired.
This patch fixes the issue by making `GroupInstanceId` ignorable. A unit test has been modified to cover this.
Reviewers: Jason Gustafson <jason@confluent.io>
This fixes an bug which causes a call to producer.send(record) with a record without a key and configured with batch.size=0 never to return.
Without specifying a key or a custom partitioner the new BuiltInPartitioner, as described in KIP-749 kicks in.
BuiltInPartitioner seems to have been designed with the reasonable assumption that the batch size will never be lower than one.
However, documentation for producer configuration states batch.size=0 as a valid value, and even recommends its use directly. [1]
[1] clients/src/main/java/org/apache/kafka/clients/producer/ProducerConfig.java:87
Reviewers: Artem Livshits <alivshits@confluent.io>, Luke Chen <showuon@gmail.com>, Ismael Juma <ismael@juma.me.uk>, Jun Rao <junrao@gmail.com>
This is a small refactor extracted from https://github.com/apache/kafka/pull/12845. It basically moves the logic to handle the backward compatibility of `JoinGroupResponseData.protocolName` from `KafkaApis` to `JoinGroupResponse`.
The patch adds a new unit test for `JoinGroupResponse` and relies on existing tests as well.
Reviewers: Justine Olshan <jolshan@confluent.io>, Jason Gustafson <jason@confluent.io>
Reviewers: Mickael Maison <mickael.maison@gmail.com>, Tom Bentley <tombentley@users.noreply.github.com>
Co-authored-by: Tom Bentley <tombentley@users.noreply.github.com>
Co-authored-by: oibrahim3 <omnia@apple.com>
Improves logs withing Streams by replacing timestamps to date instances to improve readability.
Approach - Adds a function within common.utils.Utils to convert a given long timestamp to a date-time string with the same format used by Kafka's logger.
Reviewers: Divij Vaidya <diviv@amazon.com>, Bruno Cadonna <cadonna@apache.org>
This is an outdated comment about the metadata request from the old implementation. The name of the RPC was changed from GroupMetadata to FindCoordinator, but the comment was not updated.
Reviewers: Jason Gustafson <jason@confluent.io>
Minor revision for KAFKA-14247. Added how the handler is called and constructed to the prototype code path.
Reviewers: John Roesler <vvcephei@apache.org>, Kirk True <kirk@mustardgrain.com>
Also moves the Streams LogCaptureAppender class into the clients module so that it can be used by both Streams and Connect.
Reviewers: Nigel Liang <nigel@nigelliang.com>, Kalpesh Patel <kpatel@confluent.io>, John Roesler <vvcephei@apache.org>, Tom Bentley <tbentley@redhat.com>
In https://github.com/apache/kafka/pull/12695, we discovered a gap in our testing of `StandardAuthorizer`. We addressed the specific case that was failing, but I think we need to establish a better methodology for testing which incorporates randomized inputs. This patch is a start in that direction. We implement a few basic property tests using jqwik which focus on prefix searching. It catches the case from https://github.com/apache/kafka/pull/12695 prior to the fix. In the future, we can extend this to cover additional operation types, principal matching, etc.
Reviewers: David Arthur <mumrah@gmail.com>
* KAFKA-13725: KIP-768 OAuth code mixes public and internal classes in same package
Move classes into a sub-package of "internal" named "secured" that
matches the layout more closely of the "unsecured" package.
Replaces the concrete implementations in the former packages with
sub-classes of the new package layout and marks them as deprecated. If
anyone is already using the newer OAuth code, this should still work.
* Fix checkstyle and spotbugs violations
Co-authored-by: Kirk True <kirk@mustardgrain.com>
Reviewers: Manikumar Reddy <manikumar.reddy@gmail.com>
This adds a new configuration `sasl.server.max.receive.size` that sets the maximum receive size for requests before and during authentication.
Reviewers: Tom Bentley <tbentley@redhat.com>, Mickael Maison <mickael.maison@gmail.com>
Co-authored-by: Manikumar Reddy <manikumar.reddy@gmail.com>
Co-authored-by: Mickael Maison <mickael.maison@gmail.com>
When deserializing KRPC (which is used for RPCs sent to Kafka, Kafka Metadata records, and some
other things), check that we have at least N bytes remaining before allocating an array of size N.
Remove DataInputStreamReadable since it was hard to make this class aware of how many bytes were
remaining. Instead, when reading an individual record in the Raft layer, simply create a
ByteBufferAccessor with a ByteBuffer containing just the bytes we're interested in.
Add SimpleArraysMessageTest and ByteBufferAccessorTest. Also add some additional tests in
RequestResponseTest.
Reviewers: Tom Bentley <tbentley@redhat.com>, Mickael Maison <mickael.maison@gmail.com>, Colin McCabe <colin@cmccabe.xyz>
Co-authored-by: Colin McCabe <colin@cmccabe.xyz>
Co-authored-by: Manikumar Reddy <manikumar.reddy@gmail.com>
Co-authored-by: Mickael Maison <mickael.maison@gmail.com>
Currently HttpAccessTokenRetriever client side class does not retrieve error response from the token e/p. As a result, seemingly trivial config issues could take a lot of time to diagnose and fix. For example, client could be sending invalid client secret, id or scope.
This PR aims to remedy the situation by retrieving the error response, if present and logging as well as appending to any exceptions thrown.
New unit tests have also been added.
Reviewers: Manikumar Reddy <manikumar.reddy@gmail.com>
Now the built-in partitioner defers partition switch (while still
accounting produced bytes) if there is no ready batch to send, thus
avoiding switching partitions and creating fractional batches.
Reviewers: Jun Rao <jun@confluent.io>
Asynchronous offset commits may throw an unexpected WakeupException following #11631 and #12244. This patch fixes the problem by passing through a flag to ensureCoordinatorReady to indicate whether wakeups should be disabled. This is used to disable wakeups in the context of asynchronous offset commits. All other uses leave wakeups enabled.
Note: this patch builds on top of #12611.
Co-Authored-By: Guozhang Wang wangguoz@gmail.com
Reviewers: Luke Chen <showuon@gmail.com>
When auto-commit is enabled with the "eager" rebalance strategy, the consumer will commit all offsets prior to revocation. Following recent changes, this offset commit is done asynchronously, which means there is an opportunity for fetches to continue returning data to the application. When this happens, the progress is lost following revocation, which results in duplicate consumption. This patch fixes the problem by adding a flag in `SubscriptionState` to ensure that partitions which are awaiting revocation will not continue being fetched.
Reviewers: Luke Chen <showuon@gmail.com>, Jason Gustafson <jason@confluent.io>
Currently forwarded requests are not applied to any quotas on either the controller or the broker. The controller-side throttling requires the controller to apply the quota changes from the log to the quota managers, which will be done separately. In this patch, we change the response logic on the broker side to also apply the broker's request quota. The enforced throttle time is the maximum of the throttle returned from the controller (which is 0 until we fix the aforementioned issue) and the broker's request throttle time.
Reviewers: David Arthur <mumrah@gmail.com>
Why
Current set of integration tests leak files in the /tmp directory which makes it cumbersome if you don't restart the machine often.
Fix
Replace the usage of File.createTempFile with existing TestUtils.tempFile method across the test files. TestUtils.tempFile automatically performs a clean up of the temp files generated in /tmp/ folder.
Reviewers: Luke Chen <showuon@gmail.com>, Ismael Juma <mlists@juma.me.uk>
The consumer group instance ID is used to support a notion of "static" consumer groups. The idea is to be able to identify the same group instance across restarts so that a rebalance is not needed. However, if the user sets `group.instance.id` in the consumer configuration, but uses "simple" assignment with `assign()`, then the instance ID nevertheless is sent in the OffsetCommit request to the coordinator. This may result in a surprising UNKNOWN_MEMBER_ID error.
This PR fixes the issue on the client side by not setting the group instance id if the member id is empty (no generation).
Reviewers: Jason Gustafson <jason@confluent.io>
When utilizing the rack-aware consumer configuration and rolling updates are being applied to the Kafka brokers the metadata updates can be in a transient state and a given topic-partition can be missing from the metadata. This seems to resolve itself after a bit of time but before it can resolve the `Cluster.nodeIfOnline` method throws an NPE. This patch checks to make sure that a given topic-partition has partition info available before using that partition info.
Reviewers: David Jacot <djacot@confluent.io>
{kind=link}
{kind=link}