Doco updates based on recent mailing list discussions/feedback
This commit is contained in:
parent
5cd3bd2b97
commit
7b788fcb89
|
|
@ -20,34 +20,35 @@ of a publisher and a consumer:
|
|||
|
||||
|
||||
|
||||
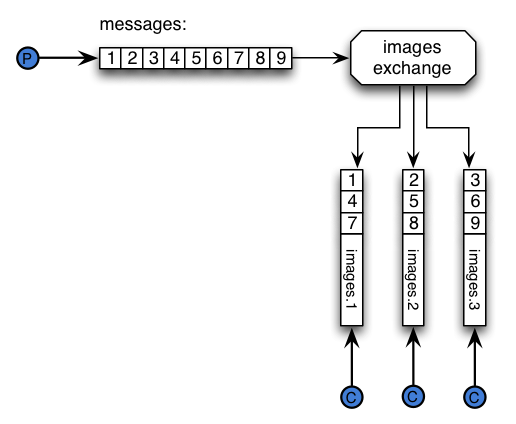
As you can see in the graphic, the producers publishes a series of
|
||||
On the picture above the producers publishes a series of
|
||||
messages, those messages get partitioned to different queues, and then
|
||||
our consumer get messages from one of those queues. Therefore if you
|
||||
have a partition with 3 queues, then you will need to have at least 3
|
||||
our consumer get messages from one of those queues. Therefore if there is
|
||||
a partition with 3 queues, it is assumed that there are at least 3
|
||||
consumers to get all the messages from those queues.
|
||||
|
||||
## Auto-scaling ##
|
||||
Queues in RabbitMQ are [units of concurrency](http://www.rabbitmq.com/queues.html#runtime-characteristics)
|
||||
(and, if there are enough cores available, parallelism). This plugin makes
|
||||
it possible to have a single logical queue that is partitioned into
|
||||
multiple regular queues ("shards"). This trades off total ordering
|
||||
on the logical queue for gains in parallelism.
|
||||
|
||||
One interesting property of this plugin, is that if you add more nodes
|
||||
to your RabbitMQ cluster, then the plugin will automatically create
|
||||
more shards in the new node. Say you had a shard with 4 queues in
|
||||
`node a` and `node b` just joined the cluster. The plugin will
|
||||
automatically create 4 queues in `node b` and join them to the shard
|
||||
partition. Already delivered messages _will not_ be rebalanced, but
|
||||
newly arriving messages will be partitioned to the new queues.
|
||||
Message distribution between shards (partitioning) is achieved
|
||||
with a custom exchange type that distributes messages by applying
|
||||
a hashing function to the routing key.
|
||||
|
||||
## Partitioning Messages ##
|
||||
|
||||
The exchanges that ship by default with RabbitMQ work in a "all or
|
||||
## Messages Distribution Between Shards (Partitioning)
|
||||
|
||||
The exchanges that ship by default with RabbitMQ work in an "all or
|
||||
nothing" fashion, i.e: if a routing key matches a set of queues bound
|
||||
to the exchange, then RabbitMQ will route the message to all the
|
||||
queues in that set. Therefore for this plugin to work, we need to
|
||||
queues in that set. For this plugin to work it is necessary to
|
||||
route messages to an exchange that would partition messages, so they
|
||||
are routed to _at most_ one queue.
|
||||
are routed to _at most_ one queue (a subset).
|
||||
|
||||
The plugin provides a new exchange type `"x-modulus-hash"` that will use
|
||||
the traditional hashing technique applying to partition messages
|
||||
across queues.
|
||||
The plugin provides a new exchange type, `"x-modulus-hash"`, that will use
|
||||
a hashing function to partition messages routed to a logical queue
|
||||
across a number of regular queues (shards).
|
||||
|
||||
The `"x-modulus-hash"` exchange will hash the routing key used to
|
||||
publish the message and then it will apply a `Hash mod N` to pick the
|
||||
|
|
@ -55,13 +56,27 @@ queue where to route the message, where N is the number of queues
|
|||
bound to the exchange. **This exchange will completely ignore the
|
||||
binding key used to bind the queue to the exchange**.
|
||||
|
||||
You could also use other exchanges that have similar behaviour like
|
||||
the _Consistent Hash Exchange_ or the _Random Exchange_. The first
|
||||
one has the advantage of shipping directly with RabbitMQ.
|
||||
There are other exchanges with similar behaviour:
|
||||
the _Consistent Hash Exchange_ or the _Random Exchange_.
|
||||
Those were designed with regular queues in mind, not this plugin, so `"x-modulus-hash"`
|
||||
is highly recommended.
|
||||
|
||||
If message partitioning is the only feature necessary and the automatic scaling
|
||||
of the number of shards (covered below) is not needed or desired, consider using
|
||||
[Consistent Hash Exchange](https://github.com/rabbitmq/rabbitmq-consistent-hash-exchange)
|
||||
instead of this plugin.
|
||||
|
||||
|
||||
## Auto-scaling
|
||||
|
||||
One of the main properties of this plugin is that when a new node
|
||||
is added to the RabbitMQ cluster, then the plugin will automatically create
|
||||
more shards on the new node. Say there is a shard with 4 queues on
|
||||
`node a` and `node b` just joined the cluster. The plugin will
|
||||
automatically create 4 queues on `node b` and "join" them to the shard
|
||||
partition. Already delivered messages _will not_ be rebalanced but
|
||||
newly arriving messages will be partitioned to the new queues.
|
||||
|
||||
If _just need message partitioning_ but not the automatic queue
|
||||
creation provided by this plugin, then you can just use the
|
||||
[Consistent Hash Exchange](https://github.com/rabbitmq/rabbitmq-consistent-hash-exchange).
|
||||
|
||||
## Consuming From a Sharded [Pseudo-]Queue ##
|
||||
|
||||
|
|
@ -109,6 +124,15 @@ this plugin.
|
|||
For load balancers, the "least connections" strategy is more likely to produce an even distribution compared
|
||||
to round robin and other strategies.
|
||||
|
||||
### How Evenly Will Messages Be Distributed?
|
||||
|
||||
As with many data distribution approaches based on a hashing function,
|
||||
even distribution between shards depends on the distribution (variability) of inputs,
|
||||
that is, routing keys. In other words the larger the set of routing keys is,
|
||||
the more even will message distribution between shareds be. If all messages had
|
||||
the same routing key, they would all end up on the same shard.
|
||||
|
||||
|
||||
|
||||
## Installing ##
|
||||
|
||||
|
|
@ -116,7 +140,7 @@ to round robin and other strategies.
|
|||
|
||||
As of RabbitMQ `3.6.0` this plugin is included into the RabbitMQ distribution.
|
||||
|
||||
Enable it with the following command:
|
||||
Like any other [RabbitMQ plugin](http://www.rabbitmq.com/plugins.html) it has to be enabled before it can be used:
|
||||
|
||||
```bash
|
||||
rabbitmq-plugins enable rabbitmq_sharding
|
||||
|
|
|
|||
Loading…
Reference in New Issue