mirror of https://github.com/alibaba/MNN.git
Merge pull request #3087 from alibaba/feature/sync
MNN:Sync: Sync Internal 3.0.0
This commit is contained in:
commit
e460135a0a
|
|
@ -24,6 +24,7 @@ out/
|
|||
.gradle
|
||||
.gradle/
|
||||
build/
|
||||
buildvisionOs/
|
||||
|
||||
# Signing files
|
||||
.signing/
|
||||
|
|
|
|||
|
|
@ -73,7 +73,7 @@ option(MNN_SUPPORT_BF16 "Enable MNN's bf16 op" OFF)
|
|||
option(MNN_LOW_MEMORY "Build MNN support low memory for weight quant model." OFF)
|
||||
option(MNN_CPU_WEIGHT_DEQUANT_GEMM "Build MNN CPU weight dequant related gemm kernels." OFF)
|
||||
|
||||
IF (OHOS)
|
||||
IF (OHOS AND MNN_INTERNAL)
|
||||
include($ENV{NODE_PATH}/@ali/tcpkg/tcpkg.cmake)
|
||||
export_headers(DIR ${CMAKE_SOURCE_DIR}/include/MNN)
|
||||
IF (MNN_BUILD_OPENCV)
|
||||
|
|
@ -209,6 +209,7 @@ option(MNN_VULKAN "Enable Vulkan" OFF)
|
|||
option(MNN_ARM82 "Enable ARMv8.2's FP16 Compute" ON)
|
||||
option(MNN_KLEIDIAI "Enable KLEIDIAI" OFF)
|
||||
option(MNN_ONEDNN "Enable oneDNN" OFF)
|
||||
option(MNN_AVX2 "Open AVX2 Compile for x86 if possible" ON)
|
||||
option(MNN_AVX512 "Enable AVX512" OFF)
|
||||
option(MNN_CUDA "Enable CUDA" OFF)
|
||||
option(MNN_TENSORRT "Enable TensorRT" OFF)
|
||||
|
|
@ -312,6 +313,9 @@ IF(MNN_DEBUG_MEMORY)
|
|||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fsanitize=address")
|
||||
endif()
|
||||
|
||||
set(MNN_DEPS "")
|
||||
set(MNN_EXTRA_DEPENDS "")
|
||||
|
||||
IF(CMAKE_BUILD_TYPE MATCHES Debug)
|
||||
add_definitions(-DMNN_DEBUG -DDEBUG)
|
||||
if(MSVC)
|
||||
|
|
@ -337,6 +341,13 @@ else()
|
|||
endif()
|
||||
endif()
|
||||
ENDIF(CMAKE_BUILD_TYPE MATCHES Debug)
|
||||
if(OHOS)
|
||||
IF(MNN_USE_LOGCAT)
|
||||
add_definitions(-DMNN_USE_LOGCAT)
|
||||
add_definitions(-Wno-format-security)
|
||||
list(APPEND MNN_EXTRA_DEPENDS libhilog_ndk.z.so)
|
||||
ENDIF()
|
||||
endif()
|
||||
if(CMAKE_SYSTEM_NAME MATCHES "^Android")
|
||||
IF(MNN_USE_LOGCAT)
|
||||
add_definitions(-DMNN_USE_LOGCAT)
|
||||
|
|
@ -456,8 +467,6 @@ IF(MNN_BUILD_LLM)
|
|||
ENDIF()
|
||||
|
||||
|
||||
set(MNN_DEPS "")
|
||||
set(MNN_EXTRA_DEPENDS "")
|
||||
|
||||
# Add Thread dependency
|
||||
find_package(Threads)
|
||||
|
|
@ -505,13 +514,11 @@ if (NOT MSVC)
|
|||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fstrict-aliasing -ffunction-sections -fdata-sections -ffast-math -fno-rtti -fno-exceptions ")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fstrict-aliasing -ffunction-sections -fdata-sections -ffast-math")
|
||||
else()
|
||||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /fp:fast")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} /fp:fast")
|
||||
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} /fp:precise")
|
||||
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} /fp:precise")
|
||||
endif()
|
||||
|
||||
# Metal
|
||||
set(MNN_DEPS "")
|
||||
set(MNN_EXTRA_DEPENDS "")
|
||||
list(APPEND MNN_DEPS MNN)
|
||||
|
||||
# Plugin
|
||||
|
|
@ -531,14 +538,10 @@ endif()
|
|||
# CoreML
|
||||
IF(MNN_COREML)
|
||||
add_definitions(-DMNN_COREML_ENABLED=1)
|
||||
add_subdirectory(${CMAKE_CURRENT_LIST_DIR}/source/backend/coreml/)
|
||||
include(${CMAKE_CURRENT_LIST_DIR}/source/backend/coreml/CMakeLists.txt)
|
||||
|
||||
IF(MNN_SEP_BUILD)
|
||||
list(APPEND MNN_DEPS MNNCoreML)
|
||||
list(APPEND MNN_EXTRA_DEPENDS MNNCoreML)
|
||||
ELSE()
|
||||
list(APPEND MNN_TARGETS MNNCoreML)
|
||||
list(APPEND MNN_OBJECTS_TO_LINK $<TARGET_OBJECTS:MNNCoreML>)
|
||||
ENDIF()
|
||||
|
||||
find_library(COREML CoreML)
|
||||
find_library(FOUNDATION Foundation)
|
||||
|
|
@ -639,7 +642,7 @@ ELSE()
|
|||
ENDIF()
|
||||
|
||||
# Model Internal. Enable MNN internal features such as model authentication and metrics logging.
|
||||
if (MNN_INTERNAL)
|
||||
if (MNN_INTERNAL AND NOT OHOS) # TODO: support OHOS logging
|
||||
target_compile_options(MNNCore PRIVATE -DMNN_INTERNAL_ENABLED)
|
||||
target_compile_options(MNN_Express PRIVATE -DMNN_INTERNAL_ENABLED)
|
||||
include(${CMAKE_CURRENT_LIST_DIR}/source/internal/logging/CMakeLists.txt)
|
||||
|
|
|
|||
|
|
@ -7,6 +7,10 @@
|
|||
## Intro
|
||||
MNN is a highly efficient and lightweight deep learning framework. It supports inference and training of deep learning models and has industry-leading performance for inference and training on-device. At present, MNN has been integrated into more than 30 apps of Alibaba Inc, such as Taobao, Tmall, Youku, DingTalk, Xianyu, etc., covering more than 70 usage scenarios such as live broadcast, short video capture, search recommendation, product searching by image, interactive marketing, equity distribution, security risk control. In addition, MNN is also used on embedded devices, such as IoT.
|
||||
|
||||
[MNN-LLM](https://github.com/alibaba/MNN/tree/master/transformers/llm) is a large language model runtime solution developed based on the MNN engine. The mission of this project is to deploy LLM models locally on everyone's platforms(Mobile Phone/PC/IOT). It supports popular large language models such as Qianwen, Baichuan, Zhipu, LLAMA, and others. [MNN-LLM User guide](https://mnn-docs.readthedocs.io/en/latest/transformers/llm.html)
|
||||
|
||||
[MNN-Diffusion](https://github.com/alibaba/MNN/tree/master/transformers/diffusion) is a stable diffusion model runtime solution developed based on the MNN engine. The mission of this project is to deploy stable diffusion models locally on everyone's platforms. [MNN-Diffusion User guide](https://mnn-docs.readthedocs.io/en/latest/transformers/diffusion.html)
|
||||
|
||||

|
||||
|
||||
Inside Alibaba, [MNN](https://mp.weixin.qq.com/s/5I1ISpx8lQqvCS8tGd6EJw) works as the basic module of the compute container in the [Walle](https://mp.weixin.qq.com/s/qpeCETty0BqqNJV9CMJafA) System, the first end-to-end, general-purpose, and large-scale production system for device-cloud collaborative machine learning, which has been published in the top system conference OSDI’22. The key design principles of MNN and the extensive benchmark testing results (vs. TensorFlow, TensorFlow Lite, PyTorch, PyTorch Mobile, TVM) can be found in the OSDI paper. The scripts and instructions for benchmark testing are put in the path “/benchmark”. If MNN or the design of Walle helps your research or production use, please cite our OSDI paper as follows:
|
||||
|
|
@ -26,7 +30,9 @@ Inside Alibaba, [MNN](https://mp.weixin.qq.com/s/5I1ISpx8lQqvCS8tGd6EJw) works a
|
|||
|
||||
|
||||
## Documentation and Workbench
|
||||
MNN's docs are in place in [Yuque docs here](https://www.yuque.com/mnn/en) and [Read the docs](https://mnn-docs.readthedocs.io/en/latest).
|
||||
MNN's docs are in place in [Read the docs](https://mnn-docs.readthedocs.io/en/latest).
|
||||
|
||||
You can also read docs/README to build docs's html.
|
||||
|
||||
MNN Workbench could be downloaded from [MNN's homepage](http://www.mnn.zone), which provides pretrained models, visualized training tools, and one-click deployment of models to devices.
|
||||
|
||||
|
|
|
|||
|
|
@ -6,6 +6,10 @@
|
|||
|
||||
[MNN](https://github.com/alibaba/MNN)是一个轻量级的深度神经网络引擎,支持深度学习的推理与训练。适用于服务器/个人电脑/手机/嵌入式各类设备。目前,MNN已经在阿里巴巴的手机淘宝、手机天猫、优酷等30多个App中使用,覆盖直播、短视频、搜索推荐、商品图像搜索、互动营销、权益发放、安全风控等场景。
|
||||
|
||||
[MNN-LLM](https://github.com/alibaba/MNN/tree/master/transformers/llm)是基于MNN引擎开发的大语言模型运行方案,解决大语言模型在本地设备的高效部署问题(手机/个人电脑/嵌入式设备)。支持常见的千问/百川/智谱/LLAMA等大语言模型。使用教程:[MNN-LLM使用教程](https://mnn-docs.readthedocs.io/en/latest/transformers/llm.html)
|
||||
|
||||
[MNN-Diffusion](https://github.com/alibaba/MNN/tree/master/transformers/diffusion)是基于MNN引擎开发的Stable Diffusion文生图模型运行方案,解决Stable Diffusion模型在本地设备的高效部署问题。使用教程:[MNN-Diffusion使用教程](https://mnn-docs.readthedocs.io/en/latest/transformers/diffusion.html)
|
||||
|
||||

|
||||
|
||||
在阿里巴巴中,[MNN](https://mp.weixin.qq.com/s/5I1ISpx8lQqvCS8tGd6EJw)被用作为[Walle](https://mp.weixin.qq.com/s/qpeCETty0BqqNJV9CMJafA)系统中计算容器的基础模块。Walle是首个端到端、通用型、规模化产业应用的端云协同机器学习系统,发表于操作系统顶会OSDI 2022。Walle的论文中解释了MNN的关键设计理念,并提供了MNN相对于其他深度学习框架(TensorFlow, TensorFlow Lite, PyTorch, PyTorch Mobile, TVM)的benchmark测试结果。相关测试脚本和说明文档被放在“/benchmark”目录下。如果MNN或Walle的设计对你的研究或生产有所助益,欢迎引用我们的OSDI论文:
|
||||
|
|
@ -26,7 +30,9 @@
|
|||
## 文档与工作台
|
||||
MNN文档:
|
||||
- [最新文档(readthedocs)](https://mnn-docs.readthedocs.io/en/latest/index.html)
|
||||
- [语雀文档](https://www.yuque.com/mnn/cn)
|
||||
|
||||
- 也可阅读 docs/README ,编译本地文档
|
||||
|
||||
|
||||
[MNN官网](http://www.mnn.zone)上还可以下载MNN团队全新力作MNN工作台,涵盖开箱即用模型、可视化训练等工具,更可以一键部署到多端设备。
|
||||
|
||||
|
|
|
|||
|
|
@ -40,7 +40,8 @@ MNN使用CMake构建项目,CMake中的宏定义列表如下:
|
|||
| MNN_VULKAN | 是否构建`Vulkan`后端,默认为`OFF` |
|
||||
| MNN_ARM82 | 编译ARM架构时,是否构建`Armv8.2`后端,以支持FP16计算,默认为`ON` |
|
||||
| MNN_ONEDNN | 是否使用`oneDNN`,默认为`OFF` |
|
||||
| MNN_AVX512 | 是否构建`avx512`后端,默认为`OFF` |
|
||||
| MNN_AVX2 | 在`MNN_USE_SSE`开启的基础上,是否增加AVX2指令的支持,默认为`ON` |
|
||||
| MNN_AVX512 | 在`MNN_USE_SSE`和`MNN_AVX2`开启的基础上,是否增加`avx512`指令集的支持,默认为`OFF` |
|
||||
| MNN_CUDA | 是否构建`Cuda`后端,默认为`OFF` |
|
||||
| MNN_CUDA_PROFILE | 是否打开CUDA profile工具,默认为`OFF` |
|
||||
| MNN_CUDA_QUANT | 是否打开CUDA 量化文件编译,默认为`OFF` |
|
||||
|
|
@ -85,3 +86,4 @@ MNN使用CMake构建项目,CMake中的宏定义列表如下:
|
|||
| MNN_SUPPORT_TRANSFORMER_FUSE | 是否支持Fuse Transformer相关OP实现,默认为 `OFF` |
|
||||
| MNN_BUILD_LLM | 是否构建基于MNN的llm库和demo,默认为`OFF` |
|
||||
| MNN_BUILD_DIFFUSION | 是否构建基于MNN的diffusion demo,需要打开MNN_BUILD_OPENCV和MNN_IMGCODECS宏使用 默认为`OFF` |
|
||||
| MNN_KLEIDIAI | 是否集成ARM的klediAI加速库【目前处于实验状态,只能跑对称量化的LLM模型】,默认为`OFF` |
|
||||
|
|
|
|||
|
|
@ -1,17 +1,17 @@
|
|||
# 主库编译
|
||||
默认编译产物为:`libMNN.so`,`express/libMNN_Express.so`
|
||||
## Linux/MacOS
|
||||
- 环境要求
|
||||
### 环境要求
|
||||
- cmake >= 3.10
|
||||
- gcc >= 4.9 或者使用 clang
|
||||
- 相关编译选项
|
||||
### 相关编译选项
|
||||
- `MNN_AVX512` 是否使用AVX512指令,需要gcc9以上版本编译
|
||||
- `MNN_OPENCL` 是否使用OpenCL后端,针对GPU设备
|
||||
- `MNN_METAL` 是否使用Metal后端,针对MacOS/iOSGPU设备
|
||||
- `MNN_VULKAN` 是否使用Vulkan后端,针对GPU设备
|
||||
- `MNN_CUDA` 是否使用CUDA后端,针对Nivida GPU设备
|
||||
- 其他编译选项可自行查看 CMakeLists.txt
|
||||
- 具体步骤
|
||||
### 具体步骤
|
||||
1. 准备工作 (可选,修改 MNN Schema 后需要)
|
||||
```bash
|
||||
cd /path/to/MNN
|
||||
|
|
@ -22,6 +22,15 @@
|
|||
```bash
|
||||
mkdir build && cd build && cmake .. && make -j8
|
||||
```
|
||||
### Mac M1 上编译
|
||||
- Mac M1 较为特殊的一点是作为过渡期间的芯片支持Arm/x64双架构,一般需要额外指定来获取需要的架构
|
||||
- 在 cmake 步骤增加 `-DCMAKE_OSX_ARCHITECTURES=arm64` 可以编译出 Arm 架构的库,对应地编译 x64 架构时加 `-DCMAKE_OSX_ARCHITECTURES=x86_64`:
|
||||
|
||||
```
|
||||
cd /path/to/MNN
|
||||
mkdir build && cd build && cmake .. -DCMAKE_OSX_ARCHITECTURES=arm64 && make -j8
|
||||
```
|
||||
|
||||
## Windows(非ARM架构)
|
||||
- 环境要求
|
||||
- Microsoft Visual Studio >= 2017
|
||||
|
|
@ -87,14 +96,23 @@
|
|||
mkdir build_64 && cd build_64 && ../build_64.sh
|
||||
```
|
||||
## iOS
|
||||
可基于脚本编译或者基于xcode工程编译
|
||||
|
||||
- 环境要求
|
||||
- xcode
|
||||
- cmake
|
||||
- 相关编译选项
|
||||
- `MNN_METAL` 是否使用Metal后端,Metal后端可以利用GPU加速
|
||||
- `MNN_COREML` 是否使用CoreML后端,CoreML后端可以利用ANE硬件加速
|
||||
- `MNN_ARM82` 是否支持fp16推理,开启该编译选项后,在precision设成Precision_Low时,会在支持的设备(ARMv8.2 及以上架构)上启用低精度(fp16)推理,减少内存占用,提升性能
|
||||
- 具体步骤
|
||||
- 在macOS下,用Xcode打开project/ios/MNN.xcodeproj,点击编译即可
|
||||
|
||||
- 基于 xcode 编译:用Xcode打开project/ios/MNN.xcodeproj,点击编译即可,工程中默认打开上述所有编译选项
|
||||
|
||||
- 基于脚本编译:运行脚本并开启`MNN_ARM82`选项
|
||||
```
|
||||
sh package_scripts/ios/buildiOS.sh "-DMNN_ARM82=true"
|
||||
```
|
||||
|
||||
## 其他平台交叉编译
|
||||
由于交叉编译的目标设备及厂商提供的编译环境类型众多,本文恕无法提供手把手教学。 以下是大致流程,请按照具体场景做相应修改。
|
||||
交叉编译大致上分为以下两个步骤,即获取交叉编译器以及配置CMake进行交叉编译。
|
||||
|
|
@ -137,3 +155,49 @@
|
|||
-DCMAKE_CXX_COMPILER=$cross_compile_toolchain/bin/aarch64-linux-gnu-g++
|
||||
make -j4
|
||||
```
|
||||
|
||||
## Web
|
||||
|
||||
- 可以把 MNN 源代码编译为 WebAssembly 以便在浏览器中使用
|
||||
|
||||
### 安装 emcc
|
||||
参考 https://emscripten.org/docs/getting_started/downloads.html ,安装完成后并激活,此时可使用 emcmake
|
||||
|
||||
### 编译(通用)
|
||||
- 使用 emcmake cmake 替代 cmake ,然后 make 即可:
|
||||
```
|
||||
mkdir build
|
||||
cd build
|
||||
emcmake cmake .. -DCMAKE_BUILD_TYPE=Release -DMNN_FORBID_MULTI_THREAD=ON -DMNN_USE_THREAD_POOL=OFF -DMNN_USE_SSE=OFF
|
||||
emmake make MNN -j16
|
||||
```
|
||||
|
||||
编译完成后产出 libMNN.a ,可在后续的 webassembly 程序中链接,链接时一般要添加 -s ALLOW_MEMORY_GROWTH=1 ,避免内存不足后 crash
|
||||
|
||||
### SIMD 支持
|
||||
|
||||
- 如果确认目标设备支持Web Simd ,在cmake时加上 -msimd128 -msse4.1 ,可以较大提升性能,eg:
|
||||
```
|
||||
mkdir build
|
||||
cd build
|
||||
emcmake cmake .. -DCMAKE_BUILD_TYPE=Release -DMNN_BUILD_TEST=true -DCMAKE_CXX_FLAGS="-msimd128 -msse4.1" -DMNN_FORBID_MULTI_THREAD=ON -DMNN_USE_THREAD_POOL=OFF -DMNN_USE_SSE=ON
|
||||
emmake make MNN -j16
|
||||
```
|
||||
|
||||
### 测试
|
||||
由于Web上文件系统不一致,建议只编译run_test.out运行,其他测试工具需要加上--preload-file {dir}
|
||||
|
||||
- 编译示例
|
||||
|
||||
```
|
||||
mkdir build
|
||||
cd build
|
||||
emcmake cmake .. -DCMAKE_BUILD_TYPE=Release -DMNN_BUILD_TEST=true -DCMAKE_CXX_FLAGS="-msimd128 -msse4.1 -s ALLOW_MEMORY_GROWTH=1" -DMNN_FORBID_MULTI_THREAD=ON -DMNN_USE_THREAD_POOL=OFF -DMNN_USE_SSE=ON
|
||||
emmake make -j16
|
||||
```
|
||||
|
||||
- 运行
|
||||
```
|
||||
node run_test.out.js speed/MatMulBConst //测试性能
|
||||
node run_test.out.js //测试功能
|
||||
```
|
||||
|
|
|
|||
|
|
@ -335,33 +335,22 @@ REGISTER_METAL_OP_CREATOR(MetalMyCustomOpCreator, OpType_MyCustomOp);
|
|||
重新运行一下 CMake ,或者手动在Xcode工程中新加文件
|
||||
|
||||
### 添加Vulkan实现
|
||||
1. 添加Shader
|
||||
在`source/backend/vulkan/execution/glsl`目录下添加具体的shader(*.comp)。若输入内存布局为`NC4HW4`,则按`image`实现,否则采用buffer实现。可以参考目录下已有实现。然后,执行`makeshader.py`脚本编译Shader。
|
||||
Vulkan后端当前包含两种张量存储类型:buffer与image。开发者可在编译时通过宏`MNN_VULKAN_IMAGE`自行选择需要的存储类型。当开发者需要为Vulkan后端添加算子时,亦需要考虑选择何种存储类型并在相应目录下进行开发。下以image类型为例,阐述为Vulkan后端添加算子的主要流程。
|
||||
|
||||
2. 实现类声明
|
||||
在目录`source/backend/vulkan/execution/`下添加`VulkanMyCustomOp.hpp`和`VulkanMyCustomOp.cpp`:
|
||||
```cpp
|
||||
class VulkanMyCustomOp : public VulkanBasicExecution {
|
||||
public:
|
||||
VulkanMyCustomOp(const Op* op, Backend* bn);
|
||||
virtual ~VulkanMyCustomOp();
|
||||
ErrorCode onEncode(const std::vector<Tensor*>& inputs,
|
||||
const std::vector<Tensor*>& outputs,
|
||||
const VulkanCommandPool::Buffer* cmdBuffer) override;
|
||||
private:
|
||||
// GPU Shader所需的参数
|
||||
std::shared_ptr<VulkanBuffer> mConstBuffer;
|
||||
// Pipeline
|
||||
const VulkanPipeline* mPipeline;
|
||||
// Layout Descriptor Set
|
||||
std::shared_ptr<VulkanPipeline::DescriptorSet> mDescriptorSet;
|
||||
};
|
||||
```
|
||||
|
||||
3. 实现
|
||||
实现函数`onEncode`,首先需要做内存布局检查:若为`NC4HW4`,则Shader用image实现,否则用buffer。执行完毕返回NO_ERROR。
|
||||
|
||||
4. 注册实现类
|
||||
1. 实现Execution
|
||||
- 执行脚本`source/backend/vulkan/image/compiler/VulkanCodeGen.py`,该脚本将向`source/backend/vulkan/image/execution`中添加`VulkanMyOp.hpp`与`VulkanMyOp.cpp`的模版代码
|
||||
- 实现构造函数
|
||||
- 从CPU中读取常量参数,并写入GPU中
|
||||
- 创建算子所需的pipeline
|
||||
- 确定要使用的shader以及Macro
|
||||
- set descriptorTypes,即确定shader中用到的显存对象的类型
|
||||
- 调用getPipeline接口
|
||||
- 实现onEncode
|
||||
- 显存资源申请并更新descriptorSet,将shader中需要读写的显存对象写入descriptorSet
|
||||
- 添加memoryBarrier
|
||||
- 把pipeline绑到cmdBuffer与descriptorSet
|
||||
- command dispatch
|
||||
- 注册算子并添加创建类
|
||||
```cpp
|
||||
class VulkanMyCustomOpCreator : public VulkanBackend::Creator {
|
||||
public:
|
||||
|
|
@ -377,6 +366,15 @@ static bool gResistor = []() {
|
|||
}();
|
||||
```
|
||||
|
||||
2. 实现shader及编译
|
||||
- 编写Compute Shader文件`myOp.comp`,添加至目录`source/backend/vulkan/image/execution/glsl`
|
||||
- 将算子中用到的宏加入`source/backend/vulkan/image/execution/glsl/macro.json`
|
||||
- 执行脚本`source/backend/vulkan/image/compiler/makeshader.py`,该脚本将编译`myOp.comp`,并更新`source/backend/vulkan/image/compiler/AllShader.cpp`、`source/backend/vulkan/image/shaders/AllShader.h`以及`source/backend/vulkan/image/compiler/VulkanShaderMap.cpp`
|
||||
> MNN Vulkan当前使用glslangValidator(glslang仓库地址:<https://github.com/KhronosGroup/glslang>,版本号:12.2.0,commit id:d1517d64cfca91f573af1bf7341dc3a5113349c0)编译所有的compute shader。开发者如需保持自行编译后得到的二进制编译结果与MNN仓库中现有的编译结果一致,需要确保环境中的glslang的版本与MNN所使用的一致。
|
||||
|
||||
|
||||
|
||||
|
||||
### 添加OpenCL实现
|
||||
1. 添加Kernel
|
||||
在`source/backend/opencl/execution/cl`目录添加具体的kernel(*.cl)。目前feature map均使用`image2d`实现。可以参考目录下已有实现。然后执行`opencl_codegen.py`来生成kernel映射。
|
||||
|
|
|
|||
15
docs/faq.md
15
docs/faq.md
|
|
@ -3,6 +3,8 @@
|
|||
- [模型转换后结果与其他框架不一致](faq.html#id8)
|
||||
- [compute shape error](faq.html#compute-shape-error-for-xxx)
|
||||
- [模型转换时有Error信息](faq.html#reshape-error)
|
||||
- [模型转换加上fp16没有性能提升](faq.html#fp16)
|
||||
- [如何开启动态量化](faq.html#weightquantbits)
|
||||
- [模型量化后为什么比浮点慢](faq.html#id14)
|
||||
- [输入输出的elementSize与实际有区别](faq.html#tensor-elementsize)
|
||||
- [MNN模型如何加密](faq.html#id18)
|
||||
|
|
@ -112,6 +114,14 @@ opConverter ==> MNN Converter NOT_SUPPORTED_OP: [ ANY_OP_NAME ]
|
|||
### 模型转换后与原框架结果不一致
|
||||
先使用MNN中的模型一致性验证脚本进行测试,确定不是调用方法或其他错误,[使用方法](./tools/convert.html#id3)
|
||||
|
||||
### 模型转换加上fp16后没有性能提升
|
||||
此功能只支持压缩模型数据,在运行时仍然先解压到float32运算。如果希望使用 fp16 加速,打开 `MNN_ARM82` 并在加载模型时设置 precision = low
|
||||
|
||||
### 模型转换加上weightQuantBits后如何进行加速
|
||||
可以通过动态量化功能,加载仅权重量化的模型,降低内存占用和提升性能
|
||||
1. 打开 `MNN_LOW_MEMORY` 编译宏编译 MNN (支持动态量化功能)
|
||||
2. 使用 mnn 模型时 memory 设成 low
|
||||
|
||||
## Pymnn
|
||||
### import MNN 出现 import numpy error
|
||||
临时解决方案:升级 numpy 版本到 1.20.0 或以上
|
||||
|
|
@ -169,10 +179,10 @@ const float* outputPtr = output->readMap<float>();
|
|||
|
||||
### Android 设备无法查看日志
|
||||
Android 系统有两类打印日志的方式: printf 和 logcat. 默认 MNN 的编译脚本使用 printf,这样方便在命令行中调试。集成到 App 上时,用 cmake -DMNN_USE_LOGCAT=ON 将打印日志的方式改成 logcat 即可用 adb logcat 查看
|
||||
###
|
||||
|
||||
### 如何增加 opencl so 地址?
|
||||
MNN opencl 后端默认采用 dlopen 的方式动态打开设备的 opencl 驱动,相应位置若找不到您设备上的驱动,请修改 **OpenCLWrapper.cpp**
|
||||
###
|
||||
|
||||
### TensorArray Op 与 Switch / Merge 控制流支持
|
||||
TensorArray 和控制流支持需要借助 MNN-Express ,
|
||||
请参考 demo/exec/transformerDemo.cpp 的接口使用
|
||||
|
|
@ -284,6 +294,7 @@ GPU 后端调用 copy 的时间包含两个部分
|
|||
- x64 + vnni 指令,量化计算有 sdot 指令,明显快于 FP32 ,编译 MNN 时需要开启 MNN_AVX512 以支持这个指令,一般相比 AVX512 的浮点运算快 30%
|
||||
- ARM v7a / ARMv8 :量化计算采用 int8 乘加到 int16,再双加到 int32 的方式,计算效率略快于浮点(一般 30% 左右提升)。
|
||||
- ARMv8.2 架构有 sdot 指令,但同时 FP32 相对之前架构发射数也提升了一倍,也支持了比 FP32 快一倍的 FP16 向量计算指令,MNN 会检查设备架构以开启 sdot / smmla ,理想情况下量化计算性能比 FP32 快1倍以上,比 FP16 快 20%。
|
||||
- ARMv8.6 架构有 smmla 指令,理想情况下量化计算性能比 FP32 快3倍以上,比 FP16 快1倍以上,比 BF16 快 20%。
|
||||
|
||||
## 其他问题
|
||||
### MNN模型如何加密
|
||||
|
|
|
|||
|
|
@ -58,7 +58,6 @@
|
|||
train/expr
|
||||
train/data
|
||||
train/optim
|
||||
train/quant
|
||||
train/finetune
|
||||
train/distl
|
||||
|
||||
|
|
@ -69,6 +68,7 @@
|
|||
|
||||
transformers/diffusion
|
||||
transformers/llm
|
||||
transformers/models
|
||||
|
||||
.. toctree::
|
||||
:maxdepth: 1
|
||||
|
|
@ -78,7 +78,6 @@
|
|||
tools/convert
|
||||
tools/test
|
||||
tools/benchmark
|
||||
tools/quant
|
||||
tools/compress
|
||||
tools/visual
|
||||
tools/python
|
||||
|
|
|
|||
|
|
@ -270,7 +270,16 @@ const std::map<std::string, Tensor*>& getSessionInputAll(const Session* session)
|
|||
|
||||
在只有一个输入tensor时,可以在调用`getSessionInput`时传入NULL以获取tensor。
|
||||
|
||||
### 拷贝数据
|
||||
### 【推荐】映射填充数据
|
||||
**映射输入Tensor的内存,部分后端可以免数据拷贝**
|
||||
```cpp
|
||||
auto input = interpreter->getSessionInput(session, NULL);
|
||||
void* host = input->map(MNN::Tensor::MAP_TENSOR_WRITE, input->getDimensionType());
|
||||
// fill host memory data
|
||||
input->unmap(MNN::Tensor::MAP_TENSOR_WRITE, input->getDimensionType(), host);
|
||||
```
|
||||
|
||||
### 【不推荐】拷贝填充数据
|
||||
NCHW示例,适用 ONNX / Caffe / Torchscripts 转换而来的模型:
|
||||
```cpp
|
||||
auto inputTensor = interpreter->getSessionInput(session, NULL);
|
||||
|
|
@ -293,7 +302,7 @@ delete nhwcTensor;
|
|||
通过这类拷贝数据的方式,用户只需要关注自己创建的tensor的数据布局,`copyFromHostTensor`会负责处理数据布局上的转换(如需)和后端间的数据拷贝(如需)。
|
||||
|
||||
|
||||
### 直接填充数据
|
||||
### 【不推荐】直接填充数据
|
||||
```cpp
|
||||
auto inputTensor = interpreter->getSessionInput(session, NULL);
|
||||
inputTensor->host<float>()[0] = 1.f;
|
||||
|
|
@ -549,8 +558,16 @@ const std::map<std::string, Tensor*>& getSessionOutputAll(const Session* session
|
|||
|
||||
**注意:当`Session`析构之后使用`getSessionOutput`获取的`Tensor`将不可用**
|
||||
|
||||
### 拷贝数据
|
||||
**不熟悉MNN源码的用户,必须使用这种方式获取输出!!!**
|
||||
### 【推荐】映射输出数据
|
||||
**映射输出Tensor的内存数据,部分后端可以免数据拷贝**
|
||||
```cpp
|
||||
auto outputTensor = net->getSessionOutput(session, NULL);
|
||||
void* host = outputTensor->map(MNN::Tensor::MAP_TENSOR_READ, outputTensor->getDimensionType());
|
||||
// use host memory by yourself
|
||||
outputTensor->unmap(MNN::Tensor::MAP_TENSOR_READ, outputTensor->getDimensionType(), host);
|
||||
```
|
||||
### 【不推荐】拷贝输出数据
|
||||
**采用纯内存拷贝的方式,拷贝需要花费时间**
|
||||
NCHW (适用于 Caffe / TorchScript / Onnx 转换而来的模型)示例:
|
||||
```cpp
|
||||
auto outputTensor = interpreter->getSessionOutput(session, NULL);
|
||||
|
|
@ -577,7 +594,7 @@ delete nhwcTensor;
|
|||
|
||||
|
||||
|
||||
### 直接读取数据
|
||||
### 【不推荐】直接读取数据
|
||||
**由于绝大多数用户都不熟悉MNN底层数据布局,所以不要使用这种方式!!!**
|
||||
```cpp
|
||||
auto outputTensor = interpreter->getSessionOutput(session, NULL);
|
||||
|
|
|
|||
|
|
@ -1,11 +1,13 @@
|
|||
# 模型压缩工具箱
|
||||
# 模型压缩 / 模型量化
|
||||
|
||||
## 介绍
|
||||
### 是什么?
|
||||
MNN模型压缩工具箱提供了包括低秩分解、剪枝、量化等模型压缩算法的实现,并且MNN进一步实现了其中一些需要软件特殊实现的算法(如稀疏计算和量化)的底层计算过程,因此,此工具箱需要配合MNN推理框架来使用。
|
||||
具体来说,MNN压缩工具箱包含两个组成部分:
|
||||
1. **MNN框架自身提供的压缩工具**(输入MNN模型,输出MNN模型)
|
||||
2. **mnncompress**(基于主流训练框架TF/Pytorch的模型压缩工具)。
|
||||
MNN模型压缩工具提供了包括低秩分解、剪枝、量化等模型压缩算法的实现,并且MNN进一步实现了其中一些需要软件特殊实现的算法(如稀疏计算和量化)的底层计算过程,因此,此工具箱需要配合MNN推理框架来使用。
|
||||
具体来说,MNN压缩工具/量化工具包含三个部分,使用复杂度逐步上升:
|
||||
1. **模型转换工具中的压缩功能**(只实现权值量化,在模型转换过程中增加参数即可实现)
|
||||
2. **离线量化工具**(实现权值量化及特征量化,需要少量测试数据)
|
||||
3. **mnncompress**(基于主流训练框架TF/Pytorch的模型压缩工具,需要训练数据和对应的训练框架环境)。
|
||||
|
||||
### 有什么?
|
||||
目前提供的能力如下表所示:
|
||||
|
||||
|
|
@ -26,64 +28,79 @@ MNN模型压缩工具箱提供了包括低秩分解、剪枝、量化等模型
|
|||
| 训练量化 | 将float卷积转换为int8卷积计算,需要进行训练,可提高量化模型精度,降低存储量到原始模型的四分之一,降低内存,加速计算(某些模型可能会比float模型慢,因为float的优化方法和int8不同) | LSQ,OAQ,WAQ |
|
||||
| 直接权值量化 | 仅将模型中的权值进行量化,计算时还原为float进行计算,因此仅减少模型存储量,计算速度和float相同,可以在模型转换时一键完成,8bit量化情况下,精度基本不变,模型大小减小到原来的1/4 | 对称量化,非对称量化 |
|
||||
| 训练权值量化 | 特点同直接权值量化,但通过mnncompress压缩算法插件实现,因而可以提供更低比特的权值量化,以减少更多的存储量,并提高权值量化之后模型的精度,例如4bit量化情况下,模型大小减小到原来的1/8 | 对称量化 |
|
||||
| FP16 | 将FP32计算转换为FP16计算,可在模型转换时一键完成,模型大小减小为原来的1/2,精度基本无损,并提高计算速度(需要硬件支持FP16计算) | - |
|
||||
| FP16 | 将FP32计算转换为FP16计算,可在模型转换时一键完成,模型大小减小为原来的1/2,精度基本无损 | - |
|
||||
|
||||
### 怎么用?
|
||||
1. 如果只想使用离线压缩方法,可以将模型转换为MNN模型之后使用对应的工具进行压缩。这类压缩算法不需要进行训练finetune,所以通常运行得很快。
|
||||
2. 如果离线压缩方法的精度不满足要求,且能够进行训练finetune的话,可以使用**mnncompress**中提供的压缩算法插件将原始模型进行压缩,得到压缩之后的模型和压缩信息描述文件,然后将这两个文件输入到MNN模型转换工具得到最终的MNN压缩模型。需要训练的压缩算法可以提供更好的精度,但需要一定的时间进行finetune训练,此finetune训练需要的时间一般比模型从0开始训练要少很多。
|
||||
3. 这些算法中有些是可以叠加使用的,以取得更好的压缩效果。推荐使用pipeline(**其中方框中的算法均为可选,叠加压缩算法若精度不好,可选择使用**):
|
||||
1. 使用模型转换工具中的压缩功能无需额外数据,只要在模型转换时加对应参数即可,开启动态量化功能后也可以对卷积等计算量大的算子实现量化加速。
|
||||
2. 使用离线量化可以使大部分算子支持量化加速,这个可以将模型转换为MNN模型之后使用离线量化工具进行压缩,需要少量测试数据,但不需要进行训练finetune,通常运行得很快。
|
||||
3. 如果离线压缩方法的精度不满足要求,且能够进行训练finetune的话,可以使用**mnncompress**中提供的压缩算法插件将原始模型进行压缩,得到压缩之后的模型和压缩信息描述文件,然后将这两个文件输入到MNN模型转换工具得到最终的MNN压缩模型。需要训练的压缩算法可以提供更好的精度,但需要一定的时间进行finetune训练,此finetune训练需要的时间一般比模型从0开始训练要少很多。
|
||||
4. 这些算法中有些是可以叠加使用的,以取得更好的压缩效果。推荐使用pipeline(**其中方框中的算法均为可选,叠加压缩算法若精度不好,可选择使用**):
|
||||

|
||||
|
||||
## MNN框架自身提供的压缩工具
|
||||
### 使用方法
|
||||
MNN框架压缩工具是基于离线量化工具和MNN转换工具来实现压缩功能的,这两个工具均提供c++版本和python版本,安装方式如下:
|
||||
## 使用模型转换工具的压缩功能
|
||||
|
||||
### 模型转换工具安装
|
||||
- c++工具安装
|
||||
|
||||
需要源码编译MNN转换工具 `MNNConvert` 和量化工具 `quantized.out`
|
||||
源码编译MNN转换工具 `MNNConvert`
|
||||
```bash
|
||||
cd build
|
||||
cmake .. -DMNN_BUILD_CONVERTER=ON -DMNN_BUILD_QUANTOOLS=ON
|
||||
cmake .. -DMNN_BUILD_CONVERTER=ON
|
||||
make -j8
|
||||
```
|
||||
- python工具安装
|
||||
```bash
|
||||
# 外部版本MNN,外网安装方式
|
||||
pip install MNN
|
||||
# 外部版本MNN,集团内安装方式
|
||||
pip install --index-url https://pypi.antfin-inc.com/simple/ -U MNN
|
||||
# 内部版本MNN
|
||||
pip install --index-url https://pypi.antfin-inc.com/simple/ -U MNN-Internal
|
||||
# 安装之后,命令行中将有如下工具:
|
||||
mnn:显示MNN命令行工具
|
||||
mnnconvert:转换器 MNNConvert 的预编译工具,功能同 MNNConvert
|
||||
mnnquant:量化工具 quantized.out 的预编译工具,功能同 quantized.out
|
||||
```
|
||||
### MNN离线量化工具
|
||||
#### 原理
|
||||
将float卷积转换为int8卷积进行计算(仅量化卷积,建议将FC转为1*1卷积实现),同时会通过MNN几何计算机制将量化信息在网络中进行传播,以支持尽可能多的算子的量化计算。模型大小减少为原始模型的1/4,并减少内存,提高推理速度(某些模型可能量化之后变慢,因为float的计算可以使用winograd、strassen等优化算法,而离线量化的int8计算并没有这些优化,如果要使用int8量化的特殊优化,如OAQ、WAQ等,需要使用mnncompress)。
|
||||
#### 单输入、图片输入模型的量化
|
||||
这类模型可以使用 `quantized.out`(或`mnnquant`)进行量化,使用文档在:[quantized.out](quant.md),[mnnquant.md](python.html#mnnquant)
|
||||
#### 通用模型的量化
|
||||
通用模型量化工具可以支持任意输入和任意输入类型的模型的量化,基于MNN python包,使用文档在:[MNNPythonOfflineQuant](https://github.com/alibaba/MNN/tree/master/tools/MNNPythonOfflineQuant)
|
||||
|
||||
**注意:**`calibration_dataset.py`中`__getitem__`返回为一个输入sample,其形状不应该包含batch维度,在量化时我们会根据工具命令行中传入的batch参数,stack出一个batch的数据,但我们默认batch维度在第一维,所以,如果你的某个输入的batch维不在第一维,你需要在你对应的输入之前加一个transpose。
|
||||
### MNN权值量化工具
|
||||
#### 原理
|
||||
仅将模型中卷积的float权值量化为int8存储,推理时反量化还原为float权值进行计算。因此,其推理速度和float模型一致,但是模型大小可以减小到原来的1/4,可以通过模型转换工具一键完成,比较方便。推荐float模型性能够用,仅需要减少模型大小的场景使用。
|
||||
#### 使用方法
|
||||
使用`MNNConvert`(c++)或者`mnnconvert`(python包中自带)进行转换,转换命令行中加上下述选项即可:
|
||||
### 权值量化
|
||||
- 仅将模型中卷积的float权值量化为int8存储,在不开启动态量化功能的情况下,推理时反量化还原为float权值进行计算。因此,其推理速度和float模型一致,但是模型大小可以减小到原来的1/4,可以通过模型转换工具一键完成,比较方便,推荐优先使用。
|
||||
- 使用`MNNConvert`(c++)或者`mnnconvert`(python包中自带)进行转换,转换命令行中加上下述选项即可:
|
||||
```bash
|
||||
--weightQuantBits 8 [--weightQuantAsymmetric](可选)
|
||||
--weightQuantBits 8 [--weightQuantAsymmetric](可选) [--weightQuantBlock 128](可选)
|
||||
```
|
||||
`--weightQuantAsymmetric` 选项是指使用非对称量化方法,精度要比默认的对称量化精度好一些。
|
||||
### MNN FP16压缩工具
|
||||
#### 原理
|
||||
将模型中FP32权值转换为FP16存储,并在支持的设备上开启FP16推理,可以获得推理加速,并且速度减少到原来的1/2。可以在模型转换时一键完成,使用方便。
|
||||
#### 使用方法
|
||||
使用`MNNConvert`(c++)或者`mnnconvert`(python包中自带)进行转换,转换命令行中加上下述选项即可:
|
||||
`--weightQuantBlock 128` 表示以128为单位进行量化,如不设置则以输入通道数为单位进行量化。如果牺牲一些存储大小来提升量化精度,可以增加这个设置,理论上越小精度越高,但建议不要低于32。
|
||||
- 动态量化
|
||||
可以通过如下方式打开MNN运行时的动态量化支持,使权值量化后的模型中卷积等核心算子使用量化计算,降低内存并提升性能
|
||||
1. 打开 MNN_LOW_MEMORY 编译宏编译 MNN (支持动态量化功能)
|
||||
2. 使用 mnn 模型时 memory mode 设成 low
|
||||
|
||||
### FP16压缩
|
||||
- 将模型中FP32权值转换为FP16存储,并在支持的设备上开启FP16推理,可以获得推理加速,并且速度减少到原来的1/2。可以在模型转换时一键完成,使用方便。
|
||||
- 使用`MNNConvert`(c++)或者`mnnconvert`(python包中自带)进行转换,转换命令行中加上下述选项即可:
|
||||
```bash
|
||||
--fp16
|
||||
```
|
||||
|
||||
## 离线量化工具
|
||||
### 离线量化工具安装
|
||||
- c++工具安装
|
||||
|
||||
需要源码编译量化工具 `quantized.out`
|
||||
```bash
|
||||
cd build
|
||||
cmake .. -DMNN_BUILD_QUANTOOLS=ON
|
||||
make -j8
|
||||
```
|
||||
- python工具安装
|
||||
```bash
|
||||
pip install MNN
|
||||
# 安装之后,命令行中将有如下工具:
|
||||
mnn:显示MNN命令行工具
|
||||
mnnconvert:转换器 MNNConvert 的预编译工具,功能同 MNNConvert
|
||||
mnnquant:量化工具 quantized.out 的预编译工具,功能同 quantized.out
|
||||
```
|
||||
|
||||
### 离线量化原理
|
||||
|
||||
将float卷积转换为int8卷积进行计算(仅量化卷积,建议将FC转为1*1卷积实现),同时会通过MNN几何计算机制将量化信息在网络中进行传播,以支持尽可能多的算子的量化计算。模型大小减少为原始模型的1/4,并减少内存,提高推理速度(某些模型可能量化之后变慢,因为float的计算可以使用winograd、strassen等优化算法,而离线量化的int8计算并没有这些优化,如果要使用int8量化的特殊优化,如OAQ、WAQ等,需要使用mnncompress)。
|
||||
可以使用 `quantized.out`(或`mnnquant`)进行量化,使用文档在:[quantized.out](quant.md),[mnnquant.md](python.html#mnnquant)
|
||||
|
||||
## mnncompress
|
||||
### 使用方法
|
||||
#### 安装
|
||||
|
|
|
|||
|
|
@ -31,7 +31,7 @@ Usage:
|
|||
--MNNModel arg 转换之后保存的MNN模型文件名, ex: *.mnn
|
||||
|
||||
--fp16 将conv/matmul/LSTM的float32参数保存为float16,
|
||||
模型将减小一半,精度基本无损
|
||||
模型将减小一半,精度基本无损,运行速度和float32模型一致
|
||||
|
||||
--bizCode arg MNN模型Flag, ex: MNN
|
||||
|
||||
|
|
@ -41,7 +41,7 @@ Usage:
|
|||
|
||||
--weightQuantBits arg arg=2~8,此功能仅对conv/matmul/LSTM的float32权值进行量化,
|
||||
仅优化模型大小,加载模型后会解码为float32,量化位宽可选2~8,
|
||||
运行速度和float32模型一致。8bit时精度基本无损,模型大小减小4倍
|
||||
不开启动态量化的情况下,运行速度和float32模型一致。8bit时精度基本无损,模型大小减小4倍
|
||||
default: 0,即不进行权值量化
|
||||
|
||||
--weightQuantAsymmetric 与weightQuantBits结合使用,决定是否用非对称量化,默认为`true`
|
||||
|
|
@ -77,7 +77,9 @@ Usage:
|
|||
--detectSparseSpeedUp arg
|
||||
可选值:{0, 1}, 默认为1, 会检测权重是否使用稀疏化加速
|
||||
|
||||
--saveExternalData 将权重,常量等数据存储在额外文件中,默认为`false`
|
||||
--saveExternalData 将权重,常量等数据存储在额外文件中,默认为0,也就是`false`
|
||||
|
||||
--useGeluApproximation 在进行Gelu算子合并时,使用Gelu的近似算法,默认为1 ,也就是`true`
|
||||
|
||||
```
|
||||
|
||||
|
|
|
|||
|
|
@ -1,9 +1,8 @@
|
|||
# 单输入模型离线量化工具
|
||||
# 离线量化工具(输入少量数据量化)
|
||||
`./quantized.out origin.mnn quan.mnn imageInputConfig.json`
|
||||
|
||||
MNN quantized.out工具已支持通用(任意输入个数、维度、类型)模型离线量化, 但这里的多输入模型仅仅支持非图片输入类模型。
|
||||
|
||||
MNN现已推出基于TensorFlow/Pytorch的模型压缩工具mnncompress,请查看[文档](https://mnn-docs.readthedocs.io/en/latest/tools/compress.html)选择使用
|
||||
|
||||
## 参数
|
||||
- 第一个参数为原始模型文件路径,即待量化的浮点模
|
||||
|
|
@ -31,7 +30,7 @@ MNN现已推出基于TensorFlow/Pytorch的模型压缩工具mnncompress,请查
|
|||
|--------------------|------|
|
||||
| KL | 使用KL散度进行特征量化系数的校正,一般需要100 ~ 1000张图片(若发现精度损失严重,可以适当增减样本数量,特别是检测/对齐等回归任务模型,样本建议适当减少) |
|
||||
| ADMM | 使用ADMM(Alternating Direction Method of Multipliers)方法进行特征量化系数的校正,一般需要一个batch的数据 |
|
||||
| EMA | 使用指数滑动平均来计算特征量化参数,这个方法会对特征进行非对称量化,精度可能比上面两种更好。这个方法也是[MNNPythonOfflineQuant](https://github.com/alibaba/MNN/tree/master/tools/MNNPythonOfflineQuant)的底层方法,建议使用这个方法量化时,保留你pb或onnx模型中的BatchNorm,并使用 --forTraining 将你的模型转到MNN,然后基于此带BatchNorm的模型使用EMA方法量化。另外,使用这个方法时batch size应设置为和训练时差不多最好。 |
|
||||
| EMA | 使用指数滑动平均来计算特征量化参数,这个方法会对特征进行非对称量化,精度可能比上面两种更好。使用这个方法时batch size应设置为和训练时差不多最好。|
|
||||
|
||||
| weight_quantize_method | 说明 |
|
||||
|--------------------|------|
|
||||
|
|
@ -39,10 +38,12 @@ MNN现已推出基于TensorFlow/Pytorch的模型压缩工具mnncompress,请查
|
|||
| ADMM | 使用ADMM方法进行权值量化 |
|
||||
|
||||
## 多输入模型的参数设置的特别说明(MNN现阶段仅支持输入数据类型是非图片的多输入模型)
|
||||
|
||||
| 需要特别指定的参数 | 设置值 |
|
||||
|--------------------|------|
|
||||
| input_type | `str`:输入数据的类型,"sequence" |
|
||||
| path | `str`:存放校正特征量化系数的输入数据目录 |,
|
||||
| path | `str`:存放校正特征量化系数的输入数据目录 |
|
||||
|
||||
例如在quant.json文件中 "path": "/home/data/inputs_dir/",你所构造的矫正数据集有两个,分别存放在input_0和input_1子目录下,即"/home/data/inputs_dir/input_0"和"/home/data/inputs_dir/input_1".由GetMNNInfo工具可以得到模型的输入输出名称,例如该模型的输入有三个:data0, data1, data2,输出有两个:out1, out2. 那么在input_0和input_1子目录下分别有六个文件:data0.txt, data1.txt, data2.txt, out1.txt, out2.txt, input.json. 其中的五个文件名要和模型的输入输出名对应,最后一个input.json文件则描述的是输入名和对应的shape内容:
|
||||
```json
|
||||
{
|
||||
|
|
|
|||
|
|
@ -32,7 +32,7 @@ Model Version: < 2.0.0
|
|||
- `runMask:int` 是否输出推理中间结果,0为不输出,1为只输出每个算子的输出结果({op_name}.txt);2为输出每个算子的输入(Input_{op_name}.txt)和输出({op_name}.txt)结果; 默认输出当前目录的output目录下(使用工具之前要自己建好output目录); 16为开启自动选择后端;32为针对Winograd算法开启内存优化模式,开启后会降低模型(如果含有Winograd Convolution算子)运行时的内存但可能会导致算子的性能损失。可选,默认为`0`
|
||||
- `forwardType:int` 执行推理的计算设备,有效值为:0(CPU)、1(Metal)、2(CUDA)、3(OpenCL)、6(OpenGL),7(Vulkan) ,9 (TensorRT),可选,默认为`0`
|
||||
- `numberThread:int` 线程数仅对CPU有效,可选,默认为`4`
|
||||
- `precision_memory:int` 测试精度与内存模式,precision_memory % 16 为精度,有效输入为:0(Normal), 1(High), 2(Low), 3(Low_BF16),可选,默认为`2` ; precision_memory / 16 为内存设置,默认为 0 (memory_normal) 。例如测试 memory 为 low (2) ,precision 为 1 (high) 时,设置 precision_memory = 9 (2 * 4 + 1)
|
||||
- `precision_memory:int` 测试精度与内存模式,precision_memory % 4 为精度,有效输入为:0(Normal), 1(High), 2(Low), 3(Low_BF16),可选,默认为`2` ; (precision_memory / 4) % 4 为内存设置,默认为 0 (memory_normal) 。例如测试 memory 为 low (2) ,precision 为 1 (high) 时,设置 precision_memory = 9 (2 * 4 + 1)
|
||||
- `inputSize:str` 输入tensor的大小,输入格式为:`1x3x224x224`,可选,默认使用模型默认输入
|
||||
|
||||
|
||||
|
|
@ -480,7 +480,7 @@ GPU 内存输入测试用例
|
|||
- `testmode:int` 默认为 0 ,测试输入GPU内存的类型,0 (OpenCL Buffer) 、 1(OpenGL Texture)
|
||||
- `forwardType:int` 执行推理的计算设备,有效值为:0(CPU)、1(Metal)、2(CUDA)、3(OpenCL)、6(OpenGL),7(Vulkan) ,9 (TensorRT),可选,默认为`0`
|
||||
- `numberThread:int` GPU的线程数,可选,默认为`1`
|
||||
- `precision_memory:int` 测试精度与内存模式,precision_memory % 16 为精度,有效输入为:0(Normal), 1(High), 2(Low), 3(Low_BF16),可选,默认为`2` ; precision_memory / 16 为内存设置,默认为 0 (memory_normal) 。例如测试 memory 为 2(low) ,precision 为 1 (high) 时,设置 precision_memory = 9 (2 * 4 + 1)
|
||||
- `precision_memory:int` 测试精度与内存模式,precision_memory % 4 为精度,有效输入为:0(Normal), 1(High), 2(Low), 3(Low_BF16),可选,默认为`0` ; (precision_memory / 4) % 4 为内存设置,默认为 0 (memory_normal) 。 (precision_memory / 16) % 4 为功耗设置,默认为0(power_normal)。例如测试 memory 为 2(low) ,precision 为 1 (high) 时,设置 precision_memory = 9 (2 * 4 + 1)
|
||||
|
||||
|
||||
## 在Android中使用测试工具
|
||||
|
|
|
|||
|
|
@ -1,100 +0,0 @@
|
|||
# 训练量化
|
||||
## 什么是训练量化
|
||||
与离线量化不同,训练量化需要在训练中模拟量化操作的影响,并通过训练使得模型学习并适应量化操作所带来的误差,从而提高量化的精度。因此训练量化也称为Quantization-aware Training(QAT),意指训练中已经意识到此模型将会转换成量化模型。
|
||||
|
||||
## 如何在MNN中使用训练量化
|
||||
已经通过其他训练框架如TensorFlow、Pytorch等训练得到一个float模型,此时可以通过先将此float模型通过MNNConverter转换为MNN统一的模型格式,然后使用MNN提供的离线量化工具直接量化得到一个全int8推理模型。如果此模型的精度不满足要求,则可以通过训练量化来提高量化模型的精度。
|
||||
|
||||
使用步骤:
|
||||
1. 首先通过其他训练框架训练得到原始float模型;
|
||||
2. 编译MNNConverter模型转换工具;
|
||||
3. 使用MNNConverter将float模型转成MNN统一格式模型,因为要进行再训练,建议保留BN,Dropout等训练过程中会使用到的算子,这可以通过MNNConverter的 --forTraining 选项实现;
|
||||
4. 参考MNN_ROOT/tools/train/source/demo/mobilenetV2Train.cpp 中的 MobilenetV2TrainQuant demo来实现训练量化的功能,下面以MobilenetV2的训练量化为例,来看一下如何读取并将模型转换成训练量化模型
|
||||
5. 观察准确率变化,代码保存下来的模型即为量化推理模型
|
||||
```cpp
|
||||
// mobilenetV2Train.cpp
|
||||
// 读取转换得到的MNN float模型
|
||||
auto varMap = Variable::loadMap(argv[1]);
|
||||
if (varMap.empty()) {
|
||||
MNN_ERROR("Can not load model %s\n", argv[1]);
|
||||
return 0;
|
||||
}
|
||||
// 指定量化比特数
|
||||
int bits = 8;
|
||||
if (argc > 6) {
|
||||
std::istringstream is(argv[6]);
|
||||
is >> bits;
|
||||
}
|
||||
if (1 > bits || bits > 8) {
|
||||
MNN_ERROR("bits must be 2-8, use 8 default\n");
|
||||
bits = 8;
|
||||
}
|
||||
// 获得模型的输入和输出
|
||||
auto inputOutputs = Variable::getInputAndOutput(varMap);
|
||||
auto inputs = Variable::mapToSequence(inputOutputs.first);
|
||||
auto outputs = Variable::mapToSequence(inputOutputs.second);
|
||||
|
||||
// 扫描整个模型,并将inference模型转换成可训练模型,此时得到的模型是可训练的float模型
|
||||
std::shared_ptr<Module> model(PipelineModule::extract(inputs, outputs, true));
|
||||
// 将上面得到的模型转换成训练量化模型,此处指定量化bit数
|
||||
PipelineModule::turnQuantize(model.get(), bits);
|
||||
// 进行训练,观察训练结果,保存得到的模型即是量化模型
|
||||
MobilenetV2Utils::train(model, 1001, 1, trainImagesFolder, trainImagesTxt, testImagesFolder, testImagesTxt);
|
||||
```
|
||||
## MNN训练量化原理
|
||||
MNN训练量化的基本原理如下图所示
|
||||
|
||||
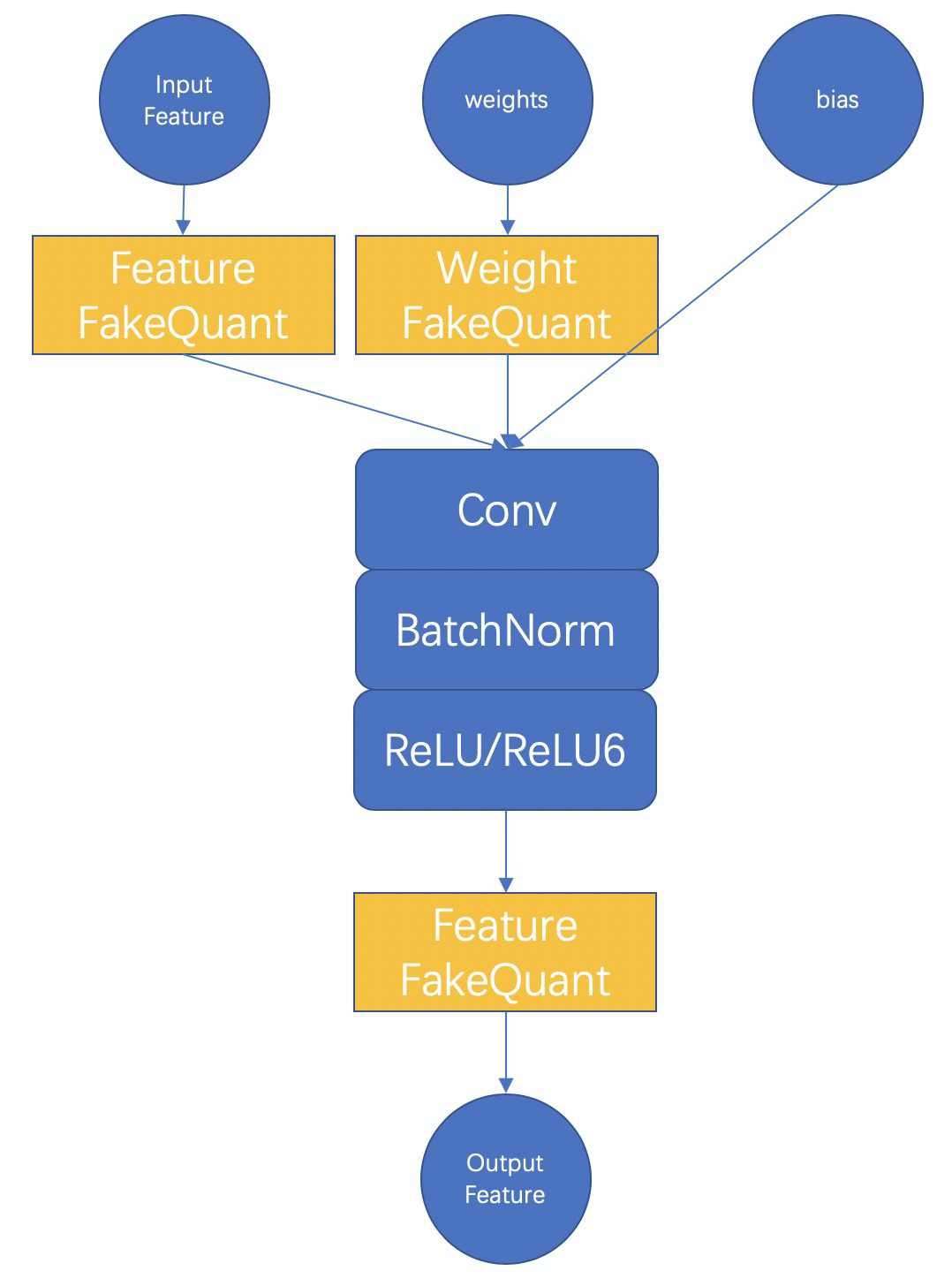
以int8量化为例,首先要理解全int8推理的整个过程,全int8推理,即feature要量化为int8,weight和bias也要量化为int8,输出结果可以是float或者是int8,视该卷积模块的后面一个op的情况而定。而训练量化的本质就是在训练的过程中去模拟量化操作的影响,借由训练来使得模型学习并适应这种影响,以此来提高最后量化模型的准确率。
|
||||
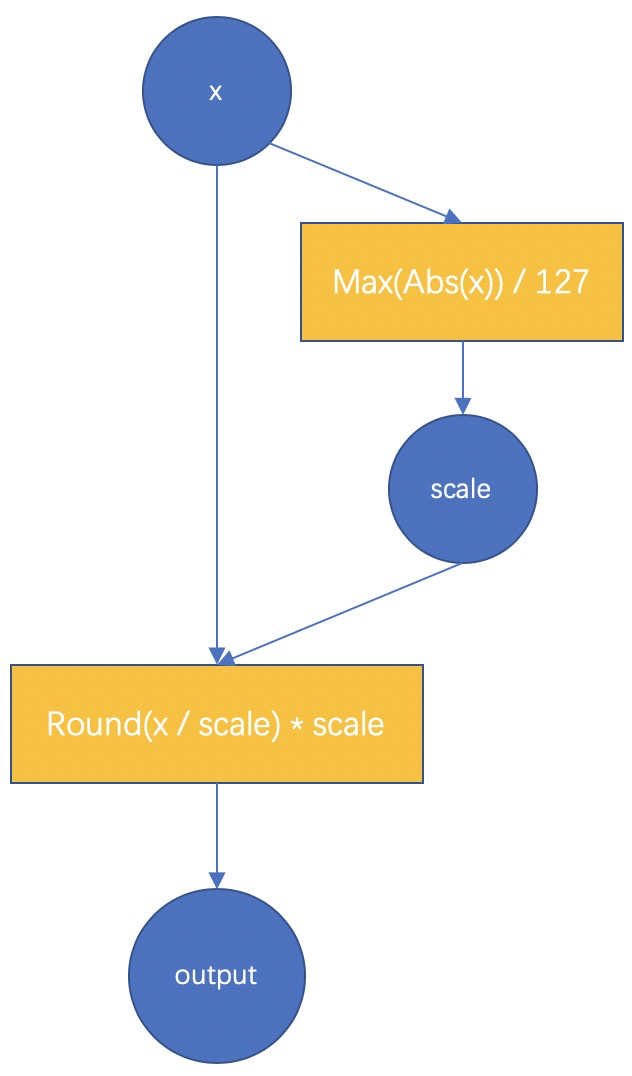
因此在两种 FakeQuant 模块中,我们的主要计算为
|
||||
|
||||
对于权值和特征的fake-quant基本都和上图一致,不一样的是对于特征由于其范围是随输入动态变化的,而最终int8模型中必须固定一个对于输入特征的scale值,所以,我们对每一此前向计算出来的scale进行了累积更新,例如使用滑动平均,或者直接取每一次的最大值。对于权值的scale,则没有进行平均,因为每一次更新之后的权值都是学习之后的较好的结果,没有状态保留。
|
||||
此外,对于特征,我们提供了分通道(PerChannel)或者不分通道(PerTensor)的scale统计方法,可根据效果选择使用。对于权值,我们则使用分通道的量化方法,效果较好。
|
||||
|
||||
上述是在训练中的training阶段的计算过程,在test阶段,我们会将BatchNorm合进权值,使用训练过程得到的特征scale和此时权值的scale(每次重新计算得到)对特征和权值进行量化,并真实调用MNN中的 _FloatToInt8 和 _Int8ToFloat 来进行推理,以保证测试得到的结果和最后转换得到的全int8推理模型的结果一致。
|
||||
|
||||
最后保存模型的时候会自动保存test阶段的模型,并去掉一些冗余的算子,所以直接保存出来即是全int8推理模型。
|
||||
|
||||
## 训练量化结果
|
||||
目前我们在Lenet,MobilenetV2,以及内部的一些人脸模型上进行了测试,均取得了不错的效果,下面给出MobilenetV2的一些详细数据
|
||||
|
||||
| | 准确率 / 模型大小 |
|
||||
| --- | --- |
|
||||
| 原始float模型 | 72.324% / 13M |
|
||||
| MNN训练量化int8模型 | 72.456% / 3.5M |
|
||||
| TF训练量化int8模型 | 71.1% / 3.5M (原始 71.8% / 13M) |
|
||||
|
||||
|
||||
上述数据是使用batchsize为32,训练100次迭代得到的,即仅使用到了3200张图片进行训练量化,在ImageNet验证集5万张图片上进行测试得到。可以看到int8量化模型的准确率甚至比float还要高一点,而模型大小下降了73%,同时还可以得到推理速度上的增益。
|
||||
|
||||
【注】此处使用到的float模型为TensorFlow官方提供的模型,但官方给出的准确率数据是71.8%,我们测出来比他们要高一点,原因是因为我们使用的预处理代码上有细微差别所致。
|
||||
|
||||
## 使用训练量化的一些建议
|
||||
|
||||
1. 模型转换时保留BatchNorm和Dropout等训练中会用到的算子,这些算子对训练量化也有帮助
|
||||
2. 要使用原始模型接近收敛阶段的训练参数,训练参数不对,将导致训练量化不稳定
|
||||
3. 学习率要调到比较小
|
||||
4. 我们仅对卷积层实现了训练量化,因此如果用MNN从零开始搭建模型,后期接训练量化,或者Finetune之后想继续训练量化,那么需要用卷积层来实现全连接层即可对全连接层也进行训练量化。示例代码如下
|
||||
```cpp
|
||||
// 用卷积层实现输入1280,输出为4的全连接层
|
||||
NN::ConvOption option;
|
||||
option.channel = {1280, 4};
|
||||
mLastConv = std::shared_ptr<Module>(NN::Conv(option));
|
||||
```
|
||||
|
||||
## 训练量化的配置选项
|
||||
详见 MNN_ROOT/tools/train/source/module/PipelineModule.hpp
|
||||
```cpp
|
||||
// 特征scale的计算方法
|
||||
enum FeatureScaleStatMethod {
|
||||
PerTensor = 0, // 对特征不分通道进行量化
|
||||
PerChannel = 1 // 对特征分通道进行量化,deprecated
|
||||
};
|
||||
// 特征scale的更新方法
|
||||
enum ScaleUpdateMethod {
|
||||
Maximum = 0, // 使用每一次计算得到的scale的最大值
|
||||
MovingAverage = 1 // 使用滑动平均来更新
|
||||
};
|
||||
// 指定训练量化的bit数,特征scale的计算方法,特征scale的更新方法,
|
||||
void toTrainQuant(const int bits = 8, NN::FeatureScaleStatMethod featureScaleStatMethod = NN::PerTensor,
|
||||
NN::ScaleUpdateMethod scaleUpdateMethod = NN::MovingAverage);
|
||||
```
|
||||
|
|
@ -2,9 +2,9 @@
|
|||
|
||||
## 模型支持与下载
|
||||
|
||||
1. runwayml/stable-diffusion-v1-5
|
||||
1. stable-diffusion-v1-5
|
||||
```
|
||||
https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
|
||||
https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5/tree/main
|
||||
```
|
||||
2. chilloutmix
|
||||
```
|
||||
|
|
|
|||
|
|
@ -0,0 +1,50 @@
|
|||
# 模型下载
|
||||
|
||||
## 大语言模型
|
||||
|
||||
| Model | ModelScope | Hugging Face |
|
||||
| -------- | ----------- | ------------ |
|
||||
| [Qwen-VL-Chat](https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen-VL-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen-VL-Chat-MNN) |
|
||||
| [Baichuan2-7B-Chat](https://modelscope.cn/models/baichuan-inc/Baichuan2-7B-Chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/Baichuan2-7B-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Baichuan2-7B-Chat-MNN) |
|
||||
| [bge-large-zh](https://modelscope.cn/models/AI-ModelScope/bge-large-zh/summary) | [Q4_1](https://modelscope.cn/models/MNN/bge-large-zh-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/bge-large-zh-MNN) |
|
||||
| [chatglm-6b](https://modelscope.cn/models/ZhipuAI/ChatGLM-6B/summary) | [Q4_1](https://modelscope.cn/models/MNN/chatglm-6b-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/chatglm-6b-MNN) |
|
||||
| [chatglm2-6b](https://modelscope.cn/models/ZhipuAI/chatglm2-6b/summary) | [Q4_1](https://modelscope.cn/models/MNN/chatglm2-6b-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/chatglm2-6b-MNN) |
|
||||
| [chatglm3-6b](https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary) | [Q4_1](https://modelscope.cn/models/MNN/chatglm3-6b-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/chatglm3-6b-MNN) |
|
||||
| [codegeex2-6b](https://modelscope.cn/models/MNN/codegeex2-6b-MNN/summary) | [Q4_1](https://modelscope.cn/models/MNN/codegeex2-6b-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/codegeex2-6b-MNN) |
|
||||
| [deepseek-llm-7b-chat](https://modelscope.cn/models/deepseek-ai/deepseek-llm-7b-chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/deepseek-llm-7b-chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/deepseek-llm-7b-chat-MNN) |
|
||||
| [gemma-2-2b-it](https://modelscope.cn/models/llm-research/gemma-2-2b-it) | [Q4_1](https://modelscope.cn/models/MNN/gemma-2-2b-it-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/gemma-2-2b-it-MNN) |
|
||||
| [glm-4-9b-chat](https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/glm-4-9b-chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/glm-4-9b-chat-MNN) |
|
||||
| [gte_sentence-embedding_multilingual-base](https://modelscope.cn/models/iic/gte_sentence-embedding_multilingual-base/summary) | [Q4_1](https://modelscope.cn/models/MNN/gte_sentence-embedding_multilingual-base-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/gte_sentence-embedding_multilingual-base-MNN) |
|
||||
| [internlm-chat-7b](https://modelscope.cn/models/AI-ModelScope/internlm-chat-7b/summary) | [Q4_1](https://modelscope.cn/models/MNN/internlm-chat-7b-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/internlm-chat-7b-MNN) |
|
||||
| [Llama-2-7b-chat](https://modelscope.cn/models/modelscope/Llama-2-7b-chat-ms/summary) | [Q4_1](https://modelscope.cn/models/MNN/Llama-2-7b-chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Llama-2-7b-chat-MNN) |
|
||||
| [Llama-3-8B-Instruct](https://modelscope.cn/models/modelscope/Meta-Llama-3-8B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Llama-3-8B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Llama-3-8B-Instruct-MNN) |
|
||||
| [Llama-3.2-1B-Instruct](https://modelscope.cn/models/LLM-Research/Llama-3.2-1B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Llama-3.2-1B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Llama-3.2-1B-Instruct-MNN) |
|
||||
| [Llama-3.2-3B-Instruct](https://modelscope.cn/models/LLM-Research/Llama-3.2-3B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Llama-3.2-3B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Llama-3.2-3B-Instruct-MNN) |
|
||||
| [OpenELM-1_1B-Instruct](https://huggingface.co/apple/OpenELM-1_1B-Instruct) | [Q4_1](https://modelscope.cn/models/MNN/OpenELM-1_1B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/OpenELM-1_1B-Instruct-MNN) |
|
||||
| [OpenELM-270M-Instruct](https://huggingface.co/apple/OpenELM-270M-Instruct) | [Q4_1](https://modelscope.cn/models/MNN/OpenELM-270M-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/OpenELM-270M-Instruct-MNN) |
|
||||
| [OpenELM-3B-Instruct](https://huggingface.co/apple/OpenELM-3B-Instruct) | [Q8_1](https://modelscope.cn/models/MNN/OpenELM-3B-Instruct-MNN) | [Q8_1](https://huggingface.co/taobao-mnn/OpenELM-3B-Instruct-MNN) |
|
||||
| [OpenELM-450M-Instruct](https://huggingface.co/apple/OpenELM-450M-Instruct) | [Q4_1](https://modelscope.cn/models/MNN/OpenELM-450M-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/OpenELM-450M-Instruct-MNN) |
|
||||
| [phi-2](https://modelscope.cn/models/mengzhao/phi-2/summary) | [Q4_1](https://modelscope.cn/models/MNN/phi-2-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/phi-2-MNN) |
|
||||
| [qwen/Qwen-1_8B-Chat](https://modelscope.cn/models/qwen/Qwen-1_8B-Chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen-1_8B-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen-1_8B-Chat-MNN) |
|
||||
| [Qwen-7B-Chat](https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen-7B-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen-7B-Chat-MNN) |
|
||||
| [Qwen1.5-0.5B-Chat](https://modelscope.cn/models/qwen/Qwen1.5-0.5B-Chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen1.5-0.5B-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen1.5-0.5B-Chat-MNN) |
|
||||
| [Qwen1.5-1.8B-Chat](https://modelscope.cn/models/qwen/Qwen1.5-1.8B-Chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen1.5-1.8B-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen1.5-1.8B-Chat-MNN) |
|
||||
| [Qwen1.5-4B-Chat](https://modelscope.cn/models/qwen/Qwen1.5-4B-Chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen1.5-4B-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen1.5-4B-Chat-MNN) |
|
||||
| [Qwen1.5-7B-Chat](https://modelscope.cn/models/qwen/Qwen1.5-7B-Chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen1.5-7B-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen1.5-7B-Chat-MNN) |
|
||||
| [Qwen2-0.5B-Instruct](https://modelscope.cn/models/qwen/Qwen2-0.5B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2-0.5B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2-0.5B-Instruct-MNN) |
|
||||
| [Qwen2-1.5B-Instruct](https://modelscope.cn/models/qwen/Qwen2-1.5B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2-1.5B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2-1.5B-Instruct-MNN) |
|
||||
| [Qwen2-7B-Instruct](https://modelscope.cn/models/qwen/Qwen2-7B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2-7B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2-7B-Instruct-MNN) |
|
||||
| [Qwen2-VL-2B-Instruct](https://modelscope.cn/models/qwen/Qwen2-VL-2B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2-VL-2B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2-VL-2B-Instruct-MNN) |
|
||||
| [Qwen2-VL-7B-Instruct](https://modelscope.cn/models/qwen/Qwen2-VL-7B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2-VL-7B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2-VL-7B-Instruct-MNN) |
|
||||
| [Qwen2.5-0.5B-Instruct](https://modelscope.cn/models/qwen/Qwen2.5-0.5B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2.5-0.5B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2.5-0.5B-Instruct-MNN) |
|
||||
| [Qwen2.5-1.5B-Instruct](https://modelscope.cn/models/qwen/Qwen2.5-1.5B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2.5-1.5B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2.5-1.5B-Instruct-MNN) |
|
||||
| [Qwen2.5-3B-Instruct](https://modelscope.cn/models/qwen/Qwen2.5-3B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2.5-3B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2.5-3B-Instruct-MNN) |
|
||||
| [Qwen2.5-7B-Instruct](https://modelscope.cn/models/qwen/Qwen2.5-7B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2.5-7B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2.5-7B-Instruct-MNN) |
|
||||
| [Qwen2.5-Coder-1.5B-Instruct](https://modelscope.cn/models/qwen/Qwen2.5-Coder-1.5B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2.5-Coder-1.5B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2.5-Coder-1.5B-Instruct-MNN) |
|
||||
| [Qwen2.5-Coder-7B-Instruct](https://modelscope.cn/models/qwen/Qwen2.5-Coder-7B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2.5-Coder-7B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2.5-Coder-7B-Instruct-MNN) |
|
||||
| [Qwen2.5-Math-1.5B-Instruct](https://modelscope.cn/models/qwen/Qwen2.5-Math-1.5B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2.5-Math-1.5B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2.5-Math-1.5B-Instruct-MNN) |
|
||||
| [Qwen2.5-Math-7B-Instruct](https://modelscope.cn/models/qwen/Qwen2.5-Math-7B-Instruct/summary) | [Q4_1](https://modelscope.cn/models/MNN/Qwen2.5-Math-7B-Instruct-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Qwen2.5-Math-7B-Instruct-MNN) |
|
||||
| [reader-lm-0.5b](https://huggingface.co/jinaai/reader-lm-0.5b) | [Q4_1](https://modelscope.cn/models/MNN/reader-lm-0.5b-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/reader-lm-0.5b-MNN) |
|
||||
| [reader-lm-1.5b](https://huggingface.co/jinaai/reader-lm-1.5b) | [Q4_1](https://modelscope.cn/models/MNN/reader-lm-1.5b-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/reader-lm-1.5b-MNN) |
|
||||
| [TinyLlama-1.1B-Chat-v1.0](https://modelscope.cn/models/AI-ModelScope/TinyLlama-1.1B-Chat-v1.0/summary) | [Q4_1](https://modelscope.cn/models/MNN/TinyLlama-1.1B-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/TinyLlama-1.1B-Chat-MNN) |
|
||||
| [Yi-6B-Chat](https://modelscope.cn/models/01ai/Yi-6B-Chat/summary) | [Q4_1](https://modelscope.cn/models/MNN/Yi-6B-Chat-MNN) | [Q4_1](https://huggingface.co/taobao-mnn/Yi-6B-Chat-MNN) |
|
||||
|
|
@ -41,6 +41,11 @@ void Executor::setGlobalExecutorConfig(MNNForwardType type, const BackendConfig&
|
|||
}
|
||||
MNN_ASSERT(nullptr != rt);
|
||||
mAttr->firstType = type;
|
||||
// Cache threadnumber and config
|
||||
mAttr->numThread = numberThread;
|
||||
mAttr->config = config;
|
||||
// Remove sharedContext because it's not used for create backend
|
||||
mAttr->config.sharedContext = nullptr;
|
||||
}
|
||||
|
||||
int Executor::getCurrentRuntimeStatus(RuntimeStatus statusEnum) {
|
||||
|
|
@ -219,6 +224,11 @@ void Executor::RuntimeManager::setMode(Interpreter::SessionMode mode) {
|
|||
}
|
||||
void Executor::RuntimeManager::setHint(Interpreter::HintMode mode, int value) {
|
||||
mInside->modes.setHint(mode, value);
|
||||
auto current = ExecutorScope::Current();
|
||||
auto rt = current->getRuntime();
|
||||
for (auto& iter : rt.first) {
|
||||
iter.second->setRuntimeHint(mInside->modes.runtimeHint);
|
||||
}
|
||||
}
|
||||
void Executor::RuntimeManager::setExternalPath(std::string path, int type) {
|
||||
mInside->modes.setExternalPath(path, type);
|
||||
|
|
|
|||
|
|
@ -91,6 +91,7 @@ bool VARP::fix(VARP::InputType type) const {
|
|||
newVARP->expr().first->inside()->mHoldBackend = pipelineInfo.first.cache.second;
|
||||
}
|
||||
Variable::replace(VARP(mContent), newVARP);
|
||||
inputTensor->wait(MNN::Tensor::MAP_TENSOR_READ, true);
|
||||
return true;
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -25,6 +25,8 @@ struct RuntimeAttr {
|
|||
struct ExecutorAttr {
|
||||
std::shared_ptr<Backend> constantBackend;
|
||||
MNNForwardType firstType;
|
||||
int numThread = 1;
|
||||
BackendConfig config;
|
||||
std::string externalFile;
|
||||
};
|
||||
};
|
||||
|
|
|
|||
|
|
@ -13,6 +13,7 @@
|
|||
#include <MNN/expr/ExecutorScope.hpp>
|
||||
#include "MNN_generated.h"
|
||||
#include "core/TensorUtils.hpp"
|
||||
#include "core/OpCommonUtils.hpp"
|
||||
#include "core/Session.hpp"
|
||||
#include "core/MNNMemoryUtils.h"
|
||||
#include "core/Backend.hpp"
|
||||
|
|
@ -61,19 +62,7 @@ int Utils::convertFormat(Dimensionformat format) {
|
|||
}
|
||||
|
||||
DataType Utils::convertDataType(halide_type_t type) {
|
||||
if (type.code == halide_type_float) {
|
||||
return DataType_DT_FLOAT;
|
||||
}
|
||||
if (type.code == halide_type_uint && type.bits == 8) {
|
||||
return DataType_DT_UINT8;
|
||||
}
|
||||
if (type.code == halide_type_int && type.bits == 8) {
|
||||
return DataType_DT_INT8;
|
||||
}
|
||||
if (type.code == halide_type_int && type.bits == 32) {
|
||||
return DataType_DT_INT32;
|
||||
}
|
||||
return DataType_DT_INVALID;
|
||||
return OpCommonUtils::convertDataType(type);
|
||||
}
|
||||
halide_type_t Utils::revertDataType(DataType dataType) {
|
||||
CONVERT(DataType_DT_FLOAT, halide_type_of<float>(), dataType);
|
||||
|
|
|
|||
|
|
@ -32,8 +32,10 @@ static MNN::Express::Executor::RuntimeManager* _createDefaultRuntimeManager(cons
|
|||
sche_config.backendConfig = config->backend->config;
|
||||
} else {
|
||||
auto exe = ExecutorScope::Current();
|
||||
sche_config.type = exe->getAttr()->firstType;
|
||||
sche_config.numThread = 1;
|
||||
auto attr = exe->getAttr();
|
||||
sche_config.type = attr->firstType;
|
||||
sche_config.numThread = attr->numThread;
|
||||
sche_config.backendConfig = &attr->config;
|
||||
}
|
||||
return Executor::RuntimeManager::createRuntimeManager(sche_config);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -20,9 +20,15 @@
|
|||
#endif
|
||||
|
||||
#ifdef MNN_USE_LOGCAT
|
||||
#if defined(__OHOS__)
|
||||
#include <hilog/log.h>
|
||||
#define MNN_ERROR(format, ...) {char logtmp[4096]; snprintf(logtmp, 4096, format, ##__VA_ARGS__); OH_LOG_Print(LOG_APP, LOG_ERROR, LOG_DOMAIN, "MNNJNI", (const char*)logtmp);}
|
||||
#define MNN_PRINT(format, ...) {char logtmp[4096]; snprintf(logtmp, 4096, format, ##__VA_ARGS__); OH_LOG_Print(LOG_APP, LOG_DEBUG, LOG_DOMAIN, "MNNJNI", (const char*)logtmp);}
|
||||
#else
|
||||
#include <android/log.h>
|
||||
#define MNN_ERROR(format, ...) __android_log_print(ANDROID_LOG_ERROR, "MNNJNI", format, ##__VA_ARGS__)
|
||||
#define MNN_PRINT(format, ...) __android_log_print(ANDROID_LOG_INFO, "MNNJNI", format, ##__VA_ARGS__)
|
||||
#endif
|
||||
#elif defined MNN_BUILD_FOR_IOS
|
||||
// on iOS, stderr prints to XCode debug area and syslog prints Console. You need both.
|
||||
#include <syslog.h>
|
||||
|
|
@ -67,8 +73,8 @@ MNN_ERROR("Check failed: %s ==> %s\n", #success, #log); \
|
|||
#endif
|
||||
#define STR_IMP(x) #x
|
||||
#define STR(x) STR_IMP(x)
|
||||
#define MNN_VERSION_MAJOR 2
|
||||
#define MNN_VERSION_MINOR 9
|
||||
#define MNN_VERSION_PATCH 6
|
||||
#define MNN_VERSION_MAJOR 3
|
||||
#define MNN_VERSION_MINOR 0
|
||||
#define MNN_VERSION_PATCH 0
|
||||
#define MNN_VERSION STR(MNN_VERSION_MAJOR) "." STR(MNN_VERSION_MINOR) "." STR(MNN_VERSION_PATCH)
|
||||
#endif /* MNNDefine_h */
|
||||
|
|
|
|||
|
|
@ -4,13 +4,12 @@ cmake ../../../ \
|
|||
-DCMAKE_BUILD_TYPE=Release \
|
||||
-DOHOS_ARCH="arm64-v8a" \
|
||||
-DOHOS_STL=c++_static \
|
||||
-DMNN_USE_LOGCAT=false \
|
||||
-DMNN_USE_LOGCAT=true \
|
||||
-DMNN_BUILD_BENCHMARK=ON \
|
||||
-DMNN_USE_SSE=OFF \
|
||||
-DMNN_SUPPORT_BF16=OFF \
|
||||
-DMNN_BUILD_TEST=ON \
|
||||
-DOHOS_PLATFORM_LEVEL=9 \
|
||||
-DMNN_BUILD_FOR_ANDROID_COMMAND=true \
|
||||
-DNATIVE_LIBRARY_OUTPUT=. -DNATIVE_INCLUDE_OUTPUT=. $1 $2 $3
|
||||
|
||||
make -j4
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
#!/bin/bash
|
||||
DIR=yanxing
|
||||
DIR=MNN
|
||||
hdc shell mkdir /data/local/tmp/MNN
|
||||
|
||||
make -j16
|
||||
hdc file send ./libMNN.so /data/local/tmp/$DIR/libMNN.so
|
||||
|
|
|
|||
|
|
@ -727,7 +727,7 @@
|
|||
952298B22B4D39050043978B /* MetalLoop.mm in Sources */ = {isa = PBXBuildFile; fileRef = 952298B12B4D39050043978B /* MetalLoop.mm */; };
|
||||
952298B42B4D39260043978B /* MetalArgMax.mm in Sources */ = {isa = PBXBuildFile; fileRef = 952298B32B4D39250043978B /* MetalArgMax.mm */; };
|
||||
952298B72B4D4CC80043978B /* CoreMLLayerNorm.cpp in Sources */ = {isa = PBXBuildFile; fileRef = 952298B52B4D4CC80043978B /* CoreMLLayerNorm.cpp */; };
|
||||
952298B82B4D4CC80043978B /* coreMLLayerNorm.hpp in Headers */ = {isa = PBXBuildFile; fileRef = 952298B62B4D4CC80043978B /* coreMLLayerNorm.hpp */; };
|
||||
952298B82B4D4CC80043978B /* CoreMLLayerNorm.hpp in Headers */ = {isa = PBXBuildFile; fileRef = 952298B62B4D4CC80043978B /* CoreMLLayerNorm.hpp */; };
|
||||
95278CE72B9F0999009E9B29 /* CPUDynamicQuant.hpp in Headers */ = {isa = PBXBuildFile; fileRef = 95278CE52B9F0999009E9B29 /* CPUDynamicQuant.hpp */; };
|
||||
95278CE82B9F0999009E9B29 /* CPUDynamicQuant.cpp in Sources */ = {isa = PBXBuildFile; fileRef = 95278CE62B9F0999009E9B29 /* CPUDynamicQuant.cpp */; };
|
||||
95278CEA2B9F09C0009E9B29 /* ShapeDynamicQuant.cpp in Sources */ = {isa = PBXBuildFile; fileRef = 95278CE92B9F09C0009E9B29 /* ShapeDynamicQuant.cpp */; };
|
||||
|
|
@ -796,6 +796,10 @@
|
|||
CEA49AA92AFD010900971CB7 /* MetalExecution.hpp in Headers */ = {isa = PBXBuildFile; fileRef = CEA49AA72AFD010900971CB7 /* MetalExecution.hpp */; };
|
||||
CEA82BDB2A15F8AD002CBC95 /* IdstConvolutionInt8.cpp in Sources */ = {isa = PBXBuildFile; fileRef = CEA82BD92A15F8AD002CBC95 /* IdstConvolutionInt8.cpp */; };
|
||||
CEA82BDC2A15F8AD002CBC95 /* IdstConvolutionInt8.hpp in Headers */ = {isa = PBXBuildFile; fileRef = CEA82BDA2A15F8AD002CBC95 /* IdstConvolutionInt8.hpp */; };
|
||||
CED81F8F2CC23C8A00666B48 /* CoreMLRelu6.cpp in Sources */ = {isa = PBXBuildFile; fileRef = CED81F8E2CC23C8A00666B48 /* CoreMLRelu6.cpp */; };
|
||||
CED81F902CC23C8A00666B48 /* CoreMLRelu6.hpp in Headers */ = {isa = PBXBuildFile; fileRef = CED81F8D2CC23C8A00666B48 /* CoreMLRelu6.hpp */; };
|
||||
CED81F932CC23FE800666B48 /* CoreMLMatMul.cpp in Sources */ = {isa = PBXBuildFile; fileRef = CED81F922CC23FE800666B48 /* CoreMLMatMul.cpp */; };
|
||||
CED81F942CC23FE800666B48 /* CoreMLMatMul.hpp in Headers */ = {isa = PBXBuildFile; fileRef = CED81F912CC23FE800666B48 /* CoreMLMatMul.hpp */; };
|
||||
CEDB20EB2846D07100AE9DC4 /* AppDelegate.m in Sources */ = {isa = PBXBuildFile; fileRef = CEDB20EA2846D07100AE9DC4 /* AppDelegate.m */; };
|
||||
CEDB20F42846D07100AE9DC4 /* Main.storyboard in Resources */ = {isa = PBXBuildFile; fileRef = CEDB20F22846D07100AE9DC4 /* Main.storyboard */; };
|
||||
CEDB20F62846D07200AE9DC4 /* Assets.xcassets in Resources */ = {isa = PBXBuildFile; fileRef = CEDB20F52846D07200AE9DC4 /* Assets.xcassets */; };
|
||||
|
|
@ -1580,7 +1584,7 @@
|
|||
952298B12B4D39050043978B /* MetalLoop.mm */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.objcpp; path = MetalLoop.mm; sourceTree = "<group>"; };
|
||||
952298B32B4D39250043978B /* MetalArgMax.mm */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.objcpp; path = MetalArgMax.mm; sourceTree = "<group>"; };
|
||||
952298B52B4D4CC80043978B /* CoreMLLayerNorm.cpp */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.cpp; path = CoreMLLayerNorm.cpp; sourceTree = "<group>"; };
|
||||
952298B62B4D4CC80043978B /* coreMLLayerNorm.hpp */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.h; path = coreMLLayerNorm.hpp; sourceTree = "<group>"; };
|
||||
952298B62B4D4CC80043978B /* CoreMLLayerNorm.hpp */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.h; path = CoreMLLayerNorm.hpp; sourceTree = "<group>"; };
|
||||
95278CE52B9F0999009E9B29 /* CPUDynamicQuant.hpp */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.h; path = CPUDynamicQuant.hpp; sourceTree = "<group>"; };
|
||||
95278CE62B9F0999009E9B29 /* CPUDynamicQuant.cpp */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.cpp; path = CPUDynamicQuant.cpp; sourceTree = "<group>"; };
|
||||
95278CE92B9F09C0009E9B29 /* ShapeDynamicQuant.cpp */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.cpp; path = ShapeDynamicQuant.cpp; sourceTree = "<group>"; };
|
||||
|
|
@ -1649,6 +1653,10 @@
|
|||
CEA49AA72AFD010900971CB7 /* MetalExecution.hpp */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.h; path = MetalExecution.hpp; sourceTree = "<group>"; };
|
||||
CEA82BD92A15F8AD002CBC95 /* IdstConvolutionInt8.cpp */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.cpp; path = IdstConvolutionInt8.cpp; sourceTree = "<group>"; };
|
||||
CEA82BDA2A15F8AD002CBC95 /* IdstConvolutionInt8.hpp */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.cpp.h; path = IdstConvolutionInt8.hpp; sourceTree = "<group>"; };
|
||||
CED81F8D2CC23C8A00666B48 /* CoreMLRelu6.hpp */ = {isa = PBXFileReference; lastKnownFileType = sourcecode.cpp.h; path = CoreMLRelu6.hpp; sourceTree = "<group>"; };
|
||||
CED81F8E2CC23C8A00666B48 /* CoreMLRelu6.cpp */ = {isa = PBXFileReference; lastKnownFileType = sourcecode.cpp.cpp; path = CoreMLRelu6.cpp; sourceTree = "<group>"; };
|
||||
CED81F912CC23FE800666B48 /* CoreMLMatMul.hpp */ = {isa = PBXFileReference; lastKnownFileType = sourcecode.cpp.h; path = CoreMLMatMul.hpp; sourceTree = "<group>"; };
|
||||
CED81F922CC23FE800666B48 /* CoreMLMatMul.cpp */ = {isa = PBXFileReference; lastKnownFileType = sourcecode.cpp.cpp; path = CoreMLMatMul.cpp; sourceTree = "<group>"; };
|
||||
CEDB20E72846D07100AE9DC4 /* demo.app */ = {isa = PBXFileReference; explicitFileType = wrapper.application; includeInIndex = 0; path = demo.app; sourceTree = BUILT_PRODUCTS_DIR; };
|
||||
CEDB20E92846D07100AE9DC4 /* AppDelegate.h */ = {isa = PBXFileReference; lastKnownFileType = sourcecode.c.h; path = AppDelegate.h; sourceTree = "<group>"; };
|
||||
CEDB20EA2846D07100AE9DC4 /* AppDelegate.m */ = {isa = PBXFileReference; lastKnownFileType = sourcecode.c.objc; path = AppDelegate.m; sourceTree = "<group>"; };
|
||||
|
|
@ -2364,8 +2372,12 @@
|
|||
4D9A933A26255BDA00F9B43C /* execution */ = {
|
||||
isa = PBXGroup;
|
||||
children = (
|
||||
CED81F912CC23FE800666B48 /* CoreMLMatMul.hpp */,
|
||||
CED81F922CC23FE800666B48 /* CoreMLMatMul.cpp */,
|
||||
CED81F8D2CC23C8A00666B48 /* CoreMLRelu6.hpp */,
|
||||
CED81F8E2CC23C8A00666B48 /* CoreMLRelu6.cpp */,
|
||||
952298B52B4D4CC80043978B /* CoreMLLayerNorm.cpp */,
|
||||
952298B62B4D4CC80043978B /* coreMLLayerNorm.hpp */,
|
||||
952298B62B4D4CC80043978B /* CoreMLLayerNorm.hpp */,
|
||||
4DF63F2E2660D9D100590730 /* CoreMLInterp.hpp */,
|
||||
4DF63F2C2660D9CB00590730 /* CoreMLInterp.cpp */,
|
||||
4D9A933B26255BDA00F9B43C /* CoreMLReduction.cpp */,
|
||||
|
|
@ -3009,6 +3021,7 @@
|
|||
92FF037823AA0B5A00AC97F6 /* CPUROIPooling.hpp in Headers */,
|
||||
4D9A935626255BDA00F9B43C /* Model.pb-c.h in Headers */,
|
||||
48747D6D245D9E33000B9709 /* ConvertUtils.hpp in Headers */,
|
||||
CED81F902CC23C8A00666B48 /* CoreMLRelu6.hpp in Headers */,
|
||||
4838EA832611C00B0027232C /* MetalGridSample.hpp in Headers */,
|
||||
92FF038723AA0B5A00AC97F6 /* CPUTensorConvert.hpp in Headers */,
|
||||
92FF036E23AA0B5A00AC97F6 /* CPUQuantizedSoftmax.hpp in Headers */,
|
||||
|
|
@ -3018,7 +3031,7 @@
|
|||
489D7A9B2550FDC900AD896A /* MetalDeconvolution.hpp in Headers */,
|
||||
4D9A935726255BDA00F9B43C /* protobuf-c.h in Headers */,
|
||||
489D7A982550FDC900AD896A /* MNNMetalContext.h in Headers */,
|
||||
952298B82B4D4CC80043978B /* coreMLLayerNorm.hpp in Headers */,
|
||||
952298B82B4D4CC80043978B /* CoreMLLayerNorm.hpp in Headers */,
|
||||
92FF029323AA0B5A00AC97F6 /* CPURange.hpp in Headers */,
|
||||
CEEDB5542C7475A100FED0DC /* MNNFileUtils.h in Headers */,
|
||||
4D9A937526255BDA00F9B43C /* CoreMLCommonExecution.hpp in Headers */,
|
||||
|
|
@ -3141,6 +3154,7 @@
|
|||
48C84B6C250F709E00EE7666 /* SizeComputer.hpp in Headers */,
|
||||
92FF035023AA0B5A00AC97F6 /* CPUOneHot.hpp in Headers */,
|
||||
92FF039123AA0B5A00AC97F6 /* CPUBackend.hpp in Headers */,
|
||||
CED81F942CC23FE800666B48 /* CoreMLMatMul.hpp in Headers */,
|
||||
489D7AA52550FDC900AD896A /* MetalInterp.hpp in Headers */,
|
||||
486E1A9A24F5078D00C16006 /* CPURandomUniform.hpp in Headers */,
|
||||
92FF038C23AA0B5A00AC97F6 /* CPUEltwise.hpp in Headers */,
|
||||
|
|
@ -3411,6 +3425,7 @@
|
|||
92FF02B023AA0B5A00AC97F6 /* CPUDequantize.cpp in Sources */,
|
||||
92FF04C223AA0BFB00AC97F6 /* Pipeline.cpp in Sources */,
|
||||
92FF04C423AA0BFB00AC97F6 /* Session.cpp in Sources */,
|
||||
CED81F932CC23FE800666B48 /* CoreMLMatMul.cpp in Sources */,
|
||||
952298B72B4D4CC80043978B /* CoreMLLayerNorm.cpp in Sources */,
|
||||
4D9A936826255BDA00F9B43C /* CoreMLCommonExecution.cpp in Sources */,
|
||||
92FF02D123AA0B5A00AC97F6 /* MNNMaxFloat.S in Sources */,
|
||||
|
|
@ -3640,6 +3655,7 @@
|
|||
CE072A262C91AF0700F190FD /* MNNC3ToYUVFast.S in Sources */,
|
||||
92FF042823AA0B7100AC97F6 /* ShapeInterp.cpp in Sources */,
|
||||
92FF02D623AA0B5A00AC97F6 /* MNNConvRunForLineDepthWiseInt8.S in Sources */,
|
||||
CED81F8F2CC23C8A00666B48 /* CoreMLRelu6.cpp in Sources */,
|
||||
48FB9DCA24A848D0008E1A2D /* MNNAxByClampBroadcastC4.S in Sources */,
|
||||
489D7A832550FDC900AD896A /* MetalMatMul.mm in Sources */,
|
||||
482BFBD028351BA1009210E4 /* AllShader.cpp in Sources */,
|
||||
|
|
@ -4148,7 +4164,7 @@
|
|||
METAL_LIBRARY_FILE_BASE = mnn;
|
||||
ONLY_ACTIVE_ARCH = YES;
|
||||
OTHER_CFLAGS = "";
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3;
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3vjk;
|
||||
PRODUCT_NAME = "$(TARGET_NAME:c99extidentifier)";
|
||||
PROVISIONING_PROFILE_SPECIFIER = "";
|
||||
"PROVISIONING_PROFILE_SPECIFIER[sdk=macosx*]" = "";
|
||||
|
|
@ -4210,7 +4226,7 @@
|
|||
MACH_O_TYPE = staticlib;
|
||||
METAL_LIBRARY_FILE_BASE = mnn;
|
||||
OTHER_CFLAGS = "";
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3;
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3vjk;
|
||||
PRODUCT_NAME = "$(TARGET_NAME:c99extidentifier)";
|
||||
PROVISIONING_PROFILE_SPECIFIER = "";
|
||||
"PROVISIONING_PROFILE_SPECIFIER[sdk=macosx*]" = "";
|
||||
|
|
@ -4244,7 +4260,7 @@
|
|||
IPHONEOS_DEPLOYMENT_TARGET = 9.0;
|
||||
LD_RUNPATH_SEARCH_PATHS = "$(inherited) @executable_path/Frameworks";
|
||||
OTHER_CPLUSPLUSFLAGS = "$(OTHER_CFLAGS)";
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3vj;
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3vjk;
|
||||
PRODUCT_NAME = "$(TARGET_NAME)";
|
||||
TARGETED_DEVICE_FAMILY = "1,2";
|
||||
};
|
||||
|
|
@ -4271,7 +4287,7 @@
|
|||
IPHONEOS_DEPLOYMENT_TARGET = 9.0;
|
||||
LD_RUNPATH_SEARCH_PATHS = "$(inherited) @executable_path/Frameworks";
|
||||
OTHER_CPLUSPLUSFLAGS = "$(OTHER_CFLAGS)";
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcdedddddd;
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3vjk;
|
||||
PRODUCT_NAME = "$(TARGET_NAME)";
|
||||
TARGETED_DEVICE_FAMILY = "1,2";
|
||||
};
|
||||
|
|
@ -4303,7 +4319,7 @@
|
|||
MARKETING_VERSION = 1.0;
|
||||
MTL_ENABLE_DEBUG_INFO = INCLUDE_SOURCE;
|
||||
MTL_FAST_MATH = YES;
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3vj;
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3vjk;
|
||||
PRODUCT_NAME = "$(TARGET_NAME)";
|
||||
SWIFT_EMIT_LOC_STRINGS = YES;
|
||||
TARGETED_DEVICE_FAMILY = "1,2";
|
||||
|
|
@ -4335,7 +4351,7 @@
|
|||
LD_RUNPATH_SEARCH_PATHS = "$(inherited) @executable_path/Frameworks";
|
||||
MARKETING_VERSION = 1.0;
|
||||
MTL_FAST_MATH = YES;
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3vj;
|
||||
PRODUCT_BUNDLE_IDENTIFIER = com.taobao.mnn.abcde3vjk;
|
||||
PRODUCT_NAME = "$(TARGET_NAME)";
|
||||
SWIFT_EMIT_LOC_STRINGS = YES;
|
||||
TARGETED_DEVICE_FAMILY = "1,2";
|
||||
|
|
|
|||
|
|
@ -16,8 +16,9 @@ option(PYMNN_TRAIN_API "MNN train API be exposed" OFF)
|
|||
option(PYMNN_INTERNAL_SERVING "Internal use only." OFF)
|
||||
option(PYMNN_OPENCV_API "MNN OpenCV API be exposed" ON)
|
||||
option(PYMNN_IMGCODECS "MNN IMGCODECS API be exposed" OFF)
|
||||
option(PYMNN_OHOS_INTERNAL "compile for harmony internal." OFF)
|
||||
|
||||
if (OHOS)
|
||||
if (PYMNN_OHOS_INTERNAL)
|
||||
include($ENV{NODE_PATH}/@ali/tcpkg/tcpkg.cmake)
|
||||
endif()
|
||||
|
||||
|
|
@ -189,7 +190,7 @@ if(WIN32 OR APPLE OR CMAKE_SYSTEM_NAME MATCHES "^Linux")
|
|||
else()
|
||||
target_include_directories(mnnpybridge PRIVATE ${MNN_DIR}/pymnn/src ${MNN_DIR}/pymnn/android/src/main/c/include)
|
||||
set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${MNN_DIR}/pymnn/android/src/main/jniLibs/${ANDROID_ABI})
|
||||
if (OHOS)
|
||||
if (PYMNN_OHOS_INTERNAL)
|
||||
target_link_libraries(mnnpybridge PRIVATE tcpkg::mnn)
|
||||
if(PYMNN_USE_ALINNPYTHON)
|
||||
target_link_libraries(mnnpybridge PRIVATE tcpkg::alinnpython)
|
||||
|
|
|
|||
|
|
@ -1,201 +0,0 @@
|
|||
from __future__ import print_function
|
||||
import time
|
||||
import argparse
|
||||
import numpy as np
|
||||
import tqdm
|
||||
import os
|
||||
import MNN
|
||||
from PIL import Image
|
||||
|
||||
nn = MNN.nn
|
||||
F = MNN.expr
|
||||
F.lazy_eval(True)
|
||||
|
||||
|
||||
# adapted from pycaffe
|
||||
def load_image(filename, color=True):
|
||||
"""
|
||||
Load an image converting from grayscale or alpha as needed.
|
||||
|
||||
Parameters
|
||||
----------
|
||||
filename : string
|
||||
color : boolean
|
||||
flag for color format. True (default) loads as RGB while False
|
||||
loads as intensity (if image is already grayscale).
|
||||
|
||||
Returns
|
||||
-------
|
||||
image : an image with type np.float32 in range [0, 1]
|
||||
of size (H x W x 3) in RGB or
|
||||
of size (H x W x 1) in grayscale.
|
||||
"""
|
||||
img = Image.open(filename)
|
||||
img = np.array(img)
|
||||
if img.ndim == 2:
|
||||
img = img[:, :, np.newaxis]
|
||||
if color:
|
||||
img = np.tile(img, (1, 1, 3))
|
||||
elif img.shape[2] == 4:
|
||||
img = img[:, :, :3]
|
||||
return img
|
||||
|
||||
|
||||
def center_crop(image_data, crop_factor):
|
||||
height, width, channels = image_data.shape
|
||||
|
||||
h_size = int(height * crop_factor)
|
||||
h_start = int((height - h_size) / 2)
|
||||
h_end = h_start + h_size
|
||||
|
||||
w_size = int(width * crop_factor)
|
||||
w_start = int((width - w_size) / 2)
|
||||
w_end = w_start + w_size
|
||||
|
||||
cropped_image = image_data[h_start:h_end, w_start:w_end, :]
|
||||
|
||||
return cropped_image
|
||||
|
||||
|
||||
def resize_image(image, shape):
|
||||
im = Image.fromarray(image)
|
||||
im = im.resize(shape)
|
||||
resized_image = np.array(im)
|
||||
|
||||
return resized_image
|
||||
|
||||
|
||||
class CalibrationDataset(MNN.data.Dataset):
|
||||
'''
|
||||
This is demo for Imagenet calibration dataset. like pytorch, you need to overload __getiterm__ and __len__ methods
|
||||
__getiterm__ should return a sample in F.const, and you should not use batch dimension here
|
||||
__len__ should return the number of total samples in the calibration dataset
|
||||
'''
|
||||
def __init__(self, image_folder):
|
||||
super(CalibrationDataset, self).__init__()
|
||||
self.image_folder = image_folder
|
||||
self.image_list = os.listdir(image_folder)[0:64]
|
||||
|
||||
def __getitem__(self, index):
|
||||
image_name = os.path.join(self.image_folder, self.image_list[index].split(' ')[0])
|
||||
|
||||
|
||||
# preprocess your data here, the following code are for tensorflow mobilenets
|
||||
image_data = load_image(image_name)
|
||||
image_data = center_crop(image_data, 0.875)
|
||||
image_data = resize_image(image_data, (224, 224))
|
||||
image_data = (image_data - 127.5) / 127.5
|
||||
|
||||
|
||||
# after preprocessing the data, convert it to MNN data structure
|
||||
dv = F.const(image_data.flatten().tolist(), [224, 224, 3], F.data_format.NHWC, F.dtype.float)
|
||||
|
||||
'''
|
||||
first list for inputs, and may have many inputs, so it's a list
|
||||
if your model have more than one inputs, add the preprocessed MNN const data to the input list
|
||||
|
||||
second list for targets, also, there may be more than one targets
|
||||
for calibration dataset, we don't need labels, so leave it blank
|
||||
|
||||
Note that, the input order in the first list should be the same in your 'config.yaml' file.
|
||||
'''
|
||||
|
||||
return [dv], []
|
||||
|
||||
def __len__(self):
|
||||
# size of the dataset
|
||||
return len(self.image_list)
|
||||
|
||||
|
||||
def get_mnn_format(format_str):
|
||||
fmt = str.lower(format_str)
|
||||
if fmt == 'nchw':
|
||||
return F.NCHW
|
||||
elif fmt == 'nhwc':
|
||||
return F.NHWC
|
||||
elif fmt == 'nc4hw4':
|
||||
return F.NC4HW4
|
||||
else:
|
||||
raise ValueError("unknown format:", format_str)
|
||||
|
||||
def quant_func(net, dataloader, opt):
|
||||
net.train(True)
|
||||
dataloader.reset()
|
||||
|
||||
t0 = time.time()
|
||||
for i in tqdm.trange(dataloader.iter_number):
|
||||
example = dataloader.next()
|
||||
input_data = example[0]
|
||||
predicts = net.forward(input_data)
|
||||
# fake update
|
||||
opt.step(F.const([0.0], []))
|
||||
for predict in predicts:
|
||||
predict.read()
|
||||
|
||||
t1 = time.time()
|
||||
cost = t1 - t0
|
||||
print("Epoch cost: %.3f s." % cost)
|
||||
|
||||
return cost
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--mnn_model", type=str, required=True,\
|
||||
help="original float MNN model file")
|
||||
parser.add_argument("--quant_imgs", type=str, required=True, \
|
||||
help="path of quant images")
|
||||
parser.add_argument("--quant_model", type=str, required=True, \
|
||||
help="name of quantized model to save")
|
||||
parser.add_argument("--batch_size", type=int, required=False, default=32,\
|
||||
help="calibration batch size")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
mnn_model = args.mnn_model
|
||||
quant_imgs = args.quant_imgs
|
||||
quant_model = args.quant_model
|
||||
batch_size = args.batch_size
|
||||
|
||||
calibration_dataset = CalibrationDataset(image_folder=quant_imgs)
|
||||
|
||||
dataloader = MNN.data.DataLoader(calibration_dataset, batch_size=batch_size, shuffle=True)
|
||||
|
||||
m = F.load_as_dict(mnn_model)
|
||||
|
||||
inputs_outputs = F.get_inputs_and_outputs(m)
|
||||
for key in inputs_outputs[0].keys():
|
||||
print('input names:\t', key)
|
||||
for key in inputs_outputs[1].keys():
|
||||
print('output names:\t', key)
|
||||
|
||||
# set inputs and outputs
|
||||
inputs = [m['input']]
|
||||
outputs = [m['MobilenetV2/Predictions/Reshape_1']]
|
||||
input_placeholders = []
|
||||
for i in range(len(inputs)):
|
||||
shape = [1, 3, 224, 224]
|
||||
fmt = 'nchw'
|
||||
nnn_format = get_mnn_format(fmt)
|
||||
placeholder = F.placeholder(shape, nnn_format)
|
||||
placeholder.name = 'input'
|
||||
input_placeholders.append(placeholder)
|
||||
|
||||
net = nn.load_module(inputs, outputs, True)
|
||||
|
||||
# no use optimizer
|
||||
opt = MNN.optim.SGD(net, 0.01, 0.9, 0.0005)
|
||||
|
||||
nn.compress.train_quant(net, quant_bits=8)
|
||||
|
||||
used_time = quant_func(net, dataloader, opt)
|
||||
|
||||
# save model
|
||||
net.train(False)
|
||||
predicts = net.forward(input_placeholders)
|
||||
print("quantized model save to " + quant_model)
|
||||
F.save(predicts, quant_model)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
@ -24,6 +24,18 @@ static PyObject* PyMNNLLM_load(LLM *self, PyObject *args) {
|
|||
Py_RETURN_NONE;
|
||||
}
|
||||
|
||||
static PyObject* PyMNNLLM_forward(LLM *self, PyObject *args) {
|
||||
PyObject *input_ids = nullptr;
|
||||
if (!PyArg_ParseTuple(args, "O", &input_ids) && isInts(input_ids)) {
|
||||
Py_RETURN_NONE;
|
||||
}
|
||||
auto logits = getVar();
|
||||
self->llm->generate_init();
|
||||
*(logits->var) = self->llm->forward(toInts(input_ids));
|
||||
self->llm->reset();
|
||||
return (PyObject *)logits;
|
||||
}
|
||||
|
||||
static PyObject* PyMNNLLM_generate(LLM *self, PyObject *args) {
|
||||
PyObject *input_ids = nullptr;
|
||||
if (!PyArg_ParseTuple(args, "O", &input_ids) && isInts(input_ids)) {
|
||||
|
|
@ -44,10 +56,32 @@ static PyObject* PyMNNLLM_response(LLM *self, PyObject *args) {
|
|||
return string2Object(res);
|
||||
}
|
||||
|
||||
static PyObject* PyMNNLLM_tokenizer_encode(LLM *self, PyObject *args) {
|
||||
const char* prompt = NULL;
|
||||
int use_template = 0;
|
||||
if (!PyArg_ParseTuple(args, "s|p", &prompt, &use_template)) {
|
||||
Py_RETURN_NONE;
|
||||
}
|
||||
auto ids = self->llm->tokenizer_encode(prompt, use_template);
|
||||
return toPyObj<int, toPyObj>(ids);
|
||||
}
|
||||
|
||||
static PyObject* PyMNNLLM_tokenizer_decode(LLM *self, PyObject *args) {
|
||||
PyObject *id = nullptr;
|
||||
if (!PyArg_ParseTuple(args, "O", &id) && isInt(id)) {
|
||||
Py_RETURN_NONE;
|
||||
}
|
||||
auto query = self->llm->tokenizer_decode(toInt(id));
|
||||
return string2Object(query);
|
||||
}
|
||||
|
||||
static PyMethodDef PyMNNLLM_methods[] = {
|
||||
{"load", (PyCFunction)PyMNNLLM_load, METH_VARARGS, "load model."},
|
||||
{"forward", (PyCFunction)PyMNNLLM_forward, METH_VARARGS, "forward `logits` by `input_ids`."},
|
||||
{"generate", (PyCFunction)PyMNNLLM_generate, METH_VARARGS, "generate `output_ids` by `input_ids`."},
|
||||
{"response", (PyCFunction)PyMNNLLM_response, METH_VARARGS, "response `query` without hsitory."},
|
||||
{"tokenizer_encode", (PyCFunction)PyMNNLLM_tokenizer_encode, METH_VARARGS, "tokenizer encode."},
|
||||
{"tokenizer_decode", (PyCFunction)PyMNNLLM_tokenizer_decode, METH_VARARGS, "tokenizer decode."},
|
||||
{NULL} /* Sentinel */
|
||||
};
|
||||
|
||||
|
|
|
|||
|
|
@ -1140,6 +1140,7 @@ struct QuantizedFloatParamT : public flatbuffers::NativeTable {
|
|||
int8_t clampMax;
|
||||
std::vector<int32_t> winogradAttr;
|
||||
DataType outputDataType;
|
||||
std::vector<float> floatzeros;
|
||||
QuantizedFloatParamT()
|
||||
: method(QuantizeAlgo_DEFAULT),
|
||||
nbits(8),
|
||||
|
|
@ -1192,6 +1193,9 @@ struct QuantizedFloatParam FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table
|
|||
DataType outputDataType() const {
|
||||
return static_cast<DataType>(GetField<int32_t>(26, 6));
|
||||
}
|
||||
const flatbuffers::Vector<float> *floatzeros() const {
|
||||
return GetPointer<const flatbuffers::Vector<float> *>(28);
|
||||
}
|
||||
bool Verify(flatbuffers::Verifier &verifier) const {
|
||||
return VerifyTableStart(verifier) &&
|
||||
VerifyOffset(verifier, 4) &&
|
||||
|
|
@ -1211,6 +1215,8 @@ struct QuantizedFloatParam FLATBUFFERS_FINAL_CLASS : private flatbuffers::Table
|
|||
VerifyOffset(verifier, 24) &&
|
||||
verifier.VerifyVector(winogradAttr()) &&
|
||||
VerifyField<int32_t>(verifier, 26) &&
|
||||
VerifyOffset(verifier, 28) &&
|
||||
verifier.VerifyVector(floatzeros()) &&
|
||||
verifier.EndTable();
|
||||
}
|
||||
QuantizedFloatParamT *UnPack(const flatbuffers::resolver_function_t *_resolver = nullptr) const;
|
||||
|
|
@ -1257,6 +1263,9 @@ struct QuantizedFloatParamBuilder {
|
|||
void add_outputDataType(DataType outputDataType) {
|
||||
fbb_.AddElement<int32_t>(26, static_cast<int32_t>(outputDataType), 6);
|
||||
}
|
||||
void add_floatzeros(flatbuffers::Offset<flatbuffers::Vector<float>> floatzeros) {
|
||||
fbb_.AddOffset(28, floatzeros);
|
||||
}
|
||||
explicit QuantizedFloatParamBuilder(flatbuffers::FlatBufferBuilder &_fbb)
|
||||
: fbb_(_fbb) {
|
||||
start_ = fbb_.StartTable();
|
||||
|
|
@ -1282,8 +1291,10 @@ inline flatbuffers::Offset<QuantizedFloatParam> CreateQuantizedFloatParam(
|
|||
int8_t clampMin = -128,
|
||||
int8_t clampMax = 127,
|
||||
flatbuffers::Offset<flatbuffers::Vector<int32_t>> winogradAttr = 0,
|
||||
DataType outputDataType = DataType_DT_INT8) {
|
||||
DataType outputDataType = DataType_DT_INT8,
|
||||
flatbuffers::Offset<flatbuffers::Vector<float>> floatzeros = 0) {
|
||||
QuantizedFloatParamBuilder builder_(_fbb);
|
||||
builder_.add_floatzeros(floatzeros);
|
||||
builder_.add_outputDataType(outputDataType);
|
||||
builder_.add_winogradAttr(winogradAttr);
|
||||
builder_.add_nbits(nbits);
|
||||
|
|
@ -4500,6 +4511,7 @@ inline void QuantizedFloatParam::UnPackTo(QuantizedFloatParamT *_o, const flatbu
|
|||
{ auto _e = clampMax(); _o->clampMax = _e; };
|
||||
{ auto _e = winogradAttr(); if (_e) { _o->winogradAttr.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->winogradAttr[_i] = _e->Get(_i); } } };
|
||||
{ auto _e = outputDataType(); _o->outputDataType = _e; };
|
||||
{ auto _e = floatzeros(); if (_e) { _o->floatzeros.resize(_e->size()); for (flatbuffers::uoffset_t _i = 0; _i < _e->size(); _i++) { _o->floatzeros[_i] = _e->Get(_i); } } };
|
||||
}
|
||||
|
||||
inline flatbuffers::Offset<QuantizedFloatParam> QuantizedFloatParam::Pack(flatbuffers::FlatBufferBuilder &_fbb, const QuantizedFloatParamT* _o, const flatbuffers::rehasher_function_t *_rehasher) {
|
||||
|
|
@ -4522,6 +4534,7 @@ inline flatbuffers::Offset<QuantizedFloatParam> CreateQuantizedFloatParam(flatbu
|
|||
auto _clampMax = _o->clampMax;
|
||||
auto _winogradAttr = _o->winogradAttr.size() ? _fbb.CreateVector(_o->winogradAttr) : 0;
|
||||
auto _outputDataType = _o->outputDataType;
|
||||
auto _floatzeros = _o->floatzeros.size() ? _fbb.CreateVector(_o->floatzeros) : 0;
|
||||
return MNN::CreateQuantizedFloatParam(
|
||||
_fbb,
|
||||
_weight,
|
||||
|
|
@ -4535,7 +4548,8 @@ inline flatbuffers::Offset<QuantizedFloatParam> CreateQuantizedFloatParam(flatbu
|
|||
_clampMin,
|
||||
_clampMax,
|
||||
_winogradAttr,
|
||||
_outputDataType);
|
||||
_outputDataType,
|
||||
_floatzeros);
|
||||
}
|
||||
|
||||
inline Convolution2DT *Convolution2D::UnPack(const flatbuffers::resolver_function_t *_resolver) const {
|
||||
|
|
@ -6004,7 +6018,8 @@ inline const flatbuffers::TypeTable *QuantizedFloatParamTypeTable() {
|
|||
{ flatbuffers::ET_CHAR, 0, -1 },
|
||||
{ flatbuffers::ET_CHAR, 0, -1 },
|
||||
{ flatbuffers::ET_INT, 1, -1 },
|
||||
{ flatbuffers::ET_INT, 0, 1 }
|
||||
{ flatbuffers::ET_INT, 0, 1 },
|
||||
{ flatbuffers::ET_FLOAT, 1, -1 }
|
||||
};
|
||||
static const flatbuffers::TypeFunction type_refs[] = {
|
||||
QuantizeAlgoTypeTable,
|
||||
|
|
@ -6022,10 +6037,11 @@ inline const flatbuffers::TypeTable *QuantizedFloatParamTypeTable() {
|
|||
"clampMin",
|
||||
"clampMax",
|
||||
"winogradAttr",
|
||||
"outputDataType"
|
||||
"outputDataType",
|
||||
"floatzeros"
|
||||
};
|
||||
static const flatbuffers::TypeTable tt = {
|
||||
flatbuffers::ST_TABLE, 12, type_codes, type_refs, nullptr, names
|
||||
flatbuffers::ST_TABLE, 13, type_codes, type_refs, nullptr, names
|
||||
};
|
||||
return &tt;
|
||||
}
|
||||
|
|
|
|||
|
|
@ -193,7 +193,7 @@ enum OpType {
|
|||
OpType_Segment = 89,
|
||||
OpType_Squeeze = 90,
|
||||
OpType_StridedSlice = 91,
|
||||
OpType_StringJoin = 92,
|
||||
OpType_CastLike = 92,
|
||||
OpType_StringSplit = 93,
|
||||
OpType_StringToNumber = 94,
|
||||
OpType_TanH = 95,
|
||||
|
|
@ -381,7 +381,7 @@ inline const OpType (&EnumValuesOpType())[182] {
|
|||
OpType_Segment,
|
||||
OpType_Squeeze,
|
||||
OpType_StridedSlice,
|
||||
OpType_StringJoin,
|
||||
OpType_CastLike,
|
||||
OpType_StringSplit,
|
||||
OpType_StringToNumber,
|
||||
OpType_TanH,
|
||||
|
|
@ -569,7 +569,7 @@ inline const char * const *EnumNamesOpType() {
|
|||
"Segment",
|
||||
"Squeeze",
|
||||
"StridedSlice",
|
||||
"StringJoin",
|
||||
"CastLike",
|
||||
"StringSplit",
|
||||
"StringToNumber",
|
||||
"TanH",
|
||||
|
|
@ -8006,7 +8006,7 @@ inline const flatbuffers::TypeTable *OpTypeTypeTable() {
|
|||
"Segment",
|
||||
"Squeeze",
|
||||
"StridedSlice",
|
||||
"StringJoin",
|
||||
"CastLike",
|
||||
"StringSplit",
|
||||
"StringToNumber",
|
||||
"TanH",
|
||||
|
|
|
|||
|
|
@ -96,6 +96,7 @@ table QuantizedFloatParam{
|
|||
// binary proto: [originKySize, originKxSize, transKySize, transKxSize, {kyStart, kxStart, unitY, unitX}, {...} ...]
|
||||
winogradAttr:[int];
|
||||
outputDataType:DataType=DT_INT8;
|
||||
floatzeros: [float];
|
||||
}
|
||||
|
||||
table Convolution2D {
|
||||
|
|
|
|||
|
|
@ -107,7 +107,7 @@ enum OpType : int {
|
|||
Segment,
|
||||
Squeeze,
|
||||
StridedSlice,
|
||||
StringJoin,
|
||||
CastLike,
|
||||
StringSplit,
|
||||
StringToNumber,
|
||||
TanH,
|
||||
|
|
|
|||
|
|
@ -42,6 +42,7 @@ bool Arm82Backend::addArm82Creator(OpType t, Arm82Creator* ct) {
|
|||
|
||||
Arm82Backend::Arm82Backend(const CPURuntime* runtime, BackendConfig::MemoryMode memory) : CPUBackend(runtime, BackendConfig::Precision_Low, memory, MNN_FORWARD_CPU_EXTENSION) {
|
||||
mCoreFunctions = Arm82Functions::get();
|
||||
mInt8CoreFunctions = Arm82Functions::getInt8();
|
||||
}
|
||||
|
||||
Arm82Backend::~Arm82Backend() {
|
||||
|
|
|
|||
|
|
@ -526,7 +526,7 @@ static void _MNNComputeMatMulForE_1_FP16(const float* AF, const float* BF, float
|
|||
Vec sumValue = Vec(0.0f);
|
||||
auto by = B + y * l;
|
||||
for (int x=0; x<lC4; ++x) {
|
||||
sumValue = sumValue + Vec::load(A + x * 8) * Vec::load(by + x * 8);
|
||||
sumValue = Vec::fma(sumValue, Vec::load(A + x * 8), Vec::load(by + x * 8));
|
||||
}
|
||||
if (lR > 0) {
|
||||
FLOAT16 AR[8] = {0, 0, 0, 0, 0, 0, 0, 0};
|
||||
|
|
@ -544,7 +544,36 @@ static void _MNNComputeMatMulForE_1_FP16(const float* AF, const float* BF, float
|
|||
} else {
|
||||
auto hC4 = h / 8;
|
||||
auto hR = h % 8;
|
||||
for (int y=tId; y<hC4; y+=numberThread) {
|
||||
auto hC16 = hC4 / 4;
|
||||
auto hC4R = hC4 % 4;
|
||||
for (int y=tId; y<hC16; y+=numberThread) {
|
||||
auto biasP = biasPtr + 8 * 4 * y;
|
||||
auto bs = B + 8 * 4 * y;
|
||||
Vec s0 = Vec(0.0f);
|
||||
Vec s1 = Vec(0.0f);
|
||||
Vec s2 = Vec(0.0f);
|
||||
Vec s3 = Vec(0.0f);
|
||||
if (biasPtr != nullptr) {
|
||||
s0 = Vec::load(biasP + 8 * 0);
|
||||
s1 = Vec::load(biasP + 8 * 1);
|
||||
s2 = Vec::load(biasP + 8 * 2);
|
||||
s3 = Vec::load(biasP + 8 * 3);
|
||||
}
|
||||
auto srcY = A + y * l * 8 * 4;
|
||||
for (int x=0; x<l; ++x) {
|
||||
auto a = Vec(A[x]);
|
||||
s0 = Vec::fma(s0, a, Vec::load(bs + h * x + 0 * 8));
|
||||
s1 = Vec::fma(s1, a, Vec::load(bs + h * x + 1 * 8));
|
||||
s2 = Vec::fma(s2, a, Vec::load(bs + h * x + 2 * 8));
|
||||
s3 = Vec::fma(s3, a, Vec::load(bs + h * x + 3 * 8));
|
||||
}
|
||||
Vec::save(C + 4 * 8 * y + 8 * 0, s0);
|
||||
Vec::save(C + 4 * 8 * y + 8 * 1, s1);
|
||||
Vec::save(C + 4 * 8 * y + 8 * 2, s2);
|
||||
Vec::save(C + 4 * 8 * y + 8 * 3, s3);
|
||||
}
|
||||
|
||||
for (int y=hC16*4+tId; y<hC4; y+=numberThread) {
|
||||
auto bs = B + 8 * y;
|
||||
Vec sumValue = Vec(0.0f);
|
||||
if (biasPtr != nullptr) {
|
||||
|
|
@ -552,7 +581,7 @@ static void _MNNComputeMatMulForE_1_FP16(const float* AF, const float* BF, float
|
|||
}
|
||||
auto srcY = A + y * l * 8;
|
||||
for (int x=0; x<l; ++x) {
|
||||
sumValue = sumValue + Vec(A[x]) * Vec::load(bs + h * x);
|
||||
sumValue = Vec::fma(sumValue, Vec(A[x]), Vec::load(bs + h * x));
|
||||
}
|
||||
Vec::save(C + 8 * y, sumValue);
|
||||
}
|
||||
|
|
@ -577,13 +606,217 @@ static void _MNNComputeMatMulForE_1_FP16(const float* AF, const float* BF, float
|
|||
}
|
||||
}
|
||||
|
||||
template<int EP, int LP>
|
||||
static void _Arm82MNNPackC4ForMatMul_A(int8_t* destOrigin, int8_t const** sourceGroup, const int32_t* info, const int32_t* el) {
|
||||
const int pack = 8;
|
||||
int number = info[0];
|
||||
int eReal = info[1];
|
||||
int xStride = info[3];
|
||||
int xS4 = xStride * pack / sizeof(int32_t);
|
||||
int PUNIT = pack / LP;
|
||||
int FLOATPACK = pack / sizeof(int32_t);
|
||||
int eOutsideStride = info[2] / sizeof(int32_t);
|
||||
int eDest = EP;
|
||||
int realDstCount = info[4];
|
||||
for (int n=0; n<number; ++n) {
|
||||
int e = el[4 * n + 0];
|
||||
int l = el[4 * n + 1];
|
||||
int eOffset = el[4 * n + 2];
|
||||
int lOffset = el[4 * n + 3];
|
||||
int eC = eOffset / EP;
|
||||
int eR = eOffset % EP;
|
||||
int eS = eDest - eR;
|
||||
bool lastBag = false;
|
||||
int eOutsideStride4LastBag = eOutsideStride;
|
||||
if (realDstCount % EP > 0) {
|
||||
int jobsE = realDstCount - eOffset - e;
|
||||
if (jobsE == 0 || (jobsE < (realDstCount % EP))) {
|
||||
lastBag = true;
|
||||
}
|
||||
}
|
||||
auto source = (int32_t*)sourceGroup[n];
|
||||
auto dest = (int32_t*)(destOrigin + eC * info[2] + eR * LP + lOffset * EP);
|
||||
//printf("e=%d, l=%d, eOffset=%d, lOffset=%d, eDest=%d\n", e, l, eOffset, lOffset, eDest);
|
||||
l = l / 4; // Use float instead of int8 * 4
|
||||
if (lastBag && e + eR < EP) {
|
||||
int elast = ALIMAX(eR + e, realDstCount % EP);
|
||||
dest = (int32_t*)(destOrigin + lOffset * elast + eC * info[2] + eR * LP);
|
||||
}
|
||||
int offsetLC = lOffset / 4;
|
||||
for (int x = 0; x < l; ++x) {
|
||||
int eRemain = e;
|
||||
auto xR = x % PUNIT;
|
||||
auto xC = x / PUNIT;
|
||||
auto d = dest;
|
||||
auto s = source + xC * eReal * FLOATPACK + xR;
|
||||
if (eR > 0) {
|
||||
int eStep = ALIMIN(eRemain, eS);
|
||||
for (int yi=0; yi<eStep; ++yi) {
|
||||
d[yi] = s[yi * xS4];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag ||eRemain >= EP) {
|
||||
d += (eOutsideStride - eR);
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * 4 * offsetLC / sizeof(float));
|
||||
d += (eOutsideStride4LastBag - eR + offsetLC * eFill);
|
||||
}
|
||||
s += eS * xS4;
|
||||
}
|
||||
while (eRemain > 0) {
|
||||
int eStep = ALIMIN(eDest, eRemain);
|
||||
for (int yi=0; yi<eStep; ++yi) {
|
||||
d[yi] = s[yi * xS4];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag || eRemain >= EP) {
|
||||
d+= eOutsideStride;
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * 4 * offsetLC / sizeof(float));
|
||||
d+= (eOutsideStride4LastBag + offsetLC * eFill);
|
||||
}
|
||||
s+= eStep * xS4;
|
||||
}
|
||||
if (lastBag && e + eR < EP) {
|
||||
int efill = ALIMAX(e + eR, realDstCount % EP);
|
||||
dest += efill;
|
||||
} else {
|
||||
dest += eDest;
|
||||
}
|
||||
offsetLC++;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
template<int EP, int HP>
|
||||
static void _ArmBasicMNNPackC4ForMatMul_A_L8(int8_t* destOrigin, int8_t const** sourceGroup, const int32_t* info, const int32_t* el) {
|
||||
int number = info[0];
|
||||
int eReal = info[1];
|
||||
int eDest = EP;
|
||||
int offset = info[3];
|
||||
const int LP = 8;
|
||||
int eOutsideStride = info[2] / sizeof(int64_t);
|
||||
int realDstCount = info[4];
|
||||
for (int n=0; n<number; ++n) {
|
||||
int e = el[4 * n + 0];
|
||||
int l = el[4 * n + 1];
|
||||
int eOffset = el[4 * n + 2];
|
||||
int lOffset = el[4 * n + 3];
|
||||
int eC = eOffset / EP;
|
||||
int eR = eOffset % EP;
|
||||
int eS = eDest - eR;
|
||||
bool lastBag = false;
|
||||
int eOutsideStride4LastBag = eOutsideStride;
|
||||
int eres = realDstCount - eOffset;
|
||||
if (realDstCount % EP > 0) {
|
||||
int jobsE = realDstCount - eOffset - e;
|
||||
if (jobsE == 0 || (jobsE < (realDstCount % EP))) {
|
||||
lastBag = true;
|
||||
}
|
||||
}
|
||||
auto dest = (int64_t*)(destOrigin + lOffset * eDest + eC * info[2] + eR * LP);
|
||||
auto source = (int64_t*)sourceGroup[n];
|
||||
int lRemain = l / LP;
|
||||
if (lastBag && e + eR < EP) {
|
||||
int elast = ALIMIN(ALIMAX(eR + e, realDstCount % EP), EP);
|
||||
dest = (int64_t*)(destOrigin + lOffset * elast + eC * info[2] + eR * LP);
|
||||
}
|
||||
int offsetLC = lOffset / LP;
|
||||
for (int x = 0; x < lRemain; ++x) {
|
||||
int eRemain = e;
|
||||
auto d = dest;
|
||||
auto s = source;
|
||||
if (1 == offset) {
|
||||
if (eR > 0) {
|
||||
int eStep = ALIMIN(eRemain, eS);
|
||||
::memcpy(d, s, eStep * sizeof(int64_t));
|
||||
eRemain-=eStep;
|
||||
if (!lastBag ||eRemain >= EP) {
|
||||
d += (eOutsideStride - eR);
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * offsetLC);
|
||||
d += (eOutsideStride4LastBag - eR + offsetLC * eFill);
|
||||
}
|
||||
s += (eS * offset);
|
||||
}
|
||||
while (eRemain > 0) {
|
||||
int eStep = ALIMIN(eDest, eRemain);
|
||||
::memcpy(d, s, eStep * sizeof(int64_t));
|
||||
eRemain-=eStep;
|
||||
if (!lastBag || eRemain >= EP) {
|
||||
d+= eOutsideStride;
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * offsetLC);
|
||||
d+= (eOutsideStride4LastBag + offsetLC * eFill);
|
||||
}
|
||||
s+= (eStep * offset);
|
||||
}
|
||||
} else {
|
||||
if (eR > 0) {
|
||||
int eStep = ALIMIN(eRemain, eS);
|
||||
for (int yi=0; yi<eStep; ++yi) {
|
||||
d[yi] = s[yi * offset];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag ||eRemain >= EP) {
|
||||
d += (eOutsideStride - eR);
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * offsetLC);
|
||||
d += (eOutsideStride4LastBag - eR + offsetLC * eFill);
|
||||
}
|
||||
s += eS * offset;
|
||||
}
|
||||
while (eRemain > 0) {
|
||||
int eStep = ALIMIN(eDest, eRemain);
|
||||
for (int yi=0; yi<eStep; ++yi) {
|
||||
d[yi] = s[yi * offset];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag || eRemain >= EP) {
|
||||
d+= eOutsideStride;
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * offsetLC);
|
||||
d+= (eOutsideStride4LastBag + offsetLC * eFill);
|
||||
}
|
||||
s+= eStep * offset;
|
||||
}
|
||||
}
|
||||
source += eReal;
|
||||
if (lastBag && e + eR < EP ) { // eR=0;eR>0
|
||||
int efill = ALIMAX(e + eR, realDstCount % EP);
|
||||
dest += efill;
|
||||
} else {
|
||||
dest += eDest;
|
||||
}
|
||||
offsetLC++;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
static CoreFunctions* gInstance = nullptr;
|
||||
static CoreInt8Functions* gArm82CoreInt8Functions = nullptr;
|
||||
|
||||
bool Arm82Functions::init() {
|
||||
using Vec = MNN::Math::Vec<FLOAT16, 8>;
|
||||
auto origin = MNNGetCoreFunctions();
|
||||
#define FUNC_PTR_ASSIGN(dst, src) dst = (decltype(dst))(src)
|
||||
gInstance = new CoreFunctions;
|
||||
gArm82CoreInt8Functions = new CoreInt8Functions;
|
||||
*gArm82CoreInt8Functions = *MNNGetInt8CoreFunctions();
|
||||
{
|
||||
if (origin->supportSDot) {
|
||||
gArm82CoreInt8Functions->MNNPackC4Int8ForMatMul_A = _Arm82MNNPackC4ForMatMul_A<12, 4>;
|
||||
}
|
||||
if (origin->supportI8mm) {
|
||||
gArm82CoreInt8Functions->MNNPackC4Int8ForMatMul_A = _ArmBasicMNNPackC4ForMatMul_A_L8<10, 8>;
|
||||
}
|
||||
}
|
||||
|
||||
FUNC_PTR_ASSIGN(gInstance->MNNFp32ToFp8, MNNFp32ToFp8);
|
||||
FUNC_PTR_ASSIGN(gInstance->MNNFp16ToFp8, MNNFp16ToFp8);
|
||||
|
|
@ -674,5 +907,8 @@ bool Arm82Functions::init() {
|
|||
CoreFunctions* Arm82Functions::get() {
|
||||
return gInstance;
|
||||
}
|
||||
CoreInt8Functions* Arm82Functions::getInt8() {
|
||||
return gArm82CoreInt8Functions;
|
||||
}
|
||||
};
|
||||
#endif
|
||||
|
|
|
|||
|
|
@ -12,6 +12,7 @@ class Arm82Functions {
|
|||
public:
|
||||
static bool init();
|
||||
static CoreFunctions* get();
|
||||
static CoreInt8Functions* getInt8();
|
||||
};
|
||||
|
||||
};
|
||||
|
|
|
|||
|
|
@ -22,8 +22,6 @@
|
|||
//void MNNDynamicQuantFP16(const float* src, int8_t* dst, const float* scale, size_t src_depth_quad, size_t realSize, int pack)
|
||||
asm_function MNNDynamicQuantFP16
|
||||
|
||||
// Feature: quant and reorder C8->C4
|
||||
|
||||
// x0: src, x1:dst, x2:scale, x3:src_depth_quad, x4:realSize
|
||||
stp d14, d15, [sp, #(-16 * 4)]!
|
||||
stp d12, d13, [sp, #(16 * 1)]
|
||||
|
|
@ -33,21 +31,191 @@ stp d8, d9, [sp, #(16 * 3)]
|
|||
Start:
|
||||
lsl x6, x4, #3 // dst_step = batch * (2*unit) * sizeof(int8_t) = batch * 8 = batch << 3
|
||||
lsl x7, x4, #4 // src_step = batch * pack * sizeof(float16) = batch * 8 * 2 = batch << 4
|
||||
lsl x8, x4, #2 // 4 * plane
|
||||
add x11, x1, x8 // second N*4
|
||||
|
||||
TILE_24:
|
||||
cmp x4, #24
|
||||
blt TILE_16
|
||||
mov x9, x0 // src
|
||||
mov x10, x1 // dst
|
||||
sub x15, x6, #128
|
||||
mov x12, x3 // src_depth_quad
|
||||
sub x13, x7, #320 // src_step - 320
|
||||
|
||||
ld1 {v12.4s, v13.4s, v14.4s, v15.4s}, [x2], #64
|
||||
ld1 {v16.4s, v17.4s}, [x2], #32
|
||||
fcvtn v12.4h, v12.4s
|
||||
fcvtn2 v12.8h, v13.4s
|
||||
fcvtn v13.4h, v14.4s
|
||||
fcvtn2 v13.8h, v15.4s
|
||||
fcvtn v14.4h, v16.4s
|
||||
fcvtn2 v14.8h, v17.4s
|
||||
|
||||
LoopSz_24:
|
||||
ld1 {v0.8h, v1.8h, v2.8h, v3.8h}, [x9], #64
|
||||
ld1 {v4.8h, v5.8h, v6.8h, v7.8h}, [x9], #64
|
||||
ld1 {v8.8h, v9.8h, v10.8h, v11.8h}, [x9], #64
|
||||
ld1 {v15.8h, v16.8h, v17.8h, v18.8h}, [x9], #64
|
||||
ld1 {v19.8h, v20.8h, v21.8h, v22.8h}, [x9], #64
|
||||
ld1 {v23.8h, v24.8h, v25.8h, v26.8h}, [x9], x13
|
||||
|
||||
// float16_t x = x * quant_scale
|
||||
fmul v0.8h, v0.8h, v12.h[0]
|
||||
fmul v1.8h, v1.8h, v12.h[1]
|
||||
fmul v2.8h, v2.8h, v12.h[2]
|
||||
fmul v3.8h, v3.8h, v12.h[3]
|
||||
fmul v4.8h, v4.8h, v12.h[4]
|
||||
fmul v5.8h, v5.8h, v12.h[5]
|
||||
fmul v6.8h, v6.8h, v12.h[6]
|
||||
fmul v7.8h, v7.8h, v12.h[7]
|
||||
fmul v8.8h, v8.8h, v13.h[0]
|
||||
fmul v9.8h, v9.8h, v13.h[1]
|
||||
fmul v10.8h, v10.8h, v13.h[2]
|
||||
fmul v11.8h, v11.8h, v13.h[3]
|
||||
fmul v15.8h, v15.8h, v13.h[4]
|
||||
fmul v16.8h, v16.8h, v13.h[5]
|
||||
fmul v17.8h, v17.8h, v13.h[6]
|
||||
fmul v18.8h, v18.8h, v13.h[7]
|
||||
|
||||
fmul v19.8h, v19.8h, v14.h[0]
|
||||
fmul v20.8h, v20.8h, v14.h[1]
|
||||
fmul v21.8h, v21.8h, v14.h[2]
|
||||
fmul v22.8h, v22.8h, v14.h[3]
|
||||
fmul v23.8h, v23.8h, v14.h[4]
|
||||
fmul v24.8h, v24.8h, v14.h[5]
|
||||
fmul v25.8h, v25.8h, v14.h[6]
|
||||
fmul v26.8h, v26.8h, v14.h[7]
|
||||
|
||||
// int16_t x = round(x)
|
||||
Round v0, v1, v2, v3
|
||||
Round v4, v5, v6, v7
|
||||
Round v8, v9, v10, v11
|
||||
Round v15, v16, v17, v18
|
||||
Round v19, v20, v21, v22
|
||||
Round v23, v24, v25, v26
|
||||
|
||||
// y = (int8_t)x
|
||||
sqxtn v27.8b, v0.8h
|
||||
sqxtn2 v27.16b, v1.8h
|
||||
sqxtn v28.8b, v2.8h
|
||||
sqxtn2 v28.16b, v3.8h
|
||||
sqxtn v29.8b, v4.8h
|
||||
sqxtn2 v29.16b, v5.8h
|
||||
sqxtn v30.8b, v6.8h
|
||||
sqxtn2 v30.16b, v7.8h
|
||||
sqxtn v0.8b, v8.8h
|
||||
sqxtn2 v0.16b, v9.8h
|
||||
sqxtn v1.8b, v10.8h
|
||||
sqxtn2 v1.16b, v11.8h
|
||||
sqxtn v2.8b, v15.8h
|
||||
sqxtn2 v2.16b, v16.8h
|
||||
sqxtn v3.8b, v17.8h
|
||||
sqxtn2 v3.16b, v18.8h
|
||||
sqxtn v4.8b, v19.8h
|
||||
sqxtn2 v4.16b, v20.8h
|
||||
sqxtn v5.8b, v21.8h
|
||||
sqxtn2 v5.16b, v22.8h
|
||||
sqxtn v6.8b, v23.8h
|
||||
sqxtn2 v6.16b, v24.8h
|
||||
sqxtn v7.8b, v25.8h
|
||||
sqxtn2 v7.16b, v26.8h
|
||||
|
||||
st1 {v27.16b, v28.16b, v29.16b, v30.16b}, [x10], #64
|
||||
st1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x10], #64
|
||||
st1 {v4.16b, v5.16b, v6.16b, v7.16b}, [x10], x15
|
||||
|
||||
subs x12, x12, #1
|
||||
bne LoopSz_24
|
||||
|
||||
Tile24End:
|
||||
sub x4, x4, #24 // batch -= 24
|
||||
add x0, x0, #384 // src += 24 * 8 * sizeof(float16_t)
|
||||
add x1, x1, #192 // dst += 24 * 8 * sizeof(int8_t)
|
||||
b TILE_24
|
||||
|
||||
TILE_16:
|
||||
cmp x4, #16
|
||||
blt TILE_12
|
||||
mov x9, x0 // src
|
||||
mov x10, x1 // dst
|
||||
sub x15, x6, #64
|
||||
mov x12, x3 // src_depth_quad
|
||||
sub x13, x7, #192 // src_step - 192
|
||||
|
||||
ld1 {v12.4s, v13.4s, v14.4s, v15.4s}, [x2], #64
|
||||
fcvtn v12.4h, v12.4s
|
||||
fcvtn2 v12.8h, v13.4s
|
||||
fcvtn v13.4h, v14.4s
|
||||
fcvtn2 v13.8h, v15.4s
|
||||
|
||||
LoopSz_16:
|
||||
ld1 {v0.8h, v1.8h, v2.8h, v3.8h}, [x9], #64
|
||||
ld1 {v4.8h, v5.8h, v6.8h, v7.8h}, [x9], #64
|
||||
ld1 {v8.8h, v9.8h, v10.8h, v11.8h}, [x9], #64
|
||||
ld1 {v15.8h, v16.8h, v17.8h, v18.8h}, [x9], x13
|
||||
|
||||
// float16_t x = x * quant_scale
|
||||
fmul v0.8h, v0.8h, v12.h[0]
|
||||
fmul v1.8h, v1.8h, v12.h[1]
|
||||
fmul v2.8h, v2.8h, v12.h[2]
|
||||
fmul v3.8h, v3.8h, v12.h[3]
|
||||
fmul v4.8h, v4.8h, v12.h[4]
|
||||
fmul v5.8h, v5.8h, v12.h[5]
|
||||
fmul v6.8h, v6.8h, v12.h[6]
|
||||
fmul v7.8h, v7.8h, v12.h[7]
|
||||
fmul v8.8h, v8.8h, v13.h[0]
|
||||
fmul v9.8h, v9.8h, v13.h[1]
|
||||
fmul v10.8h, v10.8h, v13.h[2]
|
||||
fmul v11.8h, v11.8h, v13.h[3]
|
||||
fmul v15.8h, v15.8h, v13.h[4]
|
||||
fmul v16.8h, v16.8h, v13.h[5]
|
||||
fmul v17.8h, v17.8h, v13.h[6]
|
||||
fmul v18.8h, v18.8h, v13.h[7]
|
||||
|
||||
// int16_t x = round(x)
|
||||
Round v0, v1, v2, v3
|
||||
Round v4, v5, v6, v7
|
||||
Round v8, v9, v10, v11
|
||||
Round v15, v16, v17, v18
|
||||
|
||||
// y = (int8_t)x
|
||||
sqxtn v19.8b, v0.8h
|
||||
sqxtn2 v19.16b, v1.8h
|
||||
sqxtn v20.8b, v2.8h
|
||||
sqxtn2 v20.16b, v3.8h
|
||||
sqxtn v21.8b, v4.8h
|
||||
sqxtn2 v21.16b, v5.8h
|
||||
sqxtn v22.8b, v6.8h
|
||||
sqxtn2 v22.16b, v7.8h
|
||||
sqxtn v23.8b, v8.8h
|
||||
sqxtn2 v23.16b, v9.8h
|
||||
sqxtn v24.8b, v10.8h
|
||||
sqxtn2 v24.16b, v11.8h
|
||||
sqxtn v25.8b, v15.8h
|
||||
sqxtn2 v25.16b, v16.8h
|
||||
sqxtn v26.8b, v17.8h
|
||||
sqxtn2 v26.16b, v18.8h
|
||||
|
||||
st1 {v19.16b, v20.16b, v21.16b, v22.16b}, [x10], #64
|
||||
st1 {v23.16b, v24.16b, v25.16b, v26.16b}, [x10], x15
|
||||
|
||||
subs x12, x12, #1
|
||||
bne LoopSz_16
|
||||
|
||||
Tile16End:
|
||||
sub x4, x4, #16 // batch -= 16
|
||||
add x0, x0, #256 // src += 16 * 8 * sizeof(float16_t)
|
||||
add x1, x1, #128 // dst += 16 * 8 * sizeof(int8_t)
|
||||
b TILE_16
|
||||
|
||||
TILE_12:
|
||||
cmp x4, #12
|
||||
blt TILE_10
|
||||
mov x9, x0 // src
|
||||
mov x10, x1 // dst
|
||||
mov x15, x11 // second dst
|
||||
sub x15, x6, #64
|
||||
mov x12, x3 // src_depth_quad
|
||||
sub x13, x7, #128 // src_step - 64
|
||||
sub x13, x7, #128 // src_step - 128
|
||||
|
||||
// quant_scale: v12, v13, v14
|
||||
// ld1 {v12.8h}, [x2], #16
|
||||
// ld1 {v13.d}[0], [x2], #8
|
||||
ld1 {v12.4s, v13.4s, v14.4s}, [x2], #48
|
||||
fcvtn v12.4h, v12.4s
|
||||
fcvtn2 v12.8h, v13.4s
|
||||
|
|
@ -78,31 +246,21 @@ Round v4, v5, v6, v7
|
|||
Round v8, v9, v10, v11
|
||||
|
||||
// y = (int8_t)x
|
||||
sqxtn v0.8b, v0.8h
|
||||
sqxtn2 v0.16b, v1.8h
|
||||
sqxtn v1.8b, v2.8h
|
||||
sqxtn2 v1.16b, v3.8h
|
||||
sqxtn v2.8b, v4.8h
|
||||
sqxtn2 v2.16b, v5.8h
|
||||
sqxtn v3.8b, v6.8h
|
||||
sqxtn2 v3.16b, v7.8h
|
||||
sqxtn v4.8b, v8.8h
|
||||
sqxtn2 v4.16b, v9.8h
|
||||
sqxtn v5.8b, v10.8h
|
||||
sqxtn2 v5.16b, v11.8h
|
||||
sqxtn v14.8b, v0.8h
|
||||
sqxtn2 v14.16b, v1.8h
|
||||
sqxtn v15.8b, v2.8h
|
||||
sqxtn2 v15.16b, v3.8h
|
||||
sqxtn v16.8b, v4.8h
|
||||
sqxtn2 v16.16b, v5.8h
|
||||
sqxtn v17.8b, v6.8h
|
||||
sqxtn2 v17.16b, v7.8h
|
||||
sqxtn v18.8b, v8.8h
|
||||
sqxtn2 v18.16b, v9.8h
|
||||
sqxtn v19.8b, v10.8h
|
||||
sqxtn2 v19.16b, v11.8h
|
||||
|
||||
uzp1 v6.4s, v0.4s, v1.4s
|
||||
uzp1 v7.4s, v2.4s, v3.4s
|
||||
uzp1 v8.4s, v4.4s, v5.4s
|
||||
uzp2 v9.4s, v0.4s, v1.4s
|
||||
uzp2 v10.4s, v2.4s, v3.4s
|
||||
uzp2 v11.4s, v4.4s, v5.4s
|
||||
|
||||
st1 {v6.16b, v7.16b, v8.16b}, [x10], x6
|
||||
st1 {v9.16b, v10.16b, v11.16b}, [x15], x6
|
||||
|
||||
//st1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x10], #64
|
||||
//st1 {v4.16b, v5.16b}, [x10], x14
|
||||
st1 {v14.16b, v15.16b, v16.16b, v17.16b}, [x10], #64
|
||||
st1 {v18.16b, v19.16b}, [x10], x15
|
||||
|
||||
subs x12, x12, #1
|
||||
bne LoopSz_12
|
||||
|
|
@ -110,8 +268,7 @@ bne LoopSz_12
|
|||
Tile12End:
|
||||
sub x4, x4, #12 // batch -= 12
|
||||
add x0, x0, #192 // src += 12 * 8 * sizeof(float16_t)
|
||||
add x1, x1, #48 // dst += 12 * 4 * sizeof(int8_t)
|
||||
add x11, x11, #48
|
||||
add x1, x1, #96 // dst += 12 * 8 * sizeof(int8_t)
|
||||
b TILE_12
|
||||
|
||||
TILE_10:
|
||||
|
|
@ -119,7 +276,6 @@ cmp x4, #10
|
|||
blt TILE_8
|
||||
mov x9, x0 // src
|
||||
mov x10, x1 // dst
|
||||
mov x15, x11 // second dst
|
||||
mov x12, x3 // src_depth_quad
|
||||
sub x13, x7, #128 // src_step - 128
|
||||
sub x14, x6, #32 // dst_step - 32
|
||||
|
|
@ -168,19 +324,9 @@ sqxtn2 v3.16b, v7.8h
|
|||
sqxtn v4.8b, v8.8h
|
||||
sqxtn2 v4.16b, v9.8h
|
||||
|
||||
uzp1 v6.4s, v0.4s, v1.4s // 0 1 2 3
|
||||
uzp1 v7.4s, v2.4s, v3.4s // 4 5 6 7
|
||||
uzp1 v8.4s, v4.4s, v4.4s // 8 9 8 9
|
||||
uzp2 v12.4s, v0.4s, v1.4s
|
||||
uzp2 v13.4s, v2.4s, v3.4s
|
||||
uzp2 v14.4s, v4.4s, v4.4s
|
||||
st1 {v6.16b, v7.16b}, [x10], #32
|
||||
st1 {v8.d}[0], [x10], x14
|
||||
st1 {v12.16b, v13.16b}, [x15], #32
|
||||
st1 {v14.d}[0], [x15], x14
|
||||
st1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x10], #64
|
||||
st1 {v4.16b}, [x10], x15
|
||||
|
||||
// st1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x10], #64
|
||||
// st1 {v4.16b}, [x10], x14
|
||||
|
||||
subs x12, x12, #1
|
||||
bne LoopSz_10
|
||||
|
|
@ -188,8 +334,7 @@ bne LoopSz_10
|
|||
Tile10End:
|
||||
sub x4, x4, #10 // batch -= 10
|
||||
add x0, x0, #160 // src += 10 * 8 * sizeof(float16_t)
|
||||
add x1, x1, #40 // dst += 10 * 4 * sizeof(int8_t)
|
||||
add x11, x11, #40
|
||||
add x1, x1, #80 // dst += 10 * 4 * sizeof(int8_t)
|
||||
b TILE_10
|
||||
|
||||
|
||||
|
|
@ -199,7 +344,6 @@ blt TILE_1
|
|||
sub x8, x7, #64 // src_step - 64
|
||||
mov x9, x0 // src
|
||||
mov x10, x1 // dst
|
||||
mov x15, x11 // second dst
|
||||
mov x12, x3 // src_depth_quad
|
||||
|
||||
// quant_scale: v8
|
||||
|
|
@ -236,13 +380,7 @@ sqxtn2 v11.16b, v5.8h
|
|||
sqxtn v12.8b, v6.8h
|
||||
sqxtn2 v12.16b, v7.8h
|
||||
|
||||
uzp1 v6.4s, v9.4s, v10.4s // 0 1 2 3 first
|
||||
uzp1 v7.4s, v11.4s, v12.4s // 4 5 6 7
|
||||
uzp2 v14.4s, v9.4s, v10.4s // 0 1 2 3 second
|
||||
uzp2 v15.4s, v11.4s, v12.4s // 4 5 6 7
|
||||
st1 {v6.16b, v7.16b}, [x10], x6
|
||||
st1 {v14.16b, v15.16b}, [x15], x6
|
||||
//st1 {v9.16b, v10.16b, v11.16b, v12.16b}, [x10], x6
|
||||
st1 {v9.16b, v10.16b, v11.16b, v12.16b}, [x10], x6
|
||||
|
||||
subs x12, x12, #1
|
||||
bne LoopSz_8
|
||||
|
|
@ -250,8 +388,7 @@ bne LoopSz_8
|
|||
Tile8End:
|
||||
sub x4, x4, #8 // batch -= 8
|
||||
add x0, x0, #128 // src += 8 * 8 * sizeof(float16_t)
|
||||
add x1, x1, #32 // dst += 8 * 4 * sizeof(int8_t)
|
||||
add x11, x11, #32
|
||||
add x1, x1, #64 // dst += 8 * 8 * sizeof(int8_t)
|
||||
b TILE_8
|
||||
|
||||
TILE_4:
|
||||
|
|
@ -259,7 +396,6 @@ cmp x4, #4
|
|||
blt TILE_2
|
||||
mov x9, x0 // src
|
||||
mov x10, x1 // dst
|
||||
mov x15, x11 // second dst
|
||||
mov x12, x3 // src_depth_quad
|
||||
|
||||
// quant_scale: v8
|
||||
|
|
@ -285,11 +421,7 @@ sqxtn2 v4.16b, v1.8h
|
|||
sqxtn v5.8b, v2.8h
|
||||
sqxtn2 v5.16b, v3.8h
|
||||
|
||||
uzp1 v6.4s, v4.4s, v5.4s // 0 1 2 3 first
|
||||
uzp2 v14.4s, v4.4s, v5.4s // 0 1 2 3 second
|
||||
st1 {v6.16b}, [x10], x6
|
||||
st1 {v14.16b}, [x15], x6
|
||||
//st1 {v4.16b, v5.16b}, [x10], x6
|
||||
st1 {v4.16b, v5.16b}, [x10], x6
|
||||
|
||||
subs x12, x12, #1
|
||||
bne LoopSz_4
|
||||
|
|
@ -297,8 +429,7 @@ bne LoopSz_4
|
|||
Tile4End:
|
||||
sub x4, x4, #4 // batch -= 4
|
||||
add x0, x0, #64 // src += 4 * 8 * sizeof(float16_t)
|
||||
add x1, x1, #16 // dst += 4 * 4 * sizeof(int8_t)
|
||||
add x11, x11, #16
|
||||
add x1, x1, #32 // dst += 4 * 8 * sizeof(int8_t)
|
||||
b TILE_4
|
||||
|
||||
|
||||
|
|
@ -307,7 +438,6 @@ cmp x4, #2
|
|||
blt TILE_1
|
||||
mov x9, x0 // src
|
||||
mov x10, x1 // dst
|
||||
mov x15, x11 // second dst
|
||||
mov x12, x3 // src_depth_quad
|
||||
|
||||
// quant_scale: v8
|
||||
|
|
@ -330,9 +460,7 @@ fcvtas v1.8h, v1.8h
|
|||
sqxtn v2.8b, v0.8h
|
||||
sqxtn2 v2.16b, v1.8h
|
||||
|
||||
st1 {v2.d}[0], [x10], x6
|
||||
st1 {v2.d}[1], [x15], x6
|
||||
//st1 {v2.16b}, [x10], x6
|
||||
st1 {v2.16b}, [x10], x6
|
||||
|
||||
subs x12, x12, #1
|
||||
bne LoopSz_2
|
||||
|
|
@ -340,8 +468,7 @@ bne LoopSz_2
|
|||
Tile2End:
|
||||
sub x4, x4, #2 // batch -= 2
|
||||
add x0, x0, #32 // src += 2 * 8 * sizeof(float16_t)
|
||||
add x1, x1, #8 // dst += 2 * 4 * sizeof(int8_t)
|
||||
add x11, x11, #8
|
||||
add x1, x1, #16 // dst += 2 * 8 * sizeof(int8_t)
|
||||
b TILE_2
|
||||
|
||||
|
||||
|
|
@ -350,7 +477,6 @@ cmp x4, #1
|
|||
blt End
|
||||
mov x9, x0 // src
|
||||
mov x10, x1 // dst
|
||||
mov x15, x11 // second dst
|
||||
mov x12, x3 // src_depth_quad
|
||||
|
||||
// quant_scale: v8
|
||||
|
|
@ -368,8 +494,7 @@ fcvtas v0.8h, v0.8h
|
|||
// y = (int8_t)x
|
||||
sqxtn v0.8b, v0.8h
|
||||
|
||||
st1 {v0.s}[0], [x10], x6
|
||||
st1 {v0.s}[1], [x15], x6
|
||||
st1 {v0.8b}, [x10], x6
|
||||
|
||||
subs x12, x12, #1
|
||||
bne LoopSz_1
|
||||
|
|
@ -377,8 +502,7 @@ bne LoopSz_1
|
|||
Tile1End:
|
||||
sub x4, x4, #1 // batch -= 1
|
||||
add x0, x0, #16 // src += 1 * 8 * sizeof(float16_t)
|
||||
add x1, x1, #4 // dst += 1 * 4 * sizeof(int8_t)
|
||||
add x11, x11, #4
|
||||
add x1, x1, #8 // dst += 1 * 8 * sizeof(int8_t)
|
||||
b TILE_1
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -114,7 +114,7 @@ ldr x23, [x6, #56] // fp32minmax
|
|||
mov x21, #16 // sizeof(float16_t) * PACK
|
||||
Start:
|
||||
lsl x15, x3, #5 // x15 = src_depth_quad * UNIT * SRC_UNIT
|
||||
mov x22, #48 // src_steps
|
||||
lsl x22, x7, #2 // src_steps
|
||||
ldr x27, [x6, #80] // extra scale
|
||||
TILE_12:
|
||||
cmp x7, #12
|
||||
|
|
|
|||
|
|
@ -113,7 +113,7 @@ ldr x23, [x6, #56] // fp32minmax
|
|||
mov x21, #16 // sizeof(float16_t) * PACK
|
||||
Start:
|
||||
lsl x15, x3, #4 // x15 = src_depth_quad * UNIT * SRC_UNIT * sizeof(int4_t)
|
||||
mov x22, #48 // src_steps
|
||||
lsl x22, x7, #2 // src_steps
|
||||
ldr x27, [x6, #80] // extra scale
|
||||
TILE_12:
|
||||
cmp x7, #12
|
||||
|
|
@ -572,15 +572,71 @@ L8LoopDz_TILE_1:
|
|||
movi v9.16b, #0
|
||||
|
||||
mov x28, x12
|
||||
cmp x22, #4
|
||||
bne L8LoopSz_TILE_1_lu1
|
||||
cmp x13, #4
|
||||
blt L8LoopSz_TILE_1_lu1
|
||||
cmp x13, #8
|
||||
blt L8LoopSz_TILE_1_lu4
|
||||
L8LoopSz_TILE_1_lu8:
|
||||
ld1 {v3.16b, v4.16b, v5.16b, v6.16b}, [x12], #64 // weight: hu=0,1,2,3,pack=0~7
|
||||
ld1 {v10.16b, v11.16b, v12.16b, v13.16b}, [x12], #64
|
||||
ld1 {v0.4s, v1.4s}, [x11], #32 // src
|
||||
|
||||
sub x13, x13, #8
|
||||
// int4->int8
|
||||
ushr v14.16b, v3.16b, #4
|
||||
and v22.16b, v3.16b, v7.16b
|
||||
|
||||
ushr v15.16b, v4.16b, #4
|
||||
and v23.16b, v4.16b, v7.16b
|
||||
|
||||
ushr v18.16b, v5.16b, #4
|
||||
and v24.16b, v5.16b, v7.16b
|
||||
|
||||
ushr v21.16b, v6.16b, #4
|
||||
and v25.16b, v6.16b, v7.16b
|
||||
|
||||
ushr v16.16b, v10.16b, #4
|
||||
and v17.16b, v10.16b, v7.16b
|
||||
|
||||
ushr v19.16b, v11.16b, #4
|
||||
and v20.16b, v11.16b, v7.16b
|
||||
|
||||
ushr v26.16b, v12.16b, #4
|
||||
and v27.16b, v12.16b, v7.16b
|
||||
|
||||
ushr v28.16b, v13.16b, #4
|
||||
and v29.16b, v13.16b, v7.16b
|
||||
|
||||
cmp x13, #8
|
||||
//sub x12, x12, x15
|
||||
.inst 0x4f80e1c8 // sdot v8.4s, v14.16b, v0.4b[0]
|
||||
.inst 0x4f80e2c9 // sdot v9.4s, v22.16b, v0.4b[0]
|
||||
.inst 0x4fa0e1e8 // sdot v8.4s, v15.16b, v0.4b[1]
|
||||
.inst 0x4fa0e2e9 // sdot v9.4s, v23.16b, v0.4b[1]
|
||||
.inst 0x4f80ea48 // sdot v8.4s, v18.16b, v0.4b[2]
|
||||
.inst 0x4f80eb09 // sdot v9.4s, v24.16b, v0.4b[2]
|
||||
.inst 0x4fa0eaa8 // sdot v8.4s, v21.16b, v0.4b[3]
|
||||
.inst 0x4fa0eb29 // sdot v9.4s, v25.16b, v0.4b[3]
|
||||
|
||||
.inst 0x4f81e208 // sdot v8.4s, v16.16b, v1.4b[0]
|
||||
.inst 0x4f81e229 // sdot v9.4s, v17.16b, v1.4b[0]
|
||||
.inst 0x4fa1e268 // sdot v8.4s, v19.16b, v1.4b[1]
|
||||
.inst 0x4fa1e289 // sdot v9.4s, v20.16b, v1.4b[1]
|
||||
.inst 0x4f81eb48 // sdot v8.4s, v26.16b, v1.4b[2]
|
||||
.inst 0x4f81eb69 // sdot v9.4s, v27.16b, v1.4b[2]
|
||||
.inst 0x4fa1eb88 // sdot v8.4s, v28.16b, v1.4b[3]
|
||||
.inst 0x4fa1eba9 // sdot v9.4s, v29.16b, v1.4b[3]
|
||||
bge L8LoopSz_TILE_1_lu8
|
||||
|
||||
cbz x13, L8LoopSzEnd_TILE_1
|
||||
cmp x13, #4
|
||||
blt L8LoopSz_TILE_1_lu1
|
||||
|
||||
L8LoopSz_TILE_1_lu4:
|
||||
ld1 {v3.16b, v4.16b, v5.16b, v6.16b}, [x12], #64 // weight: hu=0,1,2,3,pack=0~7
|
||||
ld1 {v0.s}[0], [x11], x22 // src
|
||||
ld1 {v0.s}[1], [x11], x22
|
||||
ld1 {v0.s}[2], [x11], x22
|
||||
ld1 {v0.s}[3], [x11], x22
|
||||
ld1 {v0.4s}, [x11], #16 // src
|
||||
|
||||
sub x13, x13, #4
|
||||
// int4->int8
|
||||
|
|
|
|||
|
|
@ -152,7 +152,7 @@ ldr x27, [x6, #40] // srcKernelSum
|
|||
ldr x28, [x6, #48] // weightQuanBias
|
||||
ldr x14, [x6, #56] // fp32minmax
|
||||
|
||||
mov x22, #80 // GEMM_INT8_DST_XUNIT * GEMM_INT8_SRC_UNIT = 10 * 8 = 80
|
||||
lsl x22, x7, #3 // eDest * GEMM_INT8_SRC_UNIT
|
||||
mov x21, #16 // sizeof(float16_t) * UNIT
|
||||
|
||||
Start:
|
||||
|
|
|
|||
|
|
@ -132,7 +132,7 @@ ldr x27, [x6, #40] // srcKernelSum
|
|||
ldr x28, [x6, #48] // weightQuanBias
|
||||
ldr x14, [x6, #56] // fp32minmax
|
||||
|
||||
mov x22, #80 // GEMM_INT8_DST_XUNIT * GEMM_INT8_SRC_UNIT = 10 * 8 = 80
|
||||
lsl x22, x7, #3 // eDest * GEMM_INT8_SRC_UNIT
|
||||
mov x21, #16 // sizeof(float16_t) * UNIT
|
||||
|
||||
Start:
|
||||
|
|
@ -771,15 +771,15 @@ LoopDz_TILE_1:
|
|||
movi v18.4s, #0 // oc:4,5,4,5
|
||||
movi v19.4s, #0 // oc:6,7,6,7
|
||||
|
||||
cmp x22, #8
|
||||
bne LoopSz1_TILE_1_lu1
|
||||
cmp x13, #4
|
||||
blt LoopSz1_TILE_1_lu1
|
||||
|
||||
LoopSz1_TILE_1_lu4:
|
||||
ld1 {v5.16b, v6.16b, v7.16b, v8.16b}, [x12], #64 // weight
|
||||
ld1 {v9.16b, v10.16b, v11.16b, v12.16b}, [x12], #64
|
||||
ld1 {v0.8b}, [x11], x22 // src
|
||||
ld1 {v1.8b}, [x11], x22
|
||||
ld1 {v2.8b}, [x11], x22
|
||||
ld1 {v3.8b}, [x11], x22
|
||||
ld1 {v0.8b, v1.8b, v2.8b, v3.8b}, [x11], #32 // src
|
||||
|
||||
// int4->int8
|
||||
ushr v4.16b, v5.16b, #4
|
||||
|
|
|
|||
|
|
@ -31,6 +31,8 @@ stp d8, d9, [sp, #(16 * 3)]
|
|||
Start:
|
||||
movi v31.4s, #127
|
||||
scvtf v31.4s, v31.4s
|
||||
fcvtn v30.4h, v31.4s
|
||||
dup v30.2d, v30.d[0]
|
||||
//fcvtn v31.4h, v0.4s
|
||||
//fcvtn2 v31.8h, v0.4s
|
||||
lsl x9, x4, #1 // src_step = batch * sizeof(float16_t)
|
||||
|
|
@ -65,6 +67,10 @@ add x0, x0, #24
|
|||
// quant_scale = 127 / absmax
|
||||
// dequant_scale = absmax / 127
|
||||
|
||||
fcmle v28.8h, v0.8h, #0
|
||||
fcmle v29.4h, v1.4h, #0
|
||||
bit v0.16b, v30.16b, v28.16b
|
||||
bit v1.16b, v30.16b, v29.16b
|
||||
// float16->float32
|
||||
fcvtl v4.4s, v0.4h
|
||||
fcvtl2 v5.4s, v0.8h
|
||||
|
|
@ -122,6 +128,10 @@ add x0, x0, #20
|
|||
// quant_scale = 127 / absmax
|
||||
// dequant_scale = absmax / 127
|
||||
|
||||
fcmle v28.8h, v0.8h, #0
|
||||
fcmle v29.4h, v1.4h, #0
|
||||
bit v0.16b, v30.16b, v28.16b
|
||||
bit v1.16b, v30.16b, v29.16b
|
||||
// float16->float32
|
||||
fcvtl v4.4s, v0.4h
|
||||
fcvtl2 v5.4s, v0.8h
|
||||
|
|
@ -140,14 +150,6 @@ st1 {v10.d}[0], [x1], #8
|
|||
st1 {v12.4s, v13.4s}, [x2], #32
|
||||
st1 {v14.d}[0], [x2], #8
|
||||
|
||||
// fdiv v4.8h, v31.8h, v0.8h
|
||||
// fdiv v5.8h, v31.8h, v1.8h
|
||||
// fdiv v6.8h, v0.8h, v31.8h
|
||||
// fdiv v7.8h, v1.8h, v31.8h
|
||||
// st1 {v4.8h}, [x1], #16
|
||||
// st1 {v5.s}[0], [x1], #4
|
||||
// st1 {v6.8h}, [x2], #16
|
||||
// st1 {v7.s}[0], [x2], #4
|
||||
b TILE_10
|
||||
|
||||
|
||||
|
|
@ -176,6 +178,8 @@ sub x4, x4, #8
|
|||
add x0, x0, #16
|
||||
// quant_scale = 127 / absmax
|
||||
// dequant_scale = absmax / 127
|
||||
fcmle v28.8h, v0.8h, #0
|
||||
bit v0.16b, v30.16b, v28.16b
|
||||
// float16->float32
|
||||
fcvtl v4.4s, v0.4h
|
||||
fcvtl2 v5.4s, v0.8h
|
||||
|
|
@ -189,10 +193,6 @@ fdiv v13.4s, v5.4s, v31.4s
|
|||
st1 {v8.4s, v9.4s}, [x1], #32
|
||||
st1 {v12.4s, v13.4s}, [x2], #32
|
||||
|
||||
// fdiv v2.8h, v31.8h, v0.8h
|
||||
// fdiv v3.8h, v0.8h, v31.8h
|
||||
// st1 {v2.8h}, [x1], #16
|
||||
// st1 {v3.8h}, [x2], #16
|
||||
b TILE_8
|
||||
|
||||
|
||||
|
|
@ -221,6 +221,8 @@ sub x4, x4, #1
|
|||
add x0, x0, #2
|
||||
// quant_scale = 127 / absmax
|
||||
// dequant_scale = absmax / 127
|
||||
fcmle v28.8h, v0.8h, #0
|
||||
bit v0.16b, v30.16b, v28.16b
|
||||
fcvtl v4.4s, v0.4h
|
||||
|
||||
fdiv v8.4s, v31.4s, v4.4s
|
||||
|
|
@ -229,10 +231,6 @@ fdiv v12.4s, v4.4s, v31.4s
|
|||
st1 {v8.s}[0], [x1], #4
|
||||
st1 {v12.s}[0], [x2], #4
|
||||
|
||||
// fdiv h2, h31, h0
|
||||
// fdiv h3, h0, h31
|
||||
// st1 {v2.h}[0], [x1], #2
|
||||
// st1 {v3.h}[0], [x2], #2
|
||||
b TILE_1
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -10,20 +10,6 @@ ELSE()
|
|||
SET(METAL_SDK_PLAT "macosx")
|
||||
ENDIF()
|
||||
|
||||
message(STATUS "Compiling CoreML Metal Kernels with ${METAL_SDK_PLAT} SDK")
|
||||
|
||||
message(STATUS "Generating coreml.metallib at ${PROJECT_BINARY_DIR}/coreml.metallib")
|
||||
|
||||
add_custom_command(OUTPUT ${PROJECT_BINARY_DIR}/coreml.metallib
|
||||
COMMAND xcrun -sdk ${METAL_SDK_PLAT}
|
||||
metal "${MNN_COREML_METAL_SRCS}"
|
||||
-o ${PROJECT_BINARY_DIR}/coreml.metallib
|
||||
COMMAND_EXPAND_LISTS)
|
||||
|
||||
add_custom_target(MNNCoreMLMetalLib DEPENDS
|
||||
${PROJECT_BINARY_DIR}/coreml.metallib
|
||||
COMMENT "Generating coreml.metallib")
|
||||
|
||||
# CoreML
|
||||
file(GLOB MNN_COREML_SRCS
|
||||
${CMAKE_CURRENT_LIST_DIR}/backend/*.cpp
|
||||
|
|
@ -37,10 +23,10 @@ file(GLOB MNN_COREML_SRCS
|
|||
|
||||
add_library(
|
||||
MNNCoreML
|
||||
STATIC
|
||||
OBJECT
|
||||
${MNN_COREML_SRCS}
|
||||
${MNNCoreMLMetalLib}
|
||||
)
|
||||
set_property(TARGET MNNCoreML APPEND_STRING PROPERTY COMPILE_FLAGS "-fobjc-arc")
|
||||
|
||||
target_include_directories(MNNCoreML PRIVATE
|
||||
${CMAKE_CURRENT_LIST_DIR}/mlmodel/include
|
||||
|
|
@ -48,4 +34,3 @@ target_include_directories(MNNCoreML PRIVATE
|
|||
${CMAKE_CURRENT_LIST_DIR}/execution
|
||||
)
|
||||
|
||||
add_dependencies(MNNCoreML MNNCoreMLMetalLib)
|
||||
|
|
|
|||
|
|
@ -35,8 +35,9 @@ namespace MNN {
|
|||
|
||||
CoreMLBackend::CoreMLBackend(const CoreMLRuntime* runtime) : Backend(MNN_FORWARD_NN) {
|
||||
mNPURuntime = runtime;
|
||||
mInputBuffer.root = BufferAllocator::Allocator::createDefault();
|
||||
mPrecision = mNPURuntime->mPrecision;
|
||||
mCoreMLExecutor.reset(new CoreMLExecutorWrapper);
|
||||
mCoreMLExecutor.reset(new CoreMLExecutorWrapper(mPrecision));
|
||||
if (mCoreMLModel_ == nullptr) {
|
||||
mCoreMLModel_.reset(new _CoreML__Specification__Model);
|
||||
core_ml__specification__model__init(mCoreMLModel_.get());
|
||||
|
|
@ -81,20 +82,11 @@ namespace MNN {
|
|||
Backend::MemObj* CoreMLBackend::onAcquire(const Tensor* tensor, StorageType storageType) {
|
||||
bool isInputCopy = TensorUtils::getDescribe(tensor)->usage==Tensor::InsideDescribe::Usage::INPUT;
|
||||
bool isOutputCopy = TensorUtils::getDescribe(tensor)->usage==Tensor::InsideDescribe::Usage::OUTPUT;
|
||||
// using CvPixelBuffer as input and output
|
||||
if (mPrecision == BackendConfig::Precision_Low) {
|
||||
const_cast<Tensor*>(tensor)->setType(DataType_DT_UINT8);
|
||||
}
|
||||
if(isInputCopy){
|
||||
mInputIdxMap.insert(std::make_pair(tensor, mInputIdxMap.size()));
|
||||
}
|
||||
if(isOutputCopy){
|
||||
mOutputIdxMap.insert(std::make_pair(tensor, mOutputIdxMap.size()));
|
||||
if (mPrecision == BackendConfig::Precision_Low) {
|
||||
TensorUtils::getDescribe(tensor)->memoryType = Tensor::InsideDescribe::MEMORY_HOST;
|
||||
const_cast<halide_buffer_t&>(tensor->buffer()).host = (uint8_t*)MNNMemoryAllocAlign(tensor->size(), MNN_MEMORY_ALIGN_DEFAULT);
|
||||
MNN_ASSERT(tensor->buffer().host != nullptr);
|
||||
}
|
||||
}
|
||||
// Don't need release
|
||||
return new Backend::MemObj;
|
||||
|
|
@ -105,31 +97,81 @@ namespace MNN {
|
|||
}
|
||||
|
||||
void CoreMLBackend::onCopyBuffer(const Tensor* srcTensor, const Tensor* dstTensor) const {
|
||||
if (nullptr == srcTensor->buffer().host || nullptr == dstTensor->buffer().host) {
|
||||
MNN_ERROR("[MNN-CoreML]: Invalid copy because not valid input / output\n");
|
||||
return;
|
||||
}
|
||||
|
||||
bool isInputCopy = TensorUtils::getDescribe(dstTensor)->usage==Tensor::InsideDescribe::Usage::INPUT;
|
||||
bool isOutputCopy = TensorUtils::getDescribe(srcTensor)->usage==Tensor::InsideDescribe::Usage::OUTPUT;
|
||||
bool isConst = TensorUtils::getDescribe(srcTensor)->usage==Tensor::InsideDescribe::Usage::CONSTANT || TensorUtils::getDescribe(dstTensor)->usage==Tensor::InsideDescribe::Usage::CONSTANT;
|
||||
|
||||
if(isConst){ return; }
|
||||
|
||||
if ((isInputCopy || isOutputCopy) && mPrecision == BackendConfig::Precision_Low) {
|
||||
// TODO: Fix bug for int8 with nc4hw4
|
||||
::memcpy(dstTensor->host<void>(), srcTensor->host<void>(),TensorUtils::getRawSize(srcTensor) * sizeof(uint8_t));
|
||||
return;
|
||||
}
|
||||
if (isInputCopy) {
|
||||
const auto iter = mInputIdxMap.find(dstTensor);
|
||||
MNN_ASSERT(iter != mInputIdxMap.end());
|
||||
memcpy((void*)&mInputTensors[iter->second], &srcTensor, sizeof(void*));
|
||||
} else if (isOutputCopy) {
|
||||
// MNN_ASSERT(mOutputIdxMap.find(srcTensor) != mOutputIdxMap.end());
|
||||
int srcSize = static_cast<int>(TensorUtils::getRawSize(srcTensor) * srcTensor->getType().bytes());
|
||||
memcpy(dstTensor->host<void>(), srcTensor->host<void>(), std::min(srcSize, dstTensor->size()));
|
||||
if (TensorUtils::getDescribe(dstTensor)->dimensionFormat == MNN_DATA_FORMAT_NC4HW4) {
|
||||
std::unique_ptr<Tensor> tmp(new Tensor(dstTensor, Tensor::CAFFE, false));
|
||||
tmp->buffer().host = dstTensor->buffer().host;
|
||||
MNNCPUCopyBuffer(srcTensor, tmp.get());
|
||||
} else {
|
||||
MNNCPUCopyBuffer(srcTensor, dstTensor);
|
||||
}
|
||||
return;
|
||||
}
|
||||
if(isOutputCopy) {
|
||||
if (TensorUtils::getDescribe(srcTensor)->dimensionFormat == MNN_DATA_FORMAT_NC4HW4) {
|
||||
std::unique_ptr<Tensor> tmp(new Tensor(srcTensor, Tensor::CAFFE, false));
|
||||
tmp->buffer().host = srcTensor->buffer().host;
|
||||
MNNCPUCopyBuffer(tmp.get(), dstTensor);
|
||||
} else {
|
||||
MNNCPUCopyBuffer(srcTensor, dstTensor);
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
void CoreMLBackend::onResizeBegin() {
|
||||
mCoreMLLayerPtrs.clear();
|
||||
}
|
||||
int CoreMLBackend::getBytes(const halide_type_t& type) {
|
||||
if (type.code == halide_type_float && mPrecision == BackendConfig::Precision_Low) {
|
||||
return 1;
|
||||
}
|
||||
return type.bytes();
|
||||
}
|
||||
|
||||
ErrorCode CoreMLBackend::onResizeEnd() {
|
||||
bool useImage = mPrecision == BackendConfig::Precision_Low;
|
||||
size_t allocSize = 0;
|
||||
for (auto t : mInputIdxMap) {
|
||||
allocSize += (TensorUtils::getRawSize(t.first) * getBytes(t.first->getType()));
|
||||
}
|
||||
if (useImage) {
|
||||
for (auto t : mOutputIdxMap) {
|
||||
allocSize += (TensorUtils::getRawSize(t.first) * getBytes(t.first->getType()));
|
||||
}
|
||||
}
|
||||
auto code = mInputBuffer.realloc(allocSize, MNN_MEMORY_ALIGN_DEFAULT);
|
||||
if (NO_ERROR != code) {
|
||||
return code;
|
||||
}
|
||||
allocSize = 0;
|
||||
auto ptr = mInputBuffer.current.ptr();
|
||||
for (auto tt : mInputIdxMap) {
|
||||
auto t = (Tensor*)tt.first;
|
||||
t->buffer().host = ptr + allocSize;
|
||||
allocSize += (TensorUtils::getRawSize(t) * getBytes(t->getType()));
|
||||
}
|
||||
for (auto tt : mOutputIdxMap) {
|
||||
auto t = (Tensor*)tt.first;
|
||||
t->buffer().host = ptr + allocSize;
|
||||
allocSize += (TensorUtils::getRawSize(t) * getBytes(t->getType()));
|
||||
}
|
||||
return buildModel();
|
||||
}
|
||||
bool CoreMLBackend::onUnmapTensor(Tensor::MapType mtype, Tensor::DimensionType dtype, const Tensor* dstTensor, void* mapPtr) {
|
||||
return true;
|
||||
}
|
||||
|
||||
std::string CoreMLBackend::getTensorName(const Tensor* t) {
|
||||
const auto& iter = mTensorIdxMap.find(t);
|
||||
|
|
@ -196,6 +238,10 @@ namespace MNN {
|
|||
copyName(&(layer->output[i]), std::move(outputs[i]));
|
||||
}
|
||||
}
|
||||
void* CoreMLBackend::onMapTensor(Tensor::MapType mtype, Tensor::DimensionType dtype, const Tensor* srcTensor) {
|
||||
return srcTensor->host<void>();
|
||||
}
|
||||
|
||||
void CoreMLBackend::setIO(CoreML__Specification__FeatureDescription** describe, const Tensor* t) {
|
||||
auto name = getTensorName(t);
|
||||
auto des = create<CoreML__Specification__FeatureDescription>();
|
||||
|
|
@ -227,7 +273,6 @@ namespace MNN {
|
|||
*describe = des;
|
||||
}
|
||||
ErrorCode CoreMLBackend::buildModel() {
|
||||
mInputTensors.resize(mInputIdxMap.size());
|
||||
mCoreMLModel_->description = create<CoreML__Specification__ModelDescription>();
|
||||
core_ml__specification__model_description__init(mCoreMLModel_->description);
|
||||
mCoreMLModel_->description->n_input = mInputIdxMap.size();
|
||||
|
|
@ -270,12 +315,12 @@ namespace MNN {
|
|||
if (mCoreMLModel_->neuralnetwork->n_layers <= 0) {
|
||||
return;
|
||||
}
|
||||
std::vector<std::pair<const MNN::Tensor*, std::string>> inputs(mInputTensors.size()), outputs(mOutputIdxMap.size());
|
||||
std::vector<std::pair<const MNN::Tensor*, std::string>> inputs(mInputIdxMap.size()), outputs(mOutputIdxMap.size());
|
||||
// get names
|
||||
for (const auto& iter : mInputIdxMap) {
|
||||
auto t = iter.first;
|
||||
auto idx = iter.second;
|
||||
inputs[idx].first = mInputTensors[idx];
|
||||
inputs[idx].first = t;
|
||||
inputs[idx].second = std::to_string(mTensorIdxMap.find(t)->second);
|
||||
}
|
||||
for (const auto& iter : mOutputIdxMap) {
|
||||
|
|
|
|||
|
|
@ -19,6 +19,7 @@
|
|||
#include "MNN_generated.h"
|
||||
#include "Model.pb-c.h"
|
||||
#include "CoreMLExecutorWrapper.h"
|
||||
#include "core/BufferAllocator.hpp"
|
||||
|
||||
namespace MNN {
|
||||
class CoreMLRuntime : public Runtime {
|
||||
|
|
@ -49,6 +50,8 @@ namespace MNN {
|
|||
virtual ~CoreMLBackend();
|
||||
|
||||
virtual Execution* onCreate(const std::vector<Tensor*>& inputs, const std::vector<Tensor*>& outputs, const MNN::Op* op) override;
|
||||
virtual void* onMapTensor(Tensor::MapType mtype, Tensor::DimensionType dtype, const Tensor* srcTensor) override;
|
||||
virtual bool onUnmapTensor(Tensor::MapType mtype, Tensor::DimensionType dtype, const Tensor* dstTensor, void* mapPtr) override;
|
||||
|
||||
virtual void onExecuteBegin() const override;
|
||||
virtual void onExecuteEnd() const override;
|
||||
|
|
@ -104,6 +107,7 @@ namespace MNN {
|
|||
void setLayerOutputs(CoreML__Specification__NeuralNetworkLayer* layer, std::vector<std::string>&& outputs);
|
||||
void copyName(char** ptr, std::string&& name);
|
||||
int getInOutTensorInfo(std::string modelName);
|
||||
int getBytes(const halide_type_t& type);
|
||||
|
||||
class Creator {
|
||||
public:
|
||||
|
|
@ -117,12 +121,12 @@ namespace MNN {
|
|||
std::vector<CoreML__Specification__NeuralNetworkLayer*> mCoreMLLayerPtrs;
|
||||
|
||||
std::map<const Tensor*, int> mTensorIdxMap, mInputIdxMap, mOutputIdxMap;
|
||||
std::vector<const Tensor*> mInputTensors;
|
||||
std::vector<std::string> mModelName;
|
||||
std::vector<std::unique_ptr<float>> mInputData, mOutputData;
|
||||
const CoreMLRuntime* mNPURuntime;
|
||||
BackendConfig::PrecisionMode mPrecision;
|
||||
std::unique_ptr<CoreMLExecutorWrapper> mCoreMLExecutor;
|
||||
SingleBufferWithAllocator mInputBuffer;
|
||||
};
|
||||
|
||||
template <class T>
|
||||
|
|
|
|||
|
|
@ -32,11 +32,12 @@ struct Region {
|
|||
- (bool)build:(NSURL*)modelUrl API_AVAILABLE(ios(11));
|
||||
- (bool)cleanup;
|
||||
|
||||
@property int precision;
|
||||
@property MLModel* model API_AVAILABLE(ios(11));
|
||||
@property NSString* mlModelFilePath;
|
||||
@property NSString* compiledModelFilePath;
|
||||
@property(nonatomic, readonly) int coreMlVersion;
|
||||
@property __strong id<MLFeatureProvider> outputFeature API_AVAILABLE(ios(11));
|
||||
@property __strong NSMutableArray* outputArray;
|
||||
@end
|
||||
|
||||
// RasterLayer
|
||||
|
|
|
|||
|
|
@ -34,39 +34,14 @@ NSURL* createTemporaryFile() {
|
|||
NSURL* temporaryFileURL = [temporaryDirectoryURL URLByAppendingPathComponent:temporaryFilename];
|
||||
return temporaryFileURL;
|
||||
}
|
||||
static id<MTLComputePipelineState> rasterPipeline;
|
||||
id<MTLComputePipelineState> getRasterPipeline() {
|
||||
if (rasterPipeline == nil) {
|
||||
id device = MTLCreateSystemDefaultDevice();
|
||||
#if TARGET_OS_IOS
|
||||
NSString *path = [NSBundle.mainBundle pathForResource:@"coreml" ofType:@"metallib"];
|
||||
#else
|
||||
NSString *path = @"coreml.metallib";
|
||||
#endif
|
||||
NSError* error;
|
||||
id library = path ? [device newLibraryWithFile:path error:&error] : [device newDefaultLibrary];
|
||||
if (error) {
|
||||
printf("[METAL] create library error: %s\n", error.localizedDescription.UTF8String);
|
||||
return nullptr;
|
||||
}
|
||||
id function = [library newFunctionWithName:@"raster_texture"];
|
||||
rasterPipeline = [device newComputePipelineStateWithFunction:function error:&error];
|
||||
if (error) {
|
||||
printf("[METAL] create pipeline error: %s\n", error.localizedDescription.UTF8String);
|
||||
return nullptr;
|
||||
}
|
||||
return rasterPipeline;
|
||||
}
|
||||
return rasterPipeline;
|
||||
}
|
||||
} // namespace
|
||||
|
||||
@interface MultiArrayFeatureProvider : NSObject <MLFeatureProvider> {
|
||||
const std::vector<std::pair<const MNN::Tensor*, std::string>>* _inputs;
|
||||
NSMutableDictionary* _inputs;
|
||||
NSSet* _featureNames;
|
||||
}
|
||||
|
||||
- (instancetype)initWithInputs:(const std::vector<std::pair<const MNN::Tensor*, std::string>>*)inputs
|
||||
- (instancetype)initWithInputs:(const std::vector<std::pair<const MNN::Tensor*, std::string>>*)inputs useImage:(bool)useImage
|
||||
coreMlVersion:(int)coreMlVersion;
|
||||
- (MLFeatureValue*)featureValueForName:(NSString*)featureName API_AVAILABLE(ios(11));
|
||||
- (NSSet<NSString*>*)featureNames;
|
||||
|
|
@ -77,34 +52,30 @@ id<MTLComputePipelineState> getRasterPipeline() {
|
|||
|
||||
@implementation MultiArrayFeatureProvider
|
||||
|
||||
- (instancetype)initWithInputs:(const std::vector<std::pair<const MNN::Tensor*, std::string>>*)inputs
|
||||
- (instancetype)initWithInputs:(const std::vector<std::pair<const MNN::Tensor*, std::string>>*)inputs useImage:(bool)useImage
|
||||
coreMlVersion:(int)coreMlVersion {
|
||||
self = [super init];
|
||||
_inputs = inputs;
|
||||
_inputs = [NSMutableDictionary dictionaryWithCapacity:inputs->size()];
|
||||
_coreMlVersion = coreMlVersion;
|
||||
for (auto& input : *_inputs) {
|
||||
if (input.second.empty()) {
|
||||
_featureNames = nil;
|
||||
NSMutableArray* names = [[NSMutableArray alloc] init];
|
||||
for (auto& input : *inputs) {
|
||||
MLFeatureValue* value = nil;
|
||||
auto tensor = input.first;
|
||||
NSError* error = nil;
|
||||
NSString* name = [NSString stringWithCString:input.second.c_str() encoding:[NSString defaultCStringEncoding]];
|
||||
if (useImage) {
|
||||
CVPixelBufferRef pixelBuffer = NULL;
|
||||
OSType pixelFormat = kCVPixelFormatType_OneComponent8;
|
||||
size_t bytePerRow = tensor->width();
|
||||
CVReturn status = CVPixelBufferCreateWithBytes(nil, tensor->width(), tensor->height(), pixelFormat,
|
||||
tensor->host<void>(), bytePerRow, nil, nil, nil, &pixelBuffer);
|
||||
if (status != kCVReturnSuccess) {
|
||||
NSLog(@"Failed to create CVPixelBufferRef for feature %@", name);
|
||||
return nil;
|
||||
}
|
||||
}
|
||||
return self;
|
||||
}
|
||||
|
||||
- (NSSet<NSString*>*)featureNames {
|
||||
if (_featureNames == nil) {
|
||||
NSMutableArray* names = [[NSMutableArray alloc] init];
|
||||
for (auto& input : *_inputs) {
|
||||
[names addObject:[NSString stringWithCString:input.second.c_str()
|
||||
encoding:[NSString defaultCStringEncoding]]];
|
||||
}
|
||||
_featureNames = [NSSet setWithArray:names];
|
||||
}
|
||||
return _featureNames;
|
||||
}
|
||||
|
||||
- (MLFeatureValue*)featureValueForName:(NSString*)featureName {
|
||||
for (auto& input : *_inputs) {
|
||||
if ([featureName cStringUsingEncoding:NSUTF8StringEncoding] == input.second) {
|
||||
value = [MLFeatureValue featureValueWithPixelBuffer:pixelBuffer];
|
||||
} else {
|
||||
auto input_shape = input.first->shape();
|
||||
NSMutableArray* shape = [NSMutableArray arrayWithCapacity:input_shape.size()];
|
||||
NSMutableArray* strides = [NSMutableArray arrayWithCapacity:input_shape.size()];
|
||||
|
|
@ -120,37 +91,30 @@ id<MTLComputePipelineState> getRasterPipeline() {
|
|||
[shape addObject:@(input_shape[i])];
|
||||
[strides addObject:@(stridesDim[i])];
|
||||
}
|
||||
auto tensor = input.first;
|
||||
if (tensor->getType() == halide_type_of<uint8_t>()) {
|
||||
CVPixelBufferRef pixelBuffer = NULL;
|
||||
OSType pixelFormat = kCVPixelFormatType_OneComponent8;
|
||||
size_t bytePerRow = tensor->width();
|
||||
CVReturn status = CVPixelBufferCreateWithBytes(nil, tensor->width(), tensor->height(), pixelFormat,
|
||||
tensor->host<void>(), bytePerRow, nil, nil, nil, &pixelBuffer);
|
||||
if (status != kCVReturnSuccess) {
|
||||
NSLog(@"Failed to create CVPixelBufferRef for feature %@", featureName);
|
||||
return nil;
|
||||
}
|
||||
auto* mlFeatureValue = [MLFeatureValue featureValueWithPixelBuffer:pixelBuffer];
|
||||
return mlFeatureValue;
|
||||
} else {
|
||||
NSError* error = nil;
|
||||
MLMultiArray* mlArray = [[MLMultiArray alloc] initWithDataPointer:tensor->host<float>()
|
||||
shape:shape
|
||||
dataType:MLMultiArrayDataTypeFloat32
|
||||
strides:strides
|
||||
deallocator:(^(void* bytes){})error:&error];
|
||||
if (error != nil) {
|
||||
NSLog(@"Failed to create MLMultiArray for feature %@ error: %@", featureName, [error localizedDescription]);
|
||||
NSLog(@"Failed to create MLMultiArray for feature %@ error: %@", name, [error localizedDescription]);
|
||||
return nil;
|
||||
}
|
||||
auto* mlFeatureValue = [MLFeatureValue featureValueWithMultiArray:mlArray];
|
||||
return mlFeatureValue;
|
||||
value= [MLFeatureValue featureValueWithMultiArray:mlArray];
|
||||
}
|
||||
[names addObject:name];
|
||||
[_inputs setValue:value forKey:(name)];
|
||||
}
|
||||
_featureNames = [NSSet setWithArray:names];
|
||||
return self;
|
||||
}
|
||||
NSLog(@"Feature %@ not found", featureName);
|
||||
return nil;
|
||||
|
||||
- (NSSet<NSString*>*)featureNames {
|
||||
return _featureNames;
|
||||
}
|
||||
|
||||
- (MLFeatureValue*)featureValueForName:(NSString*)featureName {
|
||||
return _inputs[featureName];
|
||||
}
|
||||
@end
|
||||
|
||||
|
|
@ -160,16 +124,20 @@ id<MTLComputePipelineState> getRasterPipeline() {
|
|||
if (_model == nil) {
|
||||
return NO;
|
||||
}
|
||||
|
||||
@autoreleasepool{
|
||||
_outputArray = nil;
|
||||
_outputArray = [NSMutableArray arrayWithCapacity:0];
|
||||
NSError* error = nil;
|
||||
MultiArrayFeatureProvider* inputFeature = [[MultiArrayFeatureProvider alloc] initWithInputs:&inputs coreMlVersion:[self coreMlVersion]];
|
||||
bool useImage = _precision == 2;
|
||||
MultiArrayFeatureProvider* inputFeature = [[MultiArrayFeatureProvider alloc] initWithInputs:&inputs useImage:useImage coreMlVersion:[self coreMlVersion]];
|
||||
if (inputFeature == nil) {
|
||||
NSLog(@"inputFeature is not initialized.");
|
||||
return NO;
|
||||
}
|
||||
MLPredictionOptions* options = [[MLPredictionOptions alloc] init];
|
||||
// options.usesCPUOnly = true;
|
||||
_outputFeature = [_model predictionFromFeatures:inputFeature
|
||||
auto _outputFeature = [_model predictionFromFeatures:inputFeature
|
||||
options:options
|
||||
error:&error];
|
||||
if (error != nil) {
|
||||
|
|
@ -196,6 +164,7 @@ id<MTLComputePipelineState> getRasterPipeline() {
|
|||
if (data.dataPointer == nullptr) {
|
||||
return NO;
|
||||
}
|
||||
[_outputArray addObject:data];
|
||||
const_cast<MNN::Tensor*>(output.first)->buffer().host = (unsigned char*)data.dataPointer;
|
||||
}
|
||||
}
|
||||
|
|
@ -269,9 +238,6 @@ id<MTLComputePipelineState> getRasterPipeline() {
|
|||
- (instancetype)initWithParameterDictionary:(NSDictionary<NSString *,id> *)parameters
|
||||
error:(NSError * _Nullable *)error {
|
||||
self = [super init];
|
||||
#ifdef COREML_METAL_RASTER
|
||||
pipeline = getRasterPipeline();
|
||||
#endif
|
||||
return self;
|
||||
}
|
||||
- (void) setRegionSampler
|
||||
|
|
@ -428,31 +394,6 @@ id<MTLComputePipelineState> getRasterPipeline() {
|
|||
return YES;
|
||||
}
|
||||
|
||||
// TODO: raster in metal with texture
|
||||
#ifdef COREML_METAL_RASTER
|
||||
// execute on gpu
|
||||
- (BOOL)encodeToCommandBuffer:(id<MTLCommandBuffer>)commandBuffer
|
||||
inputs:(NSArray<id<MTLTexture>> *)inputs
|
||||
outputs:(NSArray<id<MTLTexture>> *)outputs
|
||||
error:(NSError **)error {
|
||||
printf("Raster GPU execute\n");
|
||||
id outputBuffer = [ outputs[0] buffer];
|
||||
NSLog(@"in -> %@", inputs[0]);
|
||||
NSLog(@"out -> %@", outputs[0]);
|
||||
id encoder = [commandBuffer computeCommandEncoder];
|
||||
[encoder setComputePipelineState:pipeline];
|
||||
for (int i = 0; i < inputs.count; i++) {
|
||||
[encoder setTexture:inputs[i] atIndex:0];
|
||||
[encoder setTexture:outputs[0] atIndex:1];
|
||||
[encoder setBytes:&samplers[i] length:sizeof(SamplerInfo) atIndex:0];
|
||||
std::pair<MTLSize, MTLSize> group = [self computeBestGroupAndLocal:samplers[i]];
|
||||
[encoder dispatchThreadgroups:group.first threadsPerThreadgroup:group.second];
|
||||
}
|
||||
// [encoder endEncoding];
|
||||
return YES;
|
||||
|
||||
}
|
||||
#endif
|
||||
@end
|
||||
|
||||
@implementation DumpLayer
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@
|
|||
namespace MNN {
|
||||
class CoreMLExecutorWrapper {
|
||||
public:
|
||||
CoreMLExecutorWrapper();
|
||||
CoreMLExecutorWrapper(int precision);
|
||||
~CoreMLExecutorWrapper();
|
||||
bool compileModel(CoreML__Specification__Model* model);
|
||||
void invokModel(const std::vector<std::pair<const MNN::Tensor*, std::string>>& inputs,
|
||||
|
|
|
|||
|
|
@ -20,16 +20,20 @@ static inline CoreMLExecutor* getCoreMLExecutoreRef(void* ptr) {
|
|||
return (__bridge CoreMLExecutor*)ptr;
|
||||
}
|
||||
|
||||
CoreMLExecutorWrapper::CoreMLExecutorWrapper() {
|
||||
CoreMLExecutorWrapper::CoreMLExecutorWrapper(int precision) {
|
||||
if (mCoreMLExecutorPtr == nullptr) {
|
||||
mCoreMLExecutorPtr = (__bridge_retained void*)[[CoreMLExecutor alloc] init];
|
||||
auto executor = getCoreMLExecutoreRef(mCoreMLExecutorPtr);
|
||||
executor.precision = precision;
|
||||
}
|
||||
}
|
||||
|
||||
CoreMLExecutorWrapper::~CoreMLExecutorWrapper() {
|
||||
@autoreleasepool {
|
||||
auto executor = getCoreMLExecutoreOwn(mCoreMLExecutorPtr);
|
||||
(void)executor;
|
||||
mCoreMLExecutorPtr = nullptr;
|
||||
executor = nullptr;
|
||||
}
|
||||
}
|
||||
|
||||
bool CoreMLExecutorWrapper::compileModel(CoreML__Specification__Model* model) {
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
// This file is generated by Shell for ops register
|
||||
namespace MNN {
|
||||
extern void ___CoreMLRelu6__OpType_ReLU6__();
|
||||
extern void ___CoreMLReduction__OpType_Reduction__();
|
||||
extern void ___CoreMLBinary__OpType_BinaryOp__();
|
||||
extern void ___CoreMLBinary__OpType_Eltwise__();
|
||||
|
|
@ -7,20 +8,23 @@ extern void ___CoreMLArgMax__OpType_ArgMax__();
|
|||
extern void ___CoreMLConvolution__OpType_Convolution__();
|
||||
extern void ___CoreMLConvolution__OpType_ConvolutionDepthwise__();
|
||||
extern void ___CoreMLConvolution__OpType_Deconvolution__();
|
||||
extern void ___CoreMLConvolution__OpType_DeconvolutionDepthwise__();
|
||||
extern void ___CoreMLInterp__OpType_Interp__();
|
||||
extern void ___CoreMLLayerNorm__OpType_LayerNorm__();
|
||||
extern void ___CoreMLUnary__OpType_UnaryOp__();
|
||||
extern void ___CoreMLMatMul__OpType_BatchMatMul__();
|
||||
extern void ___CoreMLMatMul__OpType_MatMul__();
|
||||
extern void ___CoreMLScale__OpType_Scale__();
|
||||
extern void ___CoreMLPool__OpType_Pooling__();
|
||||
extern void ___CoreMLRaster__OpType_Raster__();
|
||||
extern void ___CoreMLActivation__OpType_ReLU__();
|
||||
extern void ___CoreMLActivation__OpType_ReLU6__();
|
||||
extern void ___CoreMLActivation__OpType_ELU__();
|
||||
extern void ___CoreMLActivation__OpType_PReLU__();
|
||||
extern void ___CoreMLActivation__OpType_Sigmoid__();
|
||||
extern void ___CoreMLActivation__OpType_Softmax__();
|
||||
|
||||
void registerCoreMLOps() {
|
||||
___CoreMLRelu6__OpType_ReLU6__();
|
||||
___CoreMLReduction__OpType_Reduction__();
|
||||
___CoreMLBinary__OpType_BinaryOp__();
|
||||
___CoreMLBinary__OpType_Eltwise__();
|
||||
|
|
@ -28,14 +32,16 @@ ___CoreMLArgMax__OpType_ArgMax__();
|
|||
___CoreMLConvolution__OpType_Convolution__();
|
||||
___CoreMLConvolution__OpType_ConvolutionDepthwise__();
|
||||
___CoreMLConvolution__OpType_Deconvolution__();
|
||||
___CoreMLConvolution__OpType_DeconvolutionDepthwise__();
|
||||
___CoreMLInterp__OpType_Interp__();
|
||||
___CoreMLLayerNorm__OpType_LayerNorm__();
|
||||
___CoreMLUnary__OpType_UnaryOp__();
|
||||
___CoreMLMatMul__OpType_BatchMatMul__();
|
||||
___CoreMLMatMul__OpType_MatMul__();
|
||||
___CoreMLScale__OpType_Scale__();
|
||||
___CoreMLPool__OpType_Pooling__();
|
||||
___CoreMLRaster__OpType_Raster__();
|
||||
___CoreMLActivation__OpType_ReLU__();
|
||||
___CoreMLActivation__OpType_ReLU6__();
|
||||
___CoreMLActivation__OpType_ELU__();
|
||||
___CoreMLActivation__OpType_PReLU__();
|
||||
___CoreMLActivation__OpType_Sigmoid__();
|
||||
|
|
|
|||
|
|
@ -1,39 +0,0 @@
|
|||
//
|
||||
// CoreMLRaster.metal
|
||||
// MNN
|
||||
//
|
||||
// Created by MNN on 2021/04/26.
|
||||
// Copyright © 2018, Alibaba Group Holding Limited
|
||||
//
|
||||
#include <metal_stdlib>
|
||||
using namespace metal;
|
||||
|
||||
struct SamplerInfo {
|
||||
uint4 stride; //stride[3] + offset
|
||||
uint4 size; //size[3] + totalSize
|
||||
uint4 extent; //dstStride[3]+dstOffset
|
||||
uint4 imageSize;
|
||||
};
|
||||
|
||||
kernel void raster_texture(texture2d_array<half, access::read> in [[texture(0)]],
|
||||
texture2d_array<half, access::write> out [[texture(1)]],
|
||||
constant SamplerInfo &info [[buffer(0)]],
|
||||
uint3 gid [[thread_position_in_grid]]) {
|
||||
if (gid.x < info.size.x && gid.y < info.size.y && gid.z < info.size.z) {
|
||||
uint dstOffset = gid.x * info.extent.x + gid.y * info.extent.y + gid.z * info.extent.z + info.extent.w;
|
||||
uint srcOffset = gid.x * info.stride.x + gid.y * info.stride.y + gid.z * info.stride.z + info.stride.w;
|
||||
// out[int(dstOffset)] = in[int(srcOffset)];
|
||||
// do raster on texture
|
||||
}
|
||||
}
|
||||
|
||||
kernel void raster(const device int *in [[buffer(0)]],
|
||||
device int *out [[buffer(1)]],
|
||||
constant SamplerInfo &info [[buffer(2)]],
|
||||
uint3 gid [[thread_position_in_grid]]) {
|
||||
if (gid.x < info.size.x && gid.y < info.size.y && gid.z < info.size.z) {
|
||||
uint dstOffset = gid.x * info.extent.x + gid.y * info.extent.y + gid.z * info.extent.z + info.extent.w;
|
||||
uint srcOffset = gid.x * info.stride.x + gid.y * info.stride.y + gid.z * info.stride.z + info.stride.w;
|
||||
out[int(dstOffset)] = in[int(srcOffset)];
|
||||
}
|
||||
}
|
||||
|
|
@ -35,38 +35,6 @@ ErrorCode CoreMLActivation::onResize(const std::vector<Tensor *> &inputs, const
|
|||
core_ml__specification__activation_leaky_re_lu__init(mLayer_->activation->leakyrelu);
|
||||
mLayer_->activation->leakyrelu->alpha = mOp->main_as_Relu()->slope();
|
||||
break;
|
||||
case OpType_ReLU6:
|
||||
{
|
||||
// relu + threshold
|
||||
auto reluLayer = mCoreMLBackend->create<CoreML__Specification__NeuralNetworkLayer>();
|
||||
core_ml__specification__neural_network_layer__init(reluLayer);
|
||||
mCoreMLBackend->setLayerName(reluLayer, "relu6-relu");
|
||||
reluLayer->activation = mCoreMLBackend->create<CoreML__Specification__ActivationParams>();
|
||||
reluLayer->activation->nonlinearity_type_case = CORE_ML__SPECIFICATION__ACTIVATION_PARAMS__NONLINEARITY_TYPE_RE_LU;
|
||||
reluLayer->activation->relu = mCoreMLBackend->create<CoreML__Specification__ActivationReLU>();
|
||||
core_ml__specification__activation_re_lu__init(reluLayer->activation->relu);
|
||||
std::string reluOutput = mCoreMLBackend->getTensorName(inputs[0]) + "-relu";
|
||||
setLayerInputsAndOutputs(reluLayer, {mCoreMLBackend->getTensorName(inputs[0])}, {reluOutput});
|
||||
mCoreMLBackend->addLayer(reluLayer);
|
||||
|
||||
auto thresholdLayer = mCoreMLBackend->create<CoreML__Specification__NeuralNetworkLayer>();
|
||||
core_ml__specification__neural_network_layer__init(thresholdLayer);
|
||||
mCoreMLBackend->setLayerName(thresholdLayer, "relu6-threshold");
|
||||
thresholdLayer->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_UNARY;
|
||||
thresholdLayer->unary = mCoreMLBackend->create<CoreML__Specification__UnaryFunctionLayerParams>();
|
||||
core_ml__specification__unary_function_layer_params__init(thresholdLayer->unary);
|
||||
thresholdLayer->unary->type = CORE_ML__SPECIFICATION__UNARY_FUNCTION_LAYER_PARAMS__OPERATION__THRESHOLD;
|
||||
thresholdLayer->unary->alpha = -6;
|
||||
thresholdLayer->unary->scale = -1;
|
||||
inputName = reluOutput + "-threshold";
|
||||
setLayerInputsAndOutputs(thresholdLayer, {reluOutput}, {inputName});
|
||||
mCoreMLBackend->addLayer(thresholdLayer);
|
||||
|
||||
mLayer_->activation->linear = mCoreMLBackend->create<CoreML__Specification__ActivationLinear>();
|
||||
core_ml__specification__activation_linear__init(mLayer_->activation->linear);
|
||||
mLayer_->activation->linear->alpha = -1;
|
||||
break;
|
||||
}
|
||||
case OpType_ELU:
|
||||
mLayer_->activation->nonlinearity_type_case = CORE_ML__SPECIFICATION__ACTIVATION_PARAMS__NONLINEARITY_TYPE_ELU;
|
||||
mLayer_->activation->elu = mCoreMLBackend->create<CoreML__Specification__ActivationELU>();
|
||||
|
|
@ -74,6 +42,13 @@ ErrorCode CoreMLActivation::onResize(const std::vector<Tensor *> &inputs, const
|
|||
break;
|
||||
case OpType_PReLU:
|
||||
{
|
||||
if (mOp->main_as_PRelu()->slopeCount() == 1) {
|
||||
mLayer_->activation->nonlinearity_type_case = CORE_ML__SPECIFICATION__ACTIVATION_PARAMS__NONLINEARITY_TYPE_LEAKY_RE_LU;
|
||||
mLayer_->activation->leakyrelu = mCoreMLBackend->create<CoreML__Specification__ActivationLeakyReLU>();
|
||||
core_ml__specification__activation_leaky_re_lu__init(mLayer_->activation->leakyrelu);
|
||||
mLayer_->activation->leakyrelu->alpha = mOp->main_as_PRelu()->slope()->data()[0];
|
||||
break;
|
||||
}
|
||||
mLayer_->activation->nonlinearity_type_case = CORE_ML__SPECIFICATION__ACTIVATION_PARAMS__NONLINEARITY_TYPE_PRE_LU;
|
||||
mLayer_->activation->prelu = mCoreMLBackend->create<CoreML__Specification__ActivationPReLU>();
|
||||
core_ml__specification__activation_pre_lu__init(mLayer_->activation->prelu);
|
||||
|
|
@ -100,7 +75,6 @@ ErrorCode CoreMLActivation::onResize(const std::vector<Tensor *> &inputs, const
|
|||
}
|
||||
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLActivation, OpType_ReLU)
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLActivation, OpType_ReLU6)
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLActivation, OpType_ELU)
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLActivation, OpType_PReLU)
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLActivation, OpType_Sigmoid)
|
||||
|
|
|
|||
|
|
@ -7,6 +7,7 @@
|
|||
//
|
||||
|
||||
#include "CoreMLBinary.hpp"
|
||||
#include "core/TensorUtils.hpp"
|
||||
|
||||
namespace MNN {
|
||||
|
||||
|
|
@ -40,21 +41,25 @@ ErrorCode CoreMLBinary::onResize(const std::vector<Tensor *> &inputs, const std:
|
|||
bool oneInput = false;
|
||||
float constVal = 0.f;
|
||||
const Tensor* input = nullptr;
|
||||
if (TensorUtils::getDescribe(inputs[0])->usage == Tensor::InsideDescribe::CONSTANT) {
|
||||
if (TensorUtils::getDescribe(inputs[0])->usage == Tensor::InsideDescribe::CONSTANT && 1 == TensorUtils::getRawSize(inputs[0])) {
|
||||
constVal = inputs[0]->host<float>()[0];
|
||||
input = inputs[1];
|
||||
} else if (TensorUtils::getDescribe(inputs[1])->usage == Tensor::InsideDescribe::CONSTANT) {
|
||||
} else if (TensorUtils::getDescribe(inputs[1])->usage == Tensor::InsideDescribe::CONSTANT && 1 == TensorUtils::getRawSize(inputs[1])) {
|
||||
constVal = inputs[1]->host<float>()[0];
|
||||
input = inputs[0];
|
||||
}
|
||||
switch (binaryType) {
|
||||
case BinaryOpOperation_ADD:
|
||||
if (input) {
|
||||
mLayer_->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_ADD;
|
||||
mLayer_->add = mCoreMLBackend->create<CoreML__Specification__AddLayerParams>();
|
||||
core_ml__specification__add_layer_params__init(mLayer_->add);
|
||||
if (input) {
|
||||
mLayer_->add->alpha = constVal;
|
||||
oneInput = true;
|
||||
} else {
|
||||
mLayer_->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_ADD_BROADCASTABLE;
|
||||
mLayer_->addbroadcastable = mCoreMLBackend->create<CoreML__Specification__AddBroadcastableLayerParams>();
|
||||
core_ml__specification__add_broadcastable_layer_params__init(mLayer_->addbroadcastable);
|
||||
}
|
||||
break;
|
||||
case BinaryOpOperation_SUB:
|
||||
|
|
@ -75,12 +80,16 @@ ErrorCode CoreMLBinary::onResize(const std::vector<Tensor *> &inputs, const std:
|
|||
}
|
||||
break;
|
||||
case BinaryOpOperation_MUL:
|
||||
if (input) {
|
||||
mLayer_->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_MULTIPLY;
|
||||
mLayer_->multiply = mCoreMLBackend->create<CoreML__Specification__MultiplyLayerParams>();
|
||||
core_ml__specification__multiply_layer_params__init(mLayer_->multiply);
|
||||
if (input) {
|
||||
mLayer_->multiply->alpha = constVal;
|
||||
oneInput = true;
|
||||
} else {
|
||||
mLayer_->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_MULTIPLY_BROADCASTABLE;
|
||||
mLayer_->multiplybroadcastable = mCoreMLBackend->create<_CoreML__Specification__MultiplyBroadcastableLayerParams>();
|
||||
core_ml__specification__multiply_broadcastable_layer_params__init(mLayer_->multiplybroadcastable);
|
||||
}
|
||||
break;
|
||||
case BinaryOpOperation_DIV:
|
||||
|
|
|
|||
|
|
@ -6,13 +6,15 @@
|
|||
// Copyright © 2018, Alibaba Group Holding Limited
|
||||
//
|
||||
|
||||
#include <float.h>
|
||||
#include "core/ConvolutionCommon.hpp"
|
||||
#include "CoreMLConvolution.hpp"
|
||||
|
||||
namespace MNN {
|
||||
|
||||
|
||||
CoreMLConvolution::CoreMLConvolution(MNN::Backend *b, const MNN::Op *op, const std::vector<Tensor *> &inputs, const std::vector<MNN::Tensor *> &outputs) : CoreMLCommonExecution(b, op) {
|
||||
isDeconv = op->type() == OpType_Deconvolution;
|
||||
isDeconv = op->type() == OpType_Deconvolution || op->type() == OpType_DeconvolutionDepthwise;
|
||||
initLayer();
|
||||
}
|
||||
|
||||
|
|
@ -47,21 +49,17 @@ void CoreMLConvolution::loadWeightBias(const std::vector<Tensor *> &inputs) {
|
|||
biasPtr = conv2D->bias()->data();
|
||||
}
|
||||
|
||||
void CoreMLConvolution::addPadLayer(const Tensor * input, const Convolution2DCommon* common) {
|
||||
MNN_ASSERT(common->padMode() == PadMode_CAFFE);
|
||||
int top, left, bottom, right;
|
||||
if (nullptr != common->pads()) {
|
||||
MNN_ASSERT(common->pads()->size() >= 4);
|
||||
top = common->pads()->Get(0);
|
||||
left = common->pads()->Get(1);
|
||||
bottom = common->pads()->Get(2);
|
||||
right = common->pads()->Get(3);
|
||||
void CoreMLConvolution::addPadLayer(const Tensor * input, const Tensor * output, const Convolution2DCommon* common) {
|
||||
std::pair<int, int> pads;
|
||||
if (isDeconv) {
|
||||
pads = ConvolutionCommon::convolutionTransposePad(input, output, common);
|
||||
} else {
|
||||
top = common->padY();
|
||||
left = common->padX();
|
||||
bottom = common->padY();
|
||||
right = common->padX();
|
||||
pads = ConvolutionCommon::convolutionPad(input, output, common);
|
||||
}
|
||||
int top = pads.second;
|
||||
int left = pads.first;
|
||||
int bottom = pads.second;
|
||||
int right = pads.first;
|
||||
if (top == 0 && left == 0 && bottom == 0 && right == 0) {
|
||||
return;
|
||||
}
|
||||
|
|
@ -69,32 +67,10 @@ void CoreMLConvolution::addPadLayer(const Tensor * input, const Convolution2DCom
|
|||
isSamePadding = true;
|
||||
return;
|
||||
}
|
||||
if (!isDeconv && outputWidth == UP_DIV(inputWidth, common->strideX()) && outputHeight == UP_DIV(outputHeight, common->strideY())) {
|
||||
if (!isDeconv && outputWidth == UP_DIV(inputWidth, common->strideX()) && outputHeight == UP_DIV(inputHeight, common->strideY())) {
|
||||
isSamePadding = true;
|
||||
return;
|
||||
}
|
||||
if (isDeconv) {
|
||||
int ky = common->kernelY();
|
||||
int kx = common->kernelX();
|
||||
int sy = common->strideY();
|
||||
int sx = common->strideX();
|
||||
int pad_out_height = (outputHeight - ky) / sy + 1;
|
||||
int pad_out_width = (outputWidth - kx) / sx + 1;
|
||||
top = (pad_out_height - inputHeight) / 2;
|
||||
bottom = (pad_out_height - inputHeight) - top;
|
||||
left = (pad_out_width - inputWidth) / 2;
|
||||
right = (pad_out_width - inputWidth) - left;
|
||||
|
||||
if (top < 0 || bottom < 0 || left < 0 || right < 0) {
|
||||
isSamePadding = true;
|
||||
pad_out_width = outputWidth / sx;
|
||||
pad_out_height = outputHeight / sy;
|
||||
bottom = 0;
|
||||
top = pad_out_height - inputHeight;
|
||||
right = 0;
|
||||
left = pad_out_width - inputWidth;
|
||||
}
|
||||
}
|
||||
std::string layerName = "ConvPadding-" + mConvInputName;
|
||||
auto paddingLayer = mCoreMLBackend->create<CoreML__Specification__NeuralNetworkLayer>();
|
||||
core_ml__specification__neural_network_layer__init(paddingLayer);
|
||||
|
|
@ -132,6 +108,7 @@ ErrorCode CoreMLConvolution::onResize(const std::vector<Tensor *> &inputs, const
|
|||
outputWidth = outputs[0]->width();
|
||||
outputHeight = outputs[0]->height();
|
||||
loadWeightBias(inputs);
|
||||
isSamePadding = false;
|
||||
auto conv2D = mOp->main_as_Convolution2D();
|
||||
auto common = conv2D->common();
|
||||
auto kernelX = common->kernelX();
|
||||
|
|
@ -156,6 +133,12 @@ ErrorCode CoreMLConvolution::onResize(const std::vector<Tensor *> &inputs, const
|
|||
mLayer_->convolution->dilationfactor = mCoreMLBackend->create<uint64_t>(mLayer_->convolution->n_dilationfactor);
|
||||
mLayer_->convolution->dilationfactor[0] = dilateY;
|
||||
mLayer_->convolution->dilationfactor[1] = dilateX;
|
||||
if (isDeconv) {
|
||||
mLayer_->convolution->n_outputshape = 2;
|
||||
mLayer_->convolution->outputshape = mCoreMLBackend->create<uint64_t>(2);
|
||||
mLayer_->convolution->outputshape[0] = outputHeight;
|
||||
mLayer_->convolution->outputshape[1] = outputWidth;
|
||||
}
|
||||
switch (padMod) {
|
||||
case PadMode_SAME:
|
||||
mLayer_->convolution->convolution_padding_type_case = CORE_ML__SPECIFICATION__CONVOLUTION_LAYER_PARAMS__CONVOLUTION_PADDING_TYPE_SAME;
|
||||
|
|
@ -168,11 +151,12 @@ ErrorCode CoreMLConvolution::onResize(const std::vector<Tensor *> &inputs, const
|
|||
core_ml__specification__valid_padding__init(mLayer_->convolution->valid);
|
||||
break;
|
||||
case PadMode_CAFFE:
|
||||
addPadLayer(inputs[0], common);
|
||||
addPadLayer(inputs[0], outputs[0], common);
|
||||
if (isSamePadding){
|
||||
mLayer_->convolution->convolution_padding_type_case = CORE_ML__SPECIFICATION__CONVOLUTION_LAYER_PARAMS__CONVOLUTION_PADDING_TYPE_SAME;
|
||||
mLayer_->convolution->same = mCoreMLBackend->create<CoreML__Specification__SamePadding>();
|
||||
core_ml__specification__same_padding__init(mLayer_->convolution->same);
|
||||
mLayer_->convolution->same->asymmetrymode = CORE_ML__SPECIFICATION__SAME_PADDING__SAME_PADDING_MODE__TOP_LEFT_HEAVY;
|
||||
break;
|
||||
} else {
|
||||
mLayer_->convolution->convolution_padding_type_case = CORE_ML__SPECIFICATION__CONVOLUTION_LAYER_PARAMS__CONVOLUTION_PADDING_TYPE_VALID;
|
||||
|
|
@ -183,9 +167,11 @@ ErrorCode CoreMLConvolution::onResize(const std::vector<Tensor *> &inputs, const
|
|||
default:
|
||||
break;
|
||||
}
|
||||
|
||||
int inputCount = weightSize / (kernelX * kernelY * outputCount);
|
||||
mLayer_->convolution->kernelchannels = inputCount;
|
||||
if (isDeconv) {
|
||||
mLayer_->convolution->kernelchannels = inputs[0]->channel();
|
||||
} else {
|
||||
mLayer_->convolution->kernelchannels = weightSize / (kernelX * kernelY * outputCount);
|
||||
}
|
||||
mLayer_->convolution->outputchannels = outputCount;
|
||||
mLayer_->convolution->n_kernelsize = 2;
|
||||
mLayer_->convolution->kernelsize = mCoreMLBackend->create<uint64_t>(mLayer_->convolution->n_kernelsize);
|
||||
|
|
@ -214,12 +200,16 @@ ErrorCode CoreMLConvolution::onResize(const std::vector<Tensor *> &inputs, const
|
|||
auto reluLayer = mCoreMLBackend->create<CoreML__Specification__NeuralNetworkLayer>();
|
||||
core_ml__specification__neural_network_layer__init(reluLayer);
|
||||
mCoreMLBackend->setLayerName(reluLayer, "ConvRelu");
|
||||
reluLayer->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_ACTIVATION;
|
||||
reluLayer->activation = mCoreMLBackend->create<CoreML__Specification__ActivationParams>();
|
||||
core_ml__specification__activation_params__init(reluLayer->activation);
|
||||
reluLayer->activation->nonlinearity_type_case = CORE_ML__SPECIFICATION__ACTIVATION_PARAMS__NONLINEARITY_TYPE_RE_LU;
|
||||
reluLayer->activation->relu = mCoreMLBackend->create<CoreML__Specification__ActivationReLU>();
|
||||
core_ml__specification__activation_re_lu__init(reluLayer->activation->relu);
|
||||
reluLayer->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_CLIP;
|
||||
reluLayer->clip = mCoreMLBackend->create<CoreML__Specification__ClipLayerParams>();
|
||||
core_ml__specification__clip_layer_params__init(reluLayer->clip);
|
||||
if (common->relu()) {
|
||||
reluLayer->clip->minval = 0.0f;
|
||||
reluLayer->clip->maxval = FLT_MAX;
|
||||
} else {
|
||||
reluLayer->clip->minval = 0.0f;
|
||||
reluLayer->clip->maxval = 6.0f;
|
||||
}
|
||||
setLayerInputsAndOutputs(reluLayer, {mConvOutputName}, {mCoreMLBackend->getTensorName(outputs[0])});
|
||||
mCoreMLBackend->addLayer(reluLayer);
|
||||
}
|
||||
|
|
@ -229,4 +219,5 @@ ErrorCode CoreMLConvolution::onResize(const std::vector<Tensor *> &inputs, const
|
|||
REGISTER_COREML_OP_CREATOR(CoreMLConvolution, OpType_Convolution)
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLConvolution, OpType_ConvolutionDepthwise)
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLConvolution, OpType_Deconvolution)
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLConvolution, OpType_DeconvolutionDepthwise)
|
||||
} // namespace MNN
|
||||
|
|
|
|||
|
|
@ -22,7 +22,7 @@ public:
|
|||
virtual ~CoreMLConvolution() = default;
|
||||
private:
|
||||
void loadWeightBias(const std::vector<Tensor *> &inputs);
|
||||
void addPadLayer(const Tensor * input, const Convolution2DCommon* common);
|
||||
void addPadLayer(const Tensor * input, const Tensor* output, const Convolution2DCommon* common);
|
||||
std::string mConvInputName, mConvOutputName;
|
||||
std::shared_ptr<ConvolutionCommon::Int8Common> quanCommon;
|
||||
const float *weightPtr, *biasPtr;
|
||||
|
|
|
|||
|
|
@ -0,0 +1,57 @@
|
|||
//
|
||||
// CoreMLMatMul.cpp
|
||||
// MNN
|
||||
//
|
||||
// Created by MNN on 2021/03/24.
|
||||
// Copyright © 2018, Alibaba Group Holding Limited
|
||||
//
|
||||
|
||||
#include "CoreMLMatMul.hpp"
|
||||
namespace MNN {
|
||||
|
||||
static void _makeMatMul() {
|
||||
|
||||
}
|
||||
CoreMLMatMul::CoreMLMatMul(MNN::Backend *b, const MNN::Op *op, const std::vector<Tensor *> &inputs, const std::vector<MNN::Tensor *> &outputs) : CoreMLCommonExecution(b, op) {
|
||||
initLayer();
|
||||
}
|
||||
|
||||
ErrorCode CoreMLMatMul::onResize(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) {
|
||||
auto outputName = mCoreMLBackend->getTensorName(outputs[0]);
|
||||
std::string matmulOutput = outputName;
|
||||
if (inputs.size() > 2) {
|
||||
// Has Bias
|
||||
matmulOutput = matmulOutput + "--matmul";
|
||||
}
|
||||
mLayer_->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_BATCHED_MATMUL;
|
||||
mLayer_->batchedmatmul = mCoreMLBackend->create<CoreML__Specification__BatchedMatMulLayerParams>();
|
||||
core_ml__specification__batched_mat_mul_layer_params__init(mLayer_->batchedmatmul);
|
||||
if (mOp->main_type() == OpParameter_MatMul) {
|
||||
mLayer_->batchedmatmul->transposea = mOp->main_as_MatMul()->transposeA();
|
||||
mLayer_->batchedmatmul->transposeb = mOp->main_as_MatMul()->transposeB();
|
||||
} else if (mOp->main_type() == OpParameter_BatchMatMulParam) {
|
||||
mLayer_->batchedmatmul->transposea = mOp->main_as_BatchMatMulParam()->adjX();
|
||||
mLayer_->batchedmatmul->transposeb = mOp->main_as_BatchMatMulParam()->adjY();
|
||||
}
|
||||
setLayerInputsAndOutputs(mLayer_, {mCoreMLBackend->getTensorName(inputs[0]), mCoreMLBackend->getTensorName(inputs[1])}, {matmulOutput});
|
||||
mCoreMLBackend->setLayerName(mLayer_, "MatMul");
|
||||
mCoreMLBackend->addLayer(mLayer_);
|
||||
if (inputs.size() > 2) {
|
||||
// Add Bias
|
||||
auto biasLayer = mCoreMLBackend->create<CoreML__Specification__NeuralNetworkLayer>();
|
||||
core_ml__specification__neural_network_layer__init(biasLayer);
|
||||
mCoreMLBackend->setLayerName(biasLayer, outputName + "Bias");
|
||||
mLayer_->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_ADD_BROADCASTABLE;
|
||||
mLayer_->addbroadcastable = mCoreMLBackend->create<CoreML__Specification__AddBroadcastableLayerParams>();
|
||||
core_ml__specification__add_broadcastable_layer_params__init(mLayer_->addbroadcastable);
|
||||
setLayerInputsAndOutputs(biasLayer, {matmulOutput, mCoreMLBackend->getTensorName(inputs[2])}, {outputName});
|
||||
mCoreMLBackend->addLayer(biasLayer);
|
||||
}
|
||||
return NO_ERROR;
|
||||
}
|
||||
|
||||
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLMatMul, OpType_BatchMatMul)
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLMatMul, OpType_MatMul)
|
||||
|
||||
} // namespace MNN
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
//
|
||||
// CoreMLMatMul.hpp
|
||||
// MNN
|
||||
//
|
||||
// Created by MNN on 2024/10/18.
|
||||
// Copyright © 2018, Alibaba Group Holding Limited
|
||||
//
|
||||
|
||||
#ifndef MNN_COREMLMATMUL_HPP
|
||||
#define MNN_COREMLMATMUL_HPP
|
||||
|
||||
#include "CoreMLCommonExecution.hpp"
|
||||
#include "CoreMLBackend.hpp"
|
||||
|
||||
namespace MNN {
|
||||
|
||||
class CoreMLMatMul : public CoreMLCommonExecution {
|
||||
public:
|
||||
CoreMLMatMul(Backend *b, const Op *op, const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs);
|
||||
ErrorCode onResize(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs);
|
||||
virtual ~CoreMLMatMul() = default;
|
||||
};
|
||||
} // namespace MNN
|
||||
|
||||
#endif // MNN_COREMLMATMUL_HPP
|
||||
|
|
@ -0,0 +1,36 @@
|
|||
//
|
||||
// CoreMLRelu6.cpp
|
||||
// MNN
|
||||
//
|
||||
// Created by MNN on 2021/03/31.
|
||||
// Copyright © 2018, Alibaba Group Holding Limited
|
||||
//
|
||||
|
||||
#include "CoreMLRelu6.hpp"
|
||||
|
||||
namespace MNN {
|
||||
|
||||
CoreMLRelu6::CoreMLRelu6(MNN::Backend *b, const MNN::Op *op, const std::vector<Tensor *> &inputs, const std::vector<MNN::Tensor *> &outputs) : CoreMLCommonExecution(b, op) {
|
||||
if (nullptr != op->main()) {
|
||||
auto p = op->main_as_Relu6();
|
||||
mMinValue = p->minValue();
|
||||
mMaxValue = p->maxValue();
|
||||
}
|
||||
initLayer();
|
||||
}
|
||||
|
||||
ErrorCode CoreMLRelu6::onResize(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) {
|
||||
MNN_ASSERT(inputs.size() == 1 && outputs.size() == 1);
|
||||
mLayer_->layer_case = CORE_ML__SPECIFICATION__NEURAL_NETWORK_LAYER__LAYER_CLIP;
|
||||
mLayer_->clip = mCoreMLBackend->create<_CoreML__Specification__ClipLayerParams>();
|
||||
core_ml__specification__clip_layer_params__init(mLayer_->clip);
|
||||
mLayer_->clip->maxval = mMaxValue;
|
||||
mLayer_->clip->minval = mMinValue;
|
||||
|
||||
setLayerInputsAndOutputs(mLayer_, {mCoreMLBackend->getTensorName(inputs[0])}, {mCoreMLBackend->getTensorName(outputs[0])});
|
||||
mCoreMLBackend->addLayer(mLayer_);
|
||||
return NO_ERROR;
|
||||
}
|
||||
|
||||
REGISTER_COREML_OP_CREATOR(CoreMLRelu6, OpType_ReLU6)
|
||||
} // namespace MNN
|
||||
|
|
@ -0,0 +1,28 @@
|
|||
//
|
||||
// CoreMLRelu6.hpp
|
||||
// MNN
|
||||
//
|
||||
// Created by MNN on 2024/10/18.
|
||||
// Copyright © 2018, Alibaba Group Holding Limited
|
||||
//
|
||||
|
||||
#ifndef MNN_COREMLRelu6_HPP
|
||||
#define MNN_COREMLRelu6_HPP
|
||||
|
||||
#include "CoreMLCommonExecution.hpp"
|
||||
#include "CoreMLBackend.hpp"
|
||||
|
||||
namespace MNN {
|
||||
|
||||
class CoreMLRelu6 : public CoreMLCommonExecution {
|
||||
public:
|
||||
CoreMLRelu6(Backend *b, const Op *op, const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs);
|
||||
ErrorCode onResize(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs);
|
||||
virtual ~CoreMLRelu6() = default;
|
||||
private:
|
||||
float mMinValue = 0.0f;
|
||||
float mMaxValue = 6.0f;
|
||||
};
|
||||
} // namespace MNN
|
||||
|
||||
#endif // MNN_COREMLRelu6_HPP
|
||||
|
|
@ -33,12 +33,12 @@ ErrorCode CPUCastCreator::cast(const void* inputRaw, void* outputRaw, ConvertTyp
|
|||
}
|
||||
if (type == INT8_TO_FlOAT) {
|
||||
std::vector<float> scales(pack, scale);
|
||||
bn->int8Functions()->MNNInt8ScaleToFloat((float*)(outputRaw), (int8_t*)(inputRaw), scales.data(), c4Size, zero);
|
||||
bn->int8Functions()->MNNInt8ScaleToFloat((float*)(outputRaw), (int8_t*)(inputRaw), &scale, c4Size, &zero, 0);
|
||||
if (remain > 0) {
|
||||
std::vector<float> tempDst(pack);
|
||||
std::vector<int8_t> tempSrc(pack);
|
||||
::memcpy(tempSrc.data(), (int8_t*)(inputRaw) + c4Size * pack, remain * sizeof(int8_t));
|
||||
bn->int8Functions()->MNNInt8ScaleToFloat(tempDst.data(), tempSrc.data(), scales.data(), 1, zero);
|
||||
bn->int8Functions()->MNNInt8ScaleToFloat(tempDst.data(), tempSrc.data(), &scale, 1, &zero, 0);
|
||||
::memcpy(static_cast<float*>(outputRaw) + c4Size * pack, tempDst.data(), remain * sizeof(float));
|
||||
}
|
||||
return NO_ERROR;
|
||||
|
|
|
|||
|
|
@ -175,6 +175,14 @@ ErrorCode CPUConvolutionDepthwise::BasicFloatExecution::onResize(const std::vect
|
|||
divides[0] = 0;
|
||||
static_cast<CPUBackend *>(backend())->computeDivideSizes(total, divides.data()+1);
|
||||
mNumber = numberThread;
|
||||
for (int i=1; i<numberThread; ++i) {
|
||||
if (divides[i+1] <= divides[i]) {
|
||||
// Only 0-(i-1) thread has work
|
||||
mNumber = i;
|
||||
break;
|
||||
}
|
||||
}
|
||||
MNN_ASSERT(mNumber > 0);
|
||||
auto postData = getPostParameters();
|
||||
if (static_cast<CPUBackend*>(backend())->functions()->bytes < 4) {
|
||||
static_cast<CPUBackend*>(backend())->functions()->MNNFp32ToLowp(postData.data() + 2, (int16_t*)(postData.data() + 2), 2);
|
||||
|
|
@ -196,6 +204,7 @@ ErrorCode CPUConvolutionDepthwise::BasicFloatExecution::onResize(const std::vect
|
|||
src_y_step = paddedWidth * unit;
|
||||
}
|
||||
mExecutor = [=](const uint8_t* inputPtr, uint8_t* outputPtr, int tId) {
|
||||
MNN_ASSERT(divides[tId] < divides[tId+1]);
|
||||
const auto inputPadPtr = mInputPad->host<uint8_t>() + mInputPad->stride(0) * tId * bytes;
|
||||
::memset(inputPadPtr, 0, mInputPad->stride(0) * bytes);
|
||||
auto biasP = inputs[2]->host<uint8_t>();
|
||||
|
|
|
|||
|
|
@ -260,6 +260,55 @@ ErrorCode CPUDeconvolution::onResize(const std::vector<Tensor *> &inputs, const
|
|||
return NO_ERROR;
|
||||
}
|
||||
|
||||
CPUDeconvolutionOrigin::CPUDeconvolutionOrigin(const Tensor *input, Tensor *weight, const Op *convOp, Backend *b, bool ModeInt8) : CPUDeconvolutionBasic(input, convOp, b) {
|
||||
if (ModeInt8) {
|
||||
const auto weightDataPtr = weight->host<int8_t>();
|
||||
auto conv2d = convOp->main_as_Convolution2D();
|
||||
auto common = conv2d->common();
|
||||
auto pack = static_cast<CPUBackend*>(b)->functions()->pack;
|
||||
mResource = CPUConvolution::makeResourceInt8(backend(), convOp, pack);
|
||||
CPUConvolution::MutableResourceInt8 mutableResource(mResource, b);
|
||||
auto core = static_cast<CPUBackend*>(b)->int8Functions();
|
||||
auto gemmKernel = core->Int8GemmKernel;
|
||||
int UNIT, SRC_UNIT, DST_XUNIT;
|
||||
core->MNNGetGemmUnit(&UNIT, &SRC_UNIT, &DST_XUNIT);
|
||||
const auto kEleCnt = mCommon->kernelX() * mCommon->kernelY();
|
||||
const int ocDiv4 = UP_DIV(common->outputCount(), pack) * kEleCnt;
|
||||
const int icDiv4 = UP_DIV(common->inputCount(), SRC_UNIT);
|
||||
const int ocDivUnit = UP_DIV(common->outputCount(), UNIT);
|
||||
const int oc4 = ocDiv4 / kEleCnt;
|
||||
const int bias_elesize = ocDiv4 * pack;
|
||||
// set offset if use SSE.
|
||||
auto inputQuant = TensorUtils::getQuantInfo(input);
|
||||
auto inputZeroPoint = inputQuant[1];
|
||||
std::vector<int32_t> _bias(bias_elesize, inputZeroPoint);
|
||||
#ifdef MNN_USE_SSE
|
||||
int actBits = conv2d->symmetricQuan()->nbits();
|
||||
if (actBits <= 7) {
|
||||
gemmKernel = core->Int8GemmKernelFast;
|
||||
}
|
||||
for (int a = 0; a < kEleCnt; ++a){
|
||||
for (int oz = 0; oz < ocDivUnit * UNIT; ++oz) {
|
||||
int offset = inputZeroPoint, oz4 = oz / UNIT, ozRemain = oz % UNIT;
|
||||
for (int sz = 0; sz < icDiv4 * SRC_UNIT; ++sz) {
|
||||
int sz4 = sz / SRC_UNIT, szRemain = sz % SRC_UNIT;
|
||||
int index = (((a * oc4 + oz4) * icDiv4 + sz4) * UNIT + ozRemain) * SRC_UNIT + szRemain;
|
||||
auto weightInt8Data = weightDataPtr[index];
|
||||
offset += weightInt8Data * (-128);
|
||||
}
|
||||
if (oz < oc4 * pack) {
|
||||
_bias[a * oc4 * pack + oz] = offset;
|
||||
}
|
||||
}
|
||||
}
|
||||
#else
|
||||
if(conv2d->symmetricQuan() && conv2d->symmetricQuan()->method() == QuantizeAlgo_OVERFLOW_AWARE){
|
||||
gemmKernel = core->Int8GemmKernelFast;
|
||||
}
|
||||
#endif
|
||||
mDeconvInt8Exe.reset(new GemmInt8Executor(b, mResource, convOp, gemmKernel, _bias));
|
||||
}
|
||||
}
|
||||
|
||||
ErrorCode CPUDeconvolutionOrigin::onResize(const std::vector<Tensor*>& inputs, const std::vector<Tensor*>& outputs) {
|
||||
CPUDeconvolutionBasic::onResize(inputs, outputs);
|
||||
|
|
@ -340,10 +389,13 @@ ErrorCode CPUDeconvolutionOrigin::onResize(const std::vector<Tensor*>& inputs, c
|
|||
}
|
||||
auto threadNumber = ((CPUBackend*)backend())->threadNumber();
|
||||
std::vector<float> scales(core->pack * src_height * src_width * batch, scale);
|
||||
auto outputFp32Ptr = allocator->alloc(batch * src_height * src_width * ocC4 * core->pack * bytes);
|
||||
MemChunk outputFp32Ptr;
|
||||
if (outi8) {
|
||||
outputFp32Ptr = allocator->alloc(batch * src_height * src_width * ocC4 * core->pack * bytes);
|
||||
if (outputFp32Ptr.invalid()) {
|
||||
return OUT_OF_MEMORY;
|
||||
}
|
||||
}
|
||||
|
||||
mPostFunctions.emplace_back(std::make_pair([ocC4, width, height, kh, kw, padY, padX, dilateY, dilateX, strideY,
|
||||
strideX, threadNumber, src_width, src_height, plane, input, biasTensor, this, core, gcore, batch, outi8, scale,
|
||||
|
|
@ -397,15 +449,9 @@ ErrorCode CPUDeconvolutionOrigin::onResize(const std::vector<Tensor*>& inputs, c
|
|||
}
|
||||
}
|
||||
}, threadNumber));
|
||||
/*
|
||||
if (TensorUtils::getDescribe(tempInput.get())->mem->chunk().offset() != TensorUtils::getDescribe(input)->mem->chunk().offset()) {
|
||||
backend()->onReleaseBuffer(tempInput.get(), Backend::DYNAMIC);
|
||||
}
|
||||
if (tempInput->host<float>() != inputPtr) {
|
||||
backend()->onReleaseBuffer(tempInput.get(), Backend::DYNAMIC);
|
||||
}
|
||||
*/
|
||||
if (outi8) {
|
||||
allocator->free(outputFp32Ptr);
|
||||
}
|
||||
if (needReleaseTempInput) {
|
||||
backend()->onReleaseBuffer(tempInput.get(), Backend::DYNAMIC);
|
||||
}
|
||||
|
|
@ -416,7 +462,7 @@ ErrorCode CPUDeconvolutionOrigin::onResize(const std::vector<Tensor*>& inputs, c
|
|||
ErrorCode CPUDeconvolutionOrigin::onExecute(const std::vector<Tensor*>& inputs, const std::vector<Tensor*>& outputs) {
|
||||
auto inputPtr = inputs[0]->host<uint8_t>();
|
||||
auto outputPtr = outputs[0]->host<uint8_t>();
|
||||
if (CPUBackend::getDataType(inputs[0]) == DataType_DT_INT8 || inputs[0]->getType().bytes() == 1) {
|
||||
if (mDeconvInt8Exe.get() != nullptr) {
|
||||
mDeconvInt8Exe->onExecute({inputs[0], inputs[1]}, {mTempOutput.get()});
|
||||
}
|
||||
else {
|
||||
|
|
|
|||
|
|
@ -38,56 +38,7 @@ protected:
|
|||
|
||||
class CPUDeconvolutionOrigin : public CPUDeconvolutionBasic {
|
||||
public:
|
||||
CPUDeconvolutionOrigin(const Tensor *input, Tensor *weight, const Op *convOp, Backend *b, bool ModeInt8)
|
||||
: CPUDeconvolutionBasic(input, convOp, b){
|
||||
if (ModeInt8) {
|
||||
const auto weightDataPtr = weight->host<int8_t>();
|
||||
auto conv2d = convOp->main_as_Convolution2D();
|
||||
auto common = conv2d->common();
|
||||
auto pack = static_cast<CPUBackend*>(b)->functions()->pack;
|
||||
mResource = CPUConvolution::makeResourceInt8(backend(), convOp, pack);
|
||||
CPUConvolution::MutableResourceInt8 mutableResource(mResource, b);
|
||||
auto core = static_cast<CPUBackend*>(b)->int8Functions();
|
||||
auto gemmKernel = core->Int8GemmKernel;
|
||||
int UNIT, SRC_UNIT, DST_XUNIT;
|
||||
core->MNNGetGemmUnit(&UNIT, &SRC_UNIT, &DST_XUNIT);
|
||||
const auto kEleCnt = mCommon->kernelX() * mCommon->kernelY();
|
||||
const int ocDiv4 = UP_DIV(common->outputCount(), pack) * kEleCnt;
|
||||
const int icDiv4 = UP_DIV(common->inputCount(), SRC_UNIT);
|
||||
const int ocDivUnit = UP_DIV(common->outputCount(), UNIT);
|
||||
const int oc4 = ocDiv4 / kEleCnt;
|
||||
const int bias_elesize = ocDiv4 * pack;
|
||||
// set offset if use SSE.
|
||||
auto inputQuant = TensorUtils::getQuantInfo(input);
|
||||
auto inputZeroPoint = inputQuant[1];
|
||||
std::vector<int32_t> _bias(bias_elesize, inputZeroPoint);
|
||||
#ifdef MNN_USE_SSE
|
||||
int actBits = conv2d->symmetricQuan()->nbits();
|
||||
if (actBits <= 7) {
|
||||
gemmKernel = core->Int8GemmKernelFast;
|
||||
}
|
||||
for (int a = 0; a < kEleCnt; ++a){
|
||||
for (int oz = 0; oz < ocDivUnit * UNIT; ++oz) {
|
||||
int offset = inputZeroPoint, oz4 = oz / UNIT, ozRemain = oz % UNIT;
|
||||
for (int sz = 0; sz < icDiv4 * SRC_UNIT; ++sz) {
|
||||
int sz4 = sz / SRC_UNIT, szRemain = sz % SRC_UNIT;
|
||||
int index = (((a * oc4 + oz4) * icDiv4 + sz4) * UNIT + ozRemain) * SRC_UNIT + szRemain;
|
||||
auto weightInt8Data = weightDataPtr[index];
|
||||
offset += weightInt8Data * (-128);
|
||||
}
|
||||
if (oz < oc4 * pack) {
|
||||
_bias[a * oc4 * pack + oz] = offset;
|
||||
}
|
||||
}
|
||||
}
|
||||
#else
|
||||
if(conv2d->symmetricQuan() && conv2d->symmetricQuan()->method() == QuantizeAlgo_OVERFLOW_AWARE){
|
||||
gemmKernel = core->Int8GemmKernelFast;
|
||||
}
|
||||
#endif
|
||||
mDeconvInt8Exe.reset(new GemmInt8Executor(b, mResource, convOp, gemmKernel, _bias));
|
||||
}
|
||||
}
|
||||
CPUDeconvolutionOrigin(const Tensor *input, Tensor *weight, const Op *convOp, Backend *b, bool ModeInt8);
|
||||
virtual ~CPUDeconvolutionOrigin() = default;
|
||||
virtual ErrorCode onExecute(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) override;
|
||||
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) override;
|
||||
|
|
|
|||
|
|
@ -35,8 +35,11 @@ CPUFloatToInt8::CPUFloatToInt8(Backend* backend, const MNN::Op* param) : Executi
|
|||
memset(mScales->host<float>(), 0, UP_DIV(scaleLen, pack) * pack * sizeof(float));
|
||||
memcpy(mScales->host<float>(), scale->tensorScale()->data(), scaleLen * sizeof(float));
|
||||
}
|
||||
|
||||
if (scale->floatzeros()) {
|
||||
mZeroPoint = scale->floatzeros()->data()[0];
|
||||
} else {
|
||||
mZeroPoint = static_cast<float>(scale->zeroPoint());
|
||||
}
|
||||
mClampMin = scale->clampMin();
|
||||
mClampMax = scale->clampMax();
|
||||
}
|
||||
|
|
|
|||
|
|
@ -21,7 +21,8 @@ CPUInt8ToFloat::CPUInt8ToFloat(Backend* backend, const MNN::Op* param) : Executi
|
|||
const int scaleLen = scale->tensorScale()->size();
|
||||
auto pack = static_cast<CPUBackend*>(backend)->functions()->pack;
|
||||
mScales.reset(Tensor::createDevice<float>({UP_DIV(scaleLen, pack) * pack}));
|
||||
mValid = backend->onAcquireBuffer(mScales.get(), Backend::STATIC);
|
||||
mZeroPoint.reset(Tensor::createDevice<float>({UP_DIV(scaleLen, pack) * pack}));
|
||||
mValid = backend->onAcquireBuffer(mScales.get(), Backend::STATIC) && backend->onAcquireBuffer(mZeroPoint.get(), Backend::STATIC);
|
||||
if (!mValid) {
|
||||
return;
|
||||
}
|
||||
|
|
@ -29,12 +30,24 @@ CPUInt8ToFloat::CPUInt8ToFloat(Backend* backend, const MNN::Op* param) : Executi
|
|||
mSingle = true;
|
||||
for (int i = 0; i < pack; ++i) {
|
||||
mScales->host<float>()[i] = scale->tensorScale()->data()[0];
|
||||
if (scale->floatzeros()) {
|
||||
mZeroPoint->host<float>()[i] = scale->floatzeros()->data()[0];
|
||||
}
|
||||
}
|
||||
} else {
|
||||
memset(mScales->host<float>(), 0, UP_DIV(scaleLen, pack) * pack * sizeof(float));
|
||||
memcpy(mScales->host<float>(), scale->tensorScale()->data(), scaleLen * sizeof(float));
|
||||
memset(mZeroPoint->host<float>(), 0, UP_DIV(scaleLen, pack) * pack * sizeof(float));
|
||||
if (scale->floatzeros()) {
|
||||
memcpy(mZeroPoint->host<float>(), scale->floatzeros()->data(), scale->floatzeros()->size() * sizeof(float));
|
||||
}
|
||||
mZeroPoint = scale->zeroPoint();
|
||||
}
|
||||
if (!scale->floatzeros()) {
|
||||
for (int i = 0;i < ROUND_UP(scaleLen, pack); ++i) {
|
||||
mZeroPoint->host<float>()[i] = static_cast<float>(scale->zeroPoint());
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
CPUInt8ToFloat::~CPUInt8ToFloat() {
|
||||
backend()->onReleaseBuffer(mScales.get(), Backend::STATIC);
|
||||
|
|
@ -48,6 +61,7 @@ ErrorCode CPUInt8ToFloat::onExecute(const std::vector<Tensor*>& inputs, const st
|
|||
const auto inputDataPtr = input->host<int8_t>();
|
||||
auto outputDataPtr = output->host<float>();
|
||||
const auto scaleDataPtr = mScales->host<float>();
|
||||
const auto zeroDataPtr = mZeroPoint->host<float>();
|
||||
const int channels = input->channel();
|
||||
int icDiv4 = UP_DIV(channels, pack);
|
||||
const int batch = input->batch();
|
||||
|
|
@ -67,8 +81,9 @@ ErrorCode CPUInt8ToFloat::onExecute(const std::vector<Tensor*>& inputs, const st
|
|||
int z = tId % icDiv4;
|
||||
const auto srcChannelPtr = inputDataPtr + tId * oc4Stride * pack;
|
||||
const auto scaleChannelPtr = scaleDataPtr + z * pack;
|
||||
const auto zeroChannelPtr = zeroDataPtr + z * pack;
|
||||
auto dstChannlePtr = outputDataPtr + tId * oc4Stride * pack;
|
||||
int8F->MNNInt8ScaleToFloat(dstChannlePtr, srcChannelPtr, scaleChannelPtr, oc4Stride, mZeroPoint);
|
||||
int8F->MNNInt8ScaleToFloat(dstChannlePtr, srcChannelPtr, scaleChannelPtr, oc4Stride, zeroChannelPtr, 3);
|
||||
}
|
||||
MNN_CONCURRENCY_END();
|
||||
|
||||
|
|
|
|||
|
|
@ -24,7 +24,7 @@ private:
|
|||
std::shared_ptr<Tensor> mScales;
|
||||
|
||||
bool mSingle = false;
|
||||
int8_t mZeroPoint;
|
||||
std::shared_ptr<Tensor> mZeroPoint;
|
||||
};
|
||||
|
||||
} // namespace MNN
|
||||
|
|
|
|||
|
|
@ -11,77 +11,74 @@
|
|||
#include "backend/cpu/CPUBackend.hpp"
|
||||
#include "backend/cpu/compute/ConvOpt.h"
|
||||
#include "backend/cpu/compute/CommonOptFunction.h"
|
||||
#include "math/Matrix.hpp"
|
||||
#include "core/TensorUtils.hpp"
|
||||
|
||||
namespace MNN {
|
||||
|
||||
static inline void ArrayProduct(float* C, float* A, float* B, const int length) {
|
||||
MNNMatrixProdCommon(C, A, B, length, 0, 0, 0, 1);
|
||||
return;
|
||||
}
|
||||
|
||||
// implement GRU cell function
|
||||
// Ref: tensorflow/python/ops/rnn_cell_impl.py
|
||||
void CPURNNSequenceGRU::runRNNStep(const float* input, const int inputLength, const bool linearBeforeReset,
|
||||
void CPURNNSequenceGRU::runRNNStep(const uint8_t* input, const int inputLength, const bool linearBeforeReset,
|
||||
std::shared_ptr<Tensor>& hiddenState, const int numUnits, Tensor* gateWeight, Tensor* gateBias,
|
||||
Tensor* candidateWeight, Tensor* candidateBias, Tensor* recurrentBias,
|
||||
std::shared_ptr<Tensor>& inputAndState, std::shared_ptr<Tensor>& gate,
|
||||
std::shared_ptr<Tensor>& resetHt) {
|
||||
auto bn = static_cast<CPUBackend*>(backend());
|
||||
auto mulFunction = bn->functions()->MNNSelectBinaryFunctionForFloat(BinaryOpOperation_MUL);
|
||||
auto addFunction = bn->functions()->MNNSelectBinaryFunctionForFloat(BinaryOpOperation_ADD);
|
||||
auto subFunction = bn->functions()->MNNSelectBinaryFunctionForFloat(BinaryOpOperation_SUB);
|
||||
auto tanhFunction = bn->functions()->MNNSelectUnaryFunctionForFloat(UnaryOpOperation_TANH, bn->precisionMode());
|
||||
auto bytes = bn->functions()->bytes;
|
||||
auto sigmoidFunc = bn->functions()->MNNSelectUnaryFunctionForFloat(UnaryOpOperation_SIGMOID, bn->precisionMode());
|
||||
// gate is (z_t, r_t)
|
||||
auto inputAndStatePtr = inputAndState->host<float>();
|
||||
auto hiddenStatePtr = hiddenState->host<float>();
|
||||
::memcpy(inputAndStatePtr, input, inputLength * sizeof(float));
|
||||
::memcpy(inputAndStatePtr + inputLength, hiddenStatePtr, numUnits * sizeof(float));
|
||||
auto inputAndStatePtr = inputAndState->host<uint8_t>();
|
||||
auto hiddenStatePtr = hiddenState->host<uint8_t>();
|
||||
::memcpy(inputAndStatePtr, input, inputLength * bytes);
|
||||
::memcpy(inputAndStatePtr + inputLength * bytes, hiddenStatePtr, numUnits * bytes);
|
||||
inputAndState->setLength(1, inputLength + numUnits);
|
||||
|
||||
// // [x_t, h_t-1] * [W_zr, R_zr]: (1, inputLength + numUnits) X (inputLength + numUnits, 2 * numUnits)
|
||||
mMatMulIU2U->execute(inputAndState->host<float>(), gateWeight->host<float>(), gate->host<float>(), gateBias->host<float>());
|
||||
|
||||
recurrentBias->setLength(1, 2 * numUnits);
|
||||
Math::Matrix::add(gate.get(), gate.get(), recurrentBias);
|
||||
addFunction(gate->host<float>(), gate->host<float>(), recurrentBias->host<float>(), 2*numUnits, -1);
|
||||
// (1, 2*numUnits)
|
||||
const int gateSize = gate->elementSize();
|
||||
auto gatePtr = gate->host<float>();
|
||||
auto core = bn->functions();
|
||||
auto sigmoidFunc = core->MNNSelectUnaryFunctionForFloat(UnaryOpOperation_SIGMOID, bn->precisionMode());
|
||||
auto gatePtr = gate->host<uint8_t>();
|
||||
sigmoidFunc(gatePtr, gatePtr, gateSize);
|
||||
// reset gate, // r_t is the second segment
|
||||
auto rtPtr = gatePtr + numUnits;
|
||||
auto rtPtr = gatePtr + numUnits * bytes;
|
||||
|
||||
if (linearBeforeReset) {
|
||||
// calculate Rt (.) (Ht_1 * Rh + Rbh)
|
||||
auto recurrentHiddenBiasPtr = recurrentBias->host<float>() + 2 * numUnits;
|
||||
auto rhWeightPtr = candidateWeight->host<float>() + inputLength * numUnits;
|
||||
mMatMulU2U->execute(hiddenState->host<float>(), rhWeightPtr, resetHt->host<float>(), recurrentHiddenBiasPtr);
|
||||
ArrayProduct(resetHt->host<float>(), rtPtr, resetHt->host<float>(), numUnits);
|
||||
auto recurrentHiddenBiasPtr = recurrentBias->host<uint8_t>() + 2 * numUnits * bytes;
|
||||
auto rhWeightPtr = candidateWeight->host<uint8_t>() + inputLength * numUnits * bytes;
|
||||
mMatMulU2U->execute(hiddenState->host<float>(), (float*)rhWeightPtr, resetHt->host<float>(), (float*)recurrentHiddenBiasPtr);
|
||||
mulFunction(resetHt->host<float>(), rtPtr, resetHt->host<float>(), numUnits, -1);
|
||||
|
||||
// calculate Xt * Wh
|
||||
mMatMulI2U->execute(input, candidateWeight->host<float>(), inputAndStatePtr + inputLength + numUnits, nullptr);
|
||||
mMatMulI2U->execute((float*)input, candidateWeight->host<float>(), (float*)(inputAndStatePtr + (inputLength + numUnits) * bytes), nullptr);
|
||||
// sum 3 parts
|
||||
Math::Matrix::add(resetHt->host<float>(), resetHt->host<float>(), inputAndStatePtr + inputLength + numUnits, numUnits);
|
||||
Math::Matrix::add(rtPtr, resetHt->host<float>(), candidateBias->host<float>(), numUnits);
|
||||
addFunction(resetHt->host<float>(), resetHt->host<float>(), inputAndStatePtr + (inputLength + numUnits) * bytes, numUnits, -1);
|
||||
addFunction(rtPtr, resetHt->host<float>(), candidateBias->host<float>(), numUnits, -1);
|
||||
|
||||
} else {
|
||||
// r_t: (1, numUnits)
|
||||
auto resetGatePtr = inputAndStatePtr + inputLength;
|
||||
auto resetGatePtr = inputAndStatePtr + inputLength * bytes;
|
||||
// h_t1(1, numUnits) = r_t(1, numUnits) * h_t-1_(1, numUnits)
|
||||
ArrayProduct(resetGatePtr, rtPtr, hiddenStatePtr, numUnits);
|
||||
mulFunction(resetGatePtr, rtPtr, hiddenStatePtr, numUnits, -1);
|
||||
// deal with recurrent bias and linear_before_reset parameter
|
||||
auto recurrentBiasAddedPtr = inputAndStatePtr + inputLength + numUnits;
|
||||
auto recurrentHiddenBiasPtr = recurrentBias->host<float>() + 2 * numUnits;
|
||||
Math::Matrix::add(recurrentBiasAddedPtr, recurrentHiddenBiasPtr, candidateBias->host<float>(), numUnits);
|
||||
auto recurrentBiasAddedPtr = inputAndStatePtr + (inputLength + numUnits) * bytes;
|
||||
auto recurrentHiddenBiasPtr = recurrentBias->host<float>() + 2 * numUnits * bytes;
|
||||
addFunction(recurrentBiasAddedPtr, recurrentHiddenBiasPtr, candidateBias->host<float>(), numUnits, -1);
|
||||
mMatMulI2U->execute(inputAndState->host<float>(), candidateWeight->host<float>(), resetHt->host<float>(), nullptr);
|
||||
// reuse r_t memory as h_t'
|
||||
Math::Matrix::add(rtPtr, resetHt->host<float>(), recurrentBiasAddedPtr, numUnits);
|
||||
addFunction(rtPtr, resetHt->host<float>(), recurrentBiasAddedPtr, numUnits, -1);
|
||||
}
|
||||
|
||||
for (int i = 0; i < numUnits; ++i) {
|
||||
hiddenStatePtr[i] =
|
||||
(1 - gatePtr[i]) * tanhf(rtPtr[i]) + gatePtr[i] * hiddenStatePtr[i];
|
||||
}
|
||||
|
||||
// h = (1-g)*t+g*h = t + g*(h-t)
|
||||
tanhFunction(resetHt->host<float>(), rtPtr, numUnits);
|
||||
subFunction(hiddenStatePtr, hiddenStatePtr, resetHt->host<float>(), numUnits, -1);
|
||||
mulFunction(hiddenStatePtr, hiddenStatePtr, gatePtr, numUnits, -1);
|
||||
addFunction(hiddenStatePtr, hiddenStatePtr, resetHt->host<float>(), numUnits, -1);
|
||||
inputAndState->setLength(1, inputLength + 2 * numUnits);
|
||||
}
|
||||
|
||||
|
|
@ -162,6 +159,7 @@ ErrorCode CPURNNSequenceGRU::onExecute(const std::vector<Tensor*>& inputs, const
|
|||
auto fwCandidateBias = inputs[4];
|
||||
auto fwRecurrentBias = inputs[5];
|
||||
auto cpuBn = static_cast<CPUBackend*>(backend());
|
||||
auto bytes = cpuBn->functions()->bytes;
|
||||
|
||||
// fwGateWeight->printShape();// mFwGateWeight
|
||||
// fwGateBias->printShape();// mFwGateBias
|
||||
|
|
@ -170,15 +168,15 @@ ErrorCode CPURNNSequenceGRU::onExecute(const std::vector<Tensor*>& inputs, const
|
|||
// fwRecurrentBias->printShape();// mFwRecurrentBias
|
||||
|
||||
// firstly set the hidden state to zero
|
||||
float* const hiddenStatePtr = mHiddenState->host<float>();
|
||||
const int hiddenStateDataSize = mHiddenState->size();
|
||||
auto const hiddenStatePtr = mHiddenState->host<uint8_t>();
|
||||
const int hiddenStateDataSize = mHiddenState->elementSize() * bytes;
|
||||
|
||||
auto input = inputs[0]; // shape :(seq_length, batch_size, input_size)
|
||||
auto output = outputs[0]; // shape :(seq_length, num_directions, batch_size, hidden_size)
|
||||
float* const inputPtr = input->host<float>();
|
||||
float* const outputPtr = output->host<float>();
|
||||
auto const inputPtr = input->host<uint8_t>();
|
||||
auto const outputPtr = output->host<uint8_t>();
|
||||
|
||||
float* outputYhPtr = mKeepAllOutputs && outputSize > 1 ? outputs[1]->host<float>() : outputs[0]->host<float>();
|
||||
auto outputYhPtr = mKeepAllOutputs && outputSize > 1 ? outputs[1]->host<uint8_t>() : outputs[0]->host<uint8_t>();
|
||||
const int batchSize = input->length(1);
|
||||
const int SequenceStride = input->stride(0);
|
||||
const int inputSequenceLength = input->length(0);
|
||||
|
|
@ -194,24 +192,24 @@ ErrorCode CPURNNSequenceGRU::onExecute(const std::vector<Tensor*>& inputs, const
|
|||
|
||||
for (int i = 0; i < inputSequenceLength; ++i) {
|
||||
const int inputOffset = i * SequenceStride + b * inputCodeLength;
|
||||
runRNNStep(inputPtr + inputOffset, inputCodeLength, mlinearBeforeReset, mHiddenState, mNumUnits, fwGateWeight, fwGateBias,
|
||||
runRNNStep(inputPtr + inputOffset * bytes, inputCodeLength, mlinearBeforeReset, mHiddenState, mNumUnits, fwGateWeight, fwGateBias,
|
||||
fwCandidateWeight, fwCandidateBias, fwRecurrentBias, mInputAndState, mGate, mResetHt);
|
||||
|
||||
if (mKeepAllOutputs) {
|
||||
::memcpy(outputPtr + i * output->stride(0) + b * mNumUnits, hiddenStatePtr, hiddenStateDataSize);
|
||||
::memcpy(outputPtr + (i * output->stride(0) + b * mNumUnits) * bytes, hiddenStatePtr, hiddenStateDataSize);
|
||||
}
|
||||
}
|
||||
if ((mKeepAllOutputs && outputSize > 1) || !mKeepAllOutputs) {
|
||||
::memcpy(outputYhPtr, hiddenStatePtr, hiddenStateDataSize);
|
||||
outputYhPtr += mNumUnits;
|
||||
outputYhPtr += mNumUnits * bytes;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
// backward rnn
|
||||
if (mIsBidirectionalRNN) {
|
||||
float* outputYhPtr = mKeepAllOutputs && outputSize > 1 ? outputs[1]->host<float>() : outputs[0]->host<float>();
|
||||
outputYhPtr += batchSize * mNumUnits;
|
||||
auto outputYhPtr = mKeepAllOutputs && outputSize > 1 ? outputs[1]->host<uint8_t>() : outputs[0]->host<uint8_t>();
|
||||
outputYhPtr += batchSize * mNumUnits * bytes;
|
||||
// todo: modify the inputOffset
|
||||
MNN_ASSERT(11 <= inputs.size());
|
||||
auto bwGateWeight = inputs[6];
|
||||
|
|
@ -221,7 +219,7 @@ ErrorCode CPURNNSequenceGRU::onExecute(const std::vector<Tensor*>& inputs, const
|
|||
auto bwRecurrentBias = inputs[10];
|
||||
|
||||
auto outputBw = outputs[0];
|
||||
float* const outputBwPtr = outputBw->host<float>();
|
||||
auto const outputBwPtr = outputBw->host<uint8_t>();
|
||||
for (int b = 0; b < batchSize; ++b) {
|
||||
|
||||
if (inputSize > 1 + forwardParamNumber * 2) {
|
||||
|
|
@ -233,16 +231,16 @@ ErrorCode CPURNNSequenceGRU::onExecute(const std::vector<Tensor*>& inputs, const
|
|||
|
||||
for (int i = inputSequenceLength - 1; i >= 0; i--) {
|
||||
const int inputOffset = i * SequenceStride + b * inputCodeLength;
|
||||
runRNNStep(inputPtr + inputOffset, inputCodeLength, mlinearBeforeReset, mHiddenState, mNumUnits, bwGateWeight, bwGateBias,
|
||||
runRNNStep(inputPtr + inputOffset * bytes, inputCodeLength, mlinearBeforeReset, mHiddenState, mNumUnits, bwGateWeight, bwGateBias,
|
||||
bwCandidateWeight, bwCandidateBias, bwRecurrentBias, mInputAndState, mGate, mResetHt);
|
||||
if (mKeepAllOutputs) {
|
||||
::memcpy(outputBwPtr + i * outputBw->stride(0) + (batchSize + b) * mNumUnits,
|
||||
::memcpy(outputBwPtr + (i * outputBw->stride(0) + (batchSize + b) * mNumUnits) * bytes,
|
||||
hiddenStatePtr, hiddenStateDataSize);
|
||||
}
|
||||
}
|
||||
if ((mKeepAllOutputs && outputSize > 1) || !mKeepAllOutputs) {
|
||||
::memcpy(outputYhPtr, hiddenStatePtr, hiddenStateDataSize);
|
||||
outputYhPtr += mNumUnits;
|
||||
outputYhPtr += mNumUnits * bytes;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ public:
|
|||
virtual ErrorCode onResize(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) override;
|
||||
|
||||
private:
|
||||
void runRNNStep(const float* input, const int inputLength, const bool linearBeforeReset,
|
||||
void runRNNStep(const uint8_t* input, const int inputLength, const bool linearBeforeReset,
|
||||
std::shared_ptr<Tensor>& hiddenState, const int numUnits, Tensor* gateWeight, Tensor* gateBias,
|
||||
Tensor* candidateWeight, Tensor* candidateBias, Tensor* recurrentBias,
|
||||
std::shared_ptr<Tensor>& inputAndState, std::shared_ptr<Tensor>& gate,
|
||||
|
|
|
|||
|
|
@ -12,14 +12,12 @@ namespace MNN {
|
|||
|
||||
ErrorCode CPUUnique::onExecute(const std::vector<Tensor *> &inputs, const std::vector<Tensor *> &outputs) {
|
||||
auto input = inputs[0];
|
||||
if (input->getType().code != halide_type_int) {
|
||||
return NOT_SUPPORT;
|
||||
}
|
||||
auto output = outputs[0];
|
||||
auto outputPtr = output->host<int32_t>();
|
||||
int outputSize = 0;
|
||||
std::unordered_map<int, int> idx_map;
|
||||
auto eleSize = input->elementSize();
|
||||
if (outputs.size() <= 2) {
|
||||
std::unordered_map<int, int> idx_map;
|
||||
for (int i = 0; i < eleSize; ++i) {
|
||||
auto value = input->host<int32_t>()[i];
|
||||
if (idx_map.find(value) == idx_map.end()) {
|
||||
|
|
@ -38,6 +36,28 @@ ErrorCode CPUUnique::onExecute(const std::vector<Tensor *> &inputs, const std::v
|
|||
}
|
||||
}
|
||||
}
|
||||
} else {
|
||||
MNN_ASSERT(4 == outputs.size());
|
||||
auto outIdx = outputs[1]->host<int>();
|
||||
auto reverseIdx = outputs[2]->host<int>();
|
||||
auto count = outputs[3]->host<int>();
|
||||
::memset(count, 0, outputs[3]->usize());
|
||||
std::unordered_map<int, int> idx_map;
|
||||
for (int i = 0; i < eleSize; ++i) {
|
||||
auto value = input->host<int32_t>()[i];
|
||||
auto iter = idx_map.find(value);
|
||||
int pos;
|
||||
if (iter == idx_map.end()) {
|
||||
outputPtr[outputSize] = value;
|
||||
outIdx[outputSize] = i;
|
||||
pos = outputSize;
|
||||
idx_map[value] = outputSize++;
|
||||
} else {
|
||||
pos = iter->second;
|
||||
}
|
||||
reverseIdx[i] = pos;
|
||||
}
|
||||
}
|
||||
return NO_ERROR;
|
||||
}
|
||||
class CPUUniqueCreator : public CPUBackend::Creator {
|
||||
|
|
|
|||
|
|
@ -68,7 +68,7 @@ Execution* OneDNNConvInt8::create(Backend* backend, const MNN::Convolution2D* co
|
|||
}
|
||||
std::shared_ptr<ConvolutionCommon::Int8Common> quanCommon;
|
||||
if (convParam->quanParameter() != nullptr) {
|
||||
quanCommon = ConvolutionCommon::load(convParam, backend(), false);
|
||||
quanCommon = ConvolutionCommon::load(convParam, backend, false);
|
||||
weightSrc = quanCommon->weight.get();
|
||||
}
|
||||
auto user_weights = memory(user_weights_md, eng, (int8_t*)weightSrc);
|
||||
|
|
|
|||
|
|
@ -172,9 +172,6 @@ L2LoopDz:
|
|||
vpadd.s32 d18, d24, d26
|
||||
vpadd.s32 d19, d28, d30
|
||||
|
||||
// vaddq.s32 q0, q8, q4 // add bias
|
||||
// vaddq.s32 q1, q9, q4
|
||||
|
||||
vcvt.f32.s32 q0, q8
|
||||
vcvt.f32.s32 q1, q9
|
||||
|
||||
|
|
@ -295,7 +292,6 @@ L1LoopDz:
|
|||
vmlal.s8 q0, d5, d13
|
||||
vmlal.s8 q1, d5, d15
|
||||
vpaddl.s16 q10, q0
|
||||
add r1, r1, #16
|
||||
vpaddl.s16 q11, q1
|
||||
|
||||
beq L1LoopSzEnd
|
||||
|
|
@ -316,7 +312,7 @@ L1LoopDz:
|
|||
vmull.s8 q1, d4, d14
|
||||
vmlal.s8 q0, d5, d13
|
||||
vmlal.s8 q1, d5, d15
|
||||
add r1, r1, #16
|
||||
|
||||
vpadal.s16 q10, q0
|
||||
vpadal.s16 q11, q1
|
||||
|
||||
|
|
|
|||
|
|
@ -147,9 +147,6 @@ L2LoopDz:
|
|||
vpadd.s32 d18, d24, d25
|
||||
vpadd.s32 d19, d26, d27
|
||||
|
||||
//vaddq.s32 q0, q8, q14 // add bias
|
||||
//vaddq.s32 q1, q9, q14
|
||||
|
||||
vcvt.f32.s32 q0, q8
|
||||
vcvt.f32.s32 q1, q9
|
||||
vmulq.f32 q0, q0, q15 // mul scale
|
||||
|
|
@ -210,7 +207,6 @@ L1LoopDz:
|
|||
vmull.s8 q8, d0, d4
|
||||
vld1.8 {q4,q5}, [r2]!
|
||||
vmull.s8 q9, d0, d6
|
||||
add r1, r1, #16
|
||||
vmull.s8 q10, d0, d8
|
||||
subs r12, r3, #1
|
||||
vmull.s8 q11, d0, d10
|
||||
|
|
@ -230,7 +226,7 @@ L1LoopDz:
|
|||
|
||||
vmlal.s8 q8, d0, d4
|
||||
vmlal.s8 q9, d0, d6
|
||||
add r1, r1, #16
|
||||
|
||||
vmlal.s8 q10, d0, d8
|
||||
vmlal.s8 q11, d0, d10
|
||||
|
||||
|
|
@ -262,8 +258,6 @@ L1LoopDz:
|
|||
vpadd.s32 d16, d20, d21
|
||||
vpadd.s32 d17, d22, d23
|
||||
|
||||
//vaddq.s32 q0, q8, q14
|
||||
|
||||
vcvt.f32.s32 q0, q8
|
||||
vmulq.f32 q0, q0, q15
|
||||
|
||||
|
|
|
|||
|
|
@ -280,7 +280,7 @@ L1LoopDz:
|
|||
vmlal.s8 q0, d5, d13
|
||||
vmlal.s8 q1, d5, d15
|
||||
vpaddl.s16 q10, q0
|
||||
add r1, r1, #16
|
||||
|
||||
vpaddl.s16 q11, q1
|
||||
|
||||
beq L1LoopSzEnd
|
||||
|
|
@ -307,7 +307,7 @@ L1LoopDz:
|
|||
vmull.s8 q1, d4, d14
|
||||
vmlal.s8 q0, d5, d13
|
||||
vmlal.s8 q1, d5, d15
|
||||
add r1, r1, #16
|
||||
|
||||
vpadal.s16 q10, q0
|
||||
vpadal.s16 q11, q1
|
||||
|
||||
|
|
|
|||
|
|
@ -16,19 +16,40 @@
|
|||
|
||||
asm_function MNNInt8ScaleToFloat
|
||||
|
||||
// void MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t size, ssize_t zeroPoint)
|
||||
|
||||
// void MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t size, const float* zeroPoint, ssize_t quanParamVec)
|
||||
// Auto Load: r0: dst*, r1: src*, r2: scale*, r3: size,
|
||||
// Load from sp: r4: zeroPoint, r5: quanParamVec
|
||||
push {lr}
|
||||
ldr r12, [sp, #4]
|
||||
vdup.s32 q13, r12
|
||||
vcvt.f32.s32 q13, q13
|
||||
|
||||
vld1.32 {d30[0]}, [r2] // scale
|
||||
vdup.32 q15, d30[0]
|
||||
|
||||
ldr r12, [sp, #4]
|
||||
vld1.32 {d26[0]},[r12] // zero
|
||||
vdup.32 q13, d26[0]
|
||||
|
||||
ldr lr, [sp, #8] // quanParamVec
|
||||
cmp lr, #0
|
||||
beq COMPUTE
|
||||
|
||||
cmp lr, #3
|
||||
bne LOAD_VEC_ZERO
|
||||
vld1.32 {q15}, [r2]
|
||||
vld1.32 {q13}, [r12]
|
||||
b COMPUTE
|
||||
|
||||
LOAD_VEC_ZERO:
|
||||
cmp lr, #2
|
||||
bne LOAD_VEC_SCALE
|
||||
vld1.32 {q13}, [r12]
|
||||
b COMPUTE
|
||||
|
||||
LOAD_VEC_SCALE:
|
||||
vld1.32 {q15}, [r2]
|
||||
|
||||
COMPUTE:
|
||||
vpush {q4-q7}
|
||||
|
||||
// Auto Load:
|
||||
// r0: dst*, r1: src*, r2: scale*, r3: size, r4: zeroPoint
|
||||
|
||||
vld1.32 {q15}, [r2]
|
||||
|
||||
L4:
|
||||
cmp r3, #4
|
||||
|
|
|
|||
|
|
@ -120,7 +120,7 @@ ldr x21, [x15, #64] // blockNum
|
|||
ldr x23, [x15, #80] // extraScale
|
||||
lsl x21, x3, #6 // src_depth_quad* SRC_UNIT * UNIT * sizeof(int8_t)
|
||||
add x20, x19, #4
|
||||
|
||||
lsl x24, x8, #4 // eDest * SRC_UNIT
|
||||
Start:
|
||||
cmp x8, #3
|
||||
beq L3Dz
|
||||
|
|
@ -367,8 +367,7 @@ L3LoopDz:
|
|||
mov x8, x1
|
||||
mov x22, x2
|
||||
ld1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x2], #64
|
||||
ld1 {v4.16b, v5.16b, v6.16b}, [x1], #48
|
||||
add x1, x1, #16
|
||||
ld1 {v4.16b, v5.16b, v6.16b}, [x1], x24
|
||||
|
||||
smull v8.8h, v0.8b, v4.8b
|
||||
smull v9.8h, v1.8b, v4.8b
|
||||
|
|
@ -418,7 +417,7 @@ L3LoopDz:
|
|||
beq L3ComputeSum
|
||||
|
||||
L3LoopSz:
|
||||
ld1 {v4.16b, v5.16b, v6.16b}, [x1], #48
|
||||
ld1 {v4.16b, v5.16b, v6.16b}, [x1], x24
|
||||
ld1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x2], #64
|
||||
|
||||
smull v8.8h, v0.8b, v4.8b
|
||||
|
|
@ -454,7 +453,6 @@ L3LoopDz:
|
|||
smull v11.8h, v3.8b, v6.8b
|
||||
|
||||
subs x9, x9, #1
|
||||
add x1, x1, #16
|
||||
|
||||
smlal2 v8.8h, v0.16b, v6.16b
|
||||
smlal2 v9.8h, v1.16b, v6.16b
|
||||
|
|
@ -571,7 +569,7 @@ L2LoopDz:
|
|||
mov x8, x1
|
||||
mov x22, x2
|
||||
ld1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x2], #64
|
||||
ld1 {v4.16b, v5.16b}, [x1], #32
|
||||
ld1 {v4.16b, v5.16b}, [x1], x24
|
||||
|
||||
|
||||
smull v8.8h, v0.8b, v4.8b
|
||||
|
|
@ -582,7 +580,7 @@ L2LoopDz:
|
|||
smull v13.8h, v1.8b, v5.8b
|
||||
smull v14.8h, v2.8b, v5.8b
|
||||
smull v15.8h, v3.8b, v5.8b
|
||||
add x1, x1, #32
|
||||
|
||||
smlal2 v8.8h, v0.16b, v4.16b
|
||||
smlal2 v9.8h, v1.16b, v4.16b
|
||||
smlal2 v10.8h, v2.16b, v4.16b
|
||||
|
|
@ -606,7 +604,7 @@ L2LoopDz:
|
|||
beq L2ComputeSum
|
||||
|
||||
L2LoopSz:
|
||||
ld1 {v4.16b, v5.16b}, [x1], #32
|
||||
ld1 {v4.16b, v5.16b}, [x1], x24
|
||||
ld1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x2], #64
|
||||
|
||||
smull v8.8h, v0.8b, v4.8b
|
||||
|
|
@ -622,7 +620,7 @@ L2LoopDz:
|
|||
smlal2 v9.8h, v1.16b, v4.16b
|
||||
smlal2 v10.8h, v2.16b, v4.16b
|
||||
smlal2 v11.8h, v3.16b, v4.16b
|
||||
add x1, x1, #32
|
||||
|
||||
subs x9, x9, #1
|
||||
smlal2 v12.8h, v0.16b, v5.16b
|
||||
smlal2 v13.8h, v1.16b, v5.16b
|
||||
|
|
@ -727,8 +725,7 @@ L1LoopDz:
|
|||
ld1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x2], #64
|
||||
dup v16.4s, wzr
|
||||
dup v17.4s, wzr
|
||||
ld1 {v4.16b}, [x1], #16
|
||||
add x1, x1, #48
|
||||
ld1 {v4.16b}, [x1], x24
|
||||
|
||||
smull v8.8h, v0.8b, v4.8b
|
||||
dup v18.4s, wzr
|
||||
|
|
@ -745,7 +742,7 @@ L1LoopDz:
|
|||
|
||||
L1LoopSz:
|
||||
sadalp v16.4s, v8.8h
|
||||
ld1 {v4.16b}, [x1], #16
|
||||
ld1 {v4.16b}, [x1], x24
|
||||
sadalp v17.4s, v9.8h
|
||||
sadalp v18.4s, v10.8h
|
||||
sadalp v19.4s, v11.8h
|
||||
|
|
@ -755,7 +752,6 @@ L1LoopDz:
|
|||
sadalp v23.4s, v15.8h
|
||||
|
||||
ld1 {v0.16b, v1.16b, v2.16b, v3.16b}, [x2], #64
|
||||
add x1, x1, #48
|
||||
|
||||
smull v8.8h, v0.8b, v4.8b
|
||||
smull v9.8h, v1.8b, v4.8b
|
||||
|
|
@ -776,7 +772,6 @@ L1LoopDz:
|
|||
sadalp v18.4s, v10.8h
|
||||
sadalp v19.4s, v11.8h
|
||||
|
||||
//ld1 {v0.4s}, [x10], #16
|
||||
addp v4.4s, v16.4s, v17.4s
|
||||
addp v5.4s, v18.4s, v19.4s
|
||||
|
||||
|
|
|
|||
|
|
@ -228,11 +228,6 @@ L4LoopDz:
|
|||
addp v14.4s, v20.4s, v21.4s
|
||||
addp v15.4s, v22.4s, v23.4s
|
||||
|
||||
//add v16.4s, v12.4s, v0.4s
|
||||
//add v17.4s, v13.4s, v0.4s
|
||||
//add v18.4s, v14.4s, v0.4s
|
||||
//add v19.4s, v15.4s, v0.4s
|
||||
|
||||
L4Quan:
|
||||
ld1 {v1.4s}, [x7], #16 // scale
|
||||
ld1 {v2.4s}, [x19] // x kernel sum
|
||||
|
|
@ -329,7 +324,7 @@ L3LoopDz:
|
|||
smull v23.8h, v3.8b, v5.8b
|
||||
smull v24.8h, v0.8b, v6.8b
|
||||
smull v25.8h, v1.8b, v6.8b
|
||||
add x1, x1, #16
|
||||
// add x1, x1, #16
|
||||
smull v26.8h, v2.8b, v6.8b
|
||||
smull v27.8h, v3.8b, v6.8b
|
||||
subs x9, x9, #1
|
||||
|
|
@ -357,7 +352,7 @@ L3LoopDz:
|
|||
ld1 {v2.16b}, [x2], #16
|
||||
|
||||
smlal v16.8h, v0.8b, v4.8b
|
||||
add x1, x1, #16
|
||||
|
||||
smlal v17.8h, v1.8b, v4.8b
|
||||
ld1 {v3.16b}, [x2], #16
|
||||
smlal v18.8h, v2.8b, v4.8b
|
||||
|
|
@ -490,7 +485,7 @@ L2LoopDz:
|
|||
smull v21.8h, v1.8b, v5.8b
|
||||
smull v22.8h, v2.8b, v5.8b
|
||||
smull v23.8h, v3.8b, v5.8b
|
||||
add x1, x1, #32
|
||||
|
||||
subs x9, x9, #1
|
||||
|
||||
beq L2LoopSzEnd
|
||||
|
|
@ -511,7 +506,6 @@ L2LoopDz:
|
|||
ld1 {v2.16b}, [x2], #16
|
||||
|
||||
smlal v16.8h, v0.8b, v4.8b
|
||||
add x1, x1, #32
|
||||
smlal v17.8h, v1.8b, v4.8b
|
||||
ld1 {v3.16b}, [x2], #16
|
||||
smlal v18.8h, v2.8b, v4.8b
|
||||
|
|
@ -611,7 +605,7 @@ L1LoopDz:
|
|||
smull v17.8h, v1.8b, v4.8b
|
||||
smull v18.8h, v2.8b, v4.8b
|
||||
smull v19.8h, v3.8b, v4.8b
|
||||
add x1, x1, #48
|
||||
|
||||
subs x9, x3, #1
|
||||
|
||||
beq L1LoopSzEnd
|
||||
|
|
@ -627,7 +621,6 @@ L1LoopDz:
|
|||
ld1 {v2.16b}, [x2], #16
|
||||
|
||||
smlal v16.8h, v0.8b, v4.8b
|
||||
add x1, x1, #48
|
||||
smlal v17.8h, v1.8b, v4.8b
|
||||
ld1 {v3.16b}, [x2], #16
|
||||
smlal v18.8h, v2.8b, v4.8b
|
||||
|
|
|
|||
|
|
@ -138,7 +138,7 @@ cbnz w28, Start
|
|||
mov x21, #16 // sizeof(float) * pack
|
||||
ldr x23, [x6, #56] // fp32minmax
|
||||
Start:
|
||||
mov x22, #48 // src_steps
|
||||
lsl x22, x7, #2 // eDest * SRC_UNIT
|
||||
|
||||
TILE_12:
|
||||
cmp x7, #12
|
||||
|
|
@ -483,7 +483,6 @@ TILE_8:
|
|||
cmp x5, #2
|
||||
blt L4LoopDz_TILE_8
|
||||
L8LoopDz_TILE_8:
|
||||
//ld1 {v0.4s, v1.4s}, [x20], #32 // bias
|
||||
mov x11, x1
|
||||
mov x13, x3
|
||||
mov x27, x12
|
||||
|
|
@ -640,7 +639,6 @@ L8LoopDz_TILE_8:
|
|||
cbz x14, Tile8End
|
||||
|
||||
L4LoopDz_TILE_8:
|
||||
//ld1 {v0.4s}, [x20], #16 // bias
|
||||
mov x11, x1
|
||||
mov x13, x3
|
||||
|
||||
|
|
@ -868,7 +866,6 @@ L8LoopDz_TILE_4:
|
|||
cbz x14, Tile4End
|
||||
|
||||
L4LoopDz_TILE_4:
|
||||
//ld1 {v0.4s}, [x20], #16 // bias
|
||||
mov x11, x1
|
||||
mov x13, x3
|
||||
SET_BIAS v8, v9, v10, v11
|
||||
|
|
@ -962,7 +959,6 @@ TILE_1:
|
|||
cmp x5, #2
|
||||
blt L4LoopDz_TILE_1
|
||||
L8LoopDz_TILE_1:
|
||||
//ld1 {v0.4s, v1.4s}, [x20], #32 // bias
|
||||
mov x11, x1
|
||||
mov x13, x3
|
||||
mov x27, x12
|
||||
|
|
@ -1056,7 +1052,6 @@ L8LoopDz_TILE_1:
|
|||
cbz x14, Tile1End
|
||||
|
||||
L4LoopDz_TILE_1:
|
||||
//ld1 {v0.4s}, [x20], #16 // bias
|
||||
mov x11, x1
|
||||
mov x13, x3
|
||||
movi v8.16b, #0
|
||||
|
|
|
|||
|
|
@ -148,7 +148,7 @@ mov x21, #16 // sizeof(float) * pack
|
|||
ldr x14, [x6, #56] // float32 maxmin ptr
|
||||
|
||||
Start:
|
||||
mov x22, #80 // GEMM_INT8_DST_XUNIT * GEMM_INT8_SRC_UNIT = 10 * 8 = 80
|
||||
lsl x22, x7, #3 // eDest * GEMM_INT8_SRC_UNIT
|
||||
|
||||
TILE_10:
|
||||
cmp x7, #10
|
||||
|
|
|
|||
|
|
@ -16,22 +16,35 @@
|
|||
asm_function MNNInt8ScaleToFloat
|
||||
|
||||
// void MNNInt8ScaleToFloat(float* dst,
|
||||
// const int8_t* src, const float* scale, size_t size, ssize_t zeroPoint)
|
||||
// const int8_t* src, const float* scale, size_t size, const float* zeroPoint, ssize_t quanParamVec)
|
||||
|
||||
// Auto Load:
|
||||
// x0: dst*, x1: src*, x2: scale*, x3: size, x4: zeroPoint
|
||||
// x0: dst*, x1: src*, x2: scale*, x3: size, x4: zeroPoint, x5: quanParamVec
|
||||
|
||||
// copy zero point
|
||||
mov v28.s[0], w4
|
||||
mov v28.s[1], w4
|
||||
mov v28.s[2], w4
|
||||
mov v28.s[3], w4
|
||||
scvtf v28.4s, v28.4s
|
||||
ld1r {v28.4s}, [x4] // zero
|
||||
ld1r {v16.4s}, [x2] // scale
|
||||
cbz x5, COMPUTE
|
||||
|
||||
cmp x5, #3
|
||||
bne LOAD_VEC_ZERO
|
||||
ld1 {v28.4s}, [x4]
|
||||
ld1 {v16.4s}, [x2]
|
||||
b COMPUTE
|
||||
|
||||
LOAD_VEC_ZERO:
|
||||
cmp x5, #2
|
||||
bne LOAD_VEC_SCALE
|
||||
ld1 {v28.4s}, [x4]
|
||||
b COMPUTE
|
||||
|
||||
LOAD_VEC_SCALE:
|
||||
ld1 {v16.4s}, [x2]
|
||||
|
||||
COMPUTE:
|
||||
cmp x3, #0
|
||||
beq End
|
||||
|
||||
ld1 {v16.4s}, [x2]
|
||||
|
||||
|
||||
L4:
|
||||
cmp x3, #4
|
||||
|
|
|
|||
|
|
@ -34,8 +34,6 @@ ldr x8, [x4, #32] // blockNum
|
|||
ldr x5, [x4, #40] // oneScale
|
||||
ldr x4, [x4, #0] // kernelCountUnitDouble
|
||||
|
||||
//ldr x8, [sp, #0] // blockNum
|
||||
|
||||
stp d14, d15, [sp, #(-16 * 4)]!
|
||||
stp d12, d13, [sp, #(16 * 1)]
|
||||
stp d10, d11, [sp, #(16 * 2)]
|
||||
|
|
@ -43,7 +41,6 @@ stp d8, d9, [sp, #(16 * 3)]
|
|||
|
||||
movi v31.16b, #1
|
||||
ld1r {v30.4s}, [x2] // Dequant scale
|
||||
mov x6, #48 // EP*LP
|
||||
sdiv x4, x4, x8 // src_depth_quad per block
|
||||
|
||||
TILE_12:
|
||||
|
|
@ -103,6 +100,7 @@ Remain: // remain realDstCount < EP
|
|||
cbz x3, End
|
||||
/* x11: Remain dstCount step for each block */
|
||||
lsl x11, x3, #2
|
||||
lsl x6, x3, #2 // x6=eDest * LP
|
||||
|
||||
TILE_2: // realDstCount >= 1
|
||||
cmp x3, #2
|
||||
|
|
|
|||
|
|
@ -39,13 +39,13 @@ stp d8, d9, [sp, #(16 * 3)]
|
|||
|
||||
movi v31.16b, #1
|
||||
ld1r {v30.4s}, [x2] // dequant scale
|
||||
mov x8, #80 // EP*LP
|
||||
sdiv x5, x5, x6 // src_depth_quad_per_block
|
||||
|
||||
START:
|
||||
lsl x11, x3, #2
|
||||
|
||||
cmp x3, #1
|
||||
mov x8, #8 // for LLM decode, otherwise update in Remain
|
||||
beq TILE_1
|
||||
|
||||
TILE_10: // realDstCount >= EP(10)
|
||||
|
|
@ -114,6 +114,7 @@ Remain: // remain realDstCount < EP
|
|||
cbz x3, End
|
||||
|
||||
lsl x11, x3, #2
|
||||
lsl x8, x3, #3 // x8: eDest*LP
|
||||
/* For remain dstCount, each E's block step is x11. */
|
||||
TILE_8: // realDstCount >= 8
|
||||
cmp x3, #8
|
||||
|
|
|
|||
|
|
@ -344,7 +344,6 @@ L3LoopDz:
|
|||
mov x22, x2
|
||||
ld1 {v10.16b, v11.16b}, [x2], #32
|
||||
ld1 {v4.16b, v5.16b, v6.16b}, [x1], #48
|
||||
add x1, x1, #16
|
||||
// int4->int8
|
||||
movi v8.16b, #15
|
||||
ushr v0.16b, v10.16b, #4
|
||||
|
|
@ -442,7 +441,6 @@ L3LoopDz:
|
|||
smull v11.8h, v3.8b, v6.8b
|
||||
|
||||
subs x9, x9, #1
|
||||
add x1, x1, #16
|
||||
|
||||
smlal2 v8.8h, v0.16b, v6.16b
|
||||
smlal2 v9.8h, v1.16b, v6.16b
|
||||
|
|
@ -544,7 +542,7 @@ L2LoopDz:
|
|||
smull v13.8h, v1.8b, v5.8b
|
||||
smull v14.8h, v2.8b, v5.8b
|
||||
smull v15.8h, v3.8b, v5.8b
|
||||
add x1, x1, #32
|
||||
|
||||
smlal2 v8.8h, v0.16b, v4.16b
|
||||
smlal2 v9.8h, v1.16b, v4.16b
|
||||
smlal2 v10.8h, v2.16b, v4.16b
|
||||
|
|
@ -590,7 +588,7 @@ L2LoopDz:
|
|||
smlal2 v9.8h, v1.16b, v4.16b
|
||||
smlal2 v10.8h, v2.16b, v4.16b
|
||||
smlal2 v11.8h, v3.16b, v4.16b
|
||||
add x1, x1, #32
|
||||
|
||||
subs x9, x9, #1
|
||||
smlal2 v12.8h, v0.16b, v5.16b
|
||||
smlal2 v13.8h, v1.16b, v5.16b
|
||||
|
|
@ -680,7 +678,6 @@ L1LoopDz:
|
|||
dup v16.4s, wzr
|
||||
dup v17.4s, wzr
|
||||
ld1 {v4.16b}, [x1], #16
|
||||
add x1, x1, #48
|
||||
|
||||
smull v8.8h, v0.8b, v4.8b
|
||||
dup v18.4s, wzr
|
||||
|
|
@ -707,7 +704,6 @@ L1LoopDz:
|
|||
sadalp v23.4s, v15.8h
|
||||
|
||||
ld1 {v10.16b, v11.16b}, [x2], #32
|
||||
add x1, x1, #48
|
||||
// int4->int8
|
||||
movi v8.16b, #15
|
||||
ushr v0.16b, v10.16b, #4
|
||||
|
|
|
|||
|
|
@ -133,7 +133,7 @@ ldr x24, [x6, #80] // extraScale
|
|||
mov x21, #16 // sizeof(float) * pack
|
||||
ldr x23, [x6, #56] // fp32minmax
|
||||
Start:
|
||||
mov x22, #48 // src_steps
|
||||
lsl x22, x7, #2 // eDest * SRC_UNIT
|
||||
|
||||
TILE_12:
|
||||
cmp x7, #12
|
||||
|
|
@ -823,8 +823,8 @@ L8LoopDz_TILE_1:
|
|||
|
||||
movi v8.16b, #0
|
||||
movi v9.16b, #0
|
||||
cmp x13, #4
|
||||
blt L8LoopSz_TILE_1_lu1
|
||||
//cmp x13, #4
|
||||
b L8LoopSz_TILE_1_lu1
|
||||
//lsl x22, x22, #2
|
||||
|
||||
L8LoopSz_TILE_1_lu4:
|
||||
|
|
|
|||
|
|
@ -123,7 +123,7 @@ ldr x14, [x6, #56] // float32 maxmin ptr
|
|||
ldr x23, [x6, #80] // extra scale
|
||||
|
||||
Start:
|
||||
mov x22, #80 // GEMM_INT8_DST_XUNIT * GEMM_INT8_SRC_UNIT = 10 * 8 = 80
|
||||
lsl x22, x7, #3// eDest * GEMM_INT8_SRC_UNIT
|
||||
|
||||
TILE_10:
|
||||
cmp x7, #10
|
||||
|
|
|
|||
|
|
@ -45,6 +45,10 @@ bne LoopSz_8
|
|||
|
||||
Tile8End:
|
||||
sub x4, x4, #8
|
||||
fcmle v28.4s, v1.4s, #0
|
||||
fcmle v29.4s, v2.4s, #0
|
||||
bit v1.16b, v31.16b, v28.16b
|
||||
bit v2.16b, v31.16b, v29.16b
|
||||
add x0, x0, #32
|
||||
fdiv v5.4s, v31.4s, v1.4s
|
||||
fdiv v6.4s, v31.4s, v2.4s
|
||||
|
|
@ -80,6 +84,8 @@ sub x4, x4, #4
|
|||
add x0, x0, #16
|
||||
// quant_scale = 127 / absmax
|
||||
// dequant_scale = absmax / 127
|
||||
fcmle v28.4s, v1.4s, #0
|
||||
bit v1.16b, v31.16b, v28.16b
|
||||
fdiv v2.4s, v31.4s, v1.4s
|
||||
fdiv v3.4s, v1.4s, v31.4s
|
||||
st1 {v2.4s}, [x1], #16
|
||||
|
|
@ -113,6 +119,8 @@ sub x4, x4, #1
|
|||
add x0, x0, #4
|
||||
// quant_scale = 127 / absmax
|
||||
// dequant_scale = absmax / 127
|
||||
fcmle v28.4s, v1.4s, #0
|
||||
bit v1.16b, v31.16b, v28.16b
|
||||
fdiv s2, s31, s1
|
||||
fdiv s3, s1, s31
|
||||
st1 {v2.s}[0], [x1], #4
|
||||
|
|
|
|||
|
|
@ -215,10 +215,15 @@ void MNNQuantScaleFP32(float* absmax, float* quant_scale, float* dequant_scale,
|
|||
for (int t = 0; t < thread; ++t) {
|
||||
absVal = std::max(absVal, absmaxPtr[t * batch]);
|
||||
}
|
||||
if (absVal < 1e-7) {
|
||||
quant_scale[i] = 1.f;
|
||||
dequant_scale[i] = 1.f;
|
||||
} else {
|
||||
quant_scale[i] = 127.0f / absVal;
|
||||
dequant_scale[i] = absVal / 127.0f;
|
||||
}
|
||||
}
|
||||
}
|
||||
void MNNQuantSumFP32(float* sum, const float* dequant_scale, size_t thread, size_t batch) {
|
||||
for (int i = 0; i < batch; ++i) {
|
||||
auto sumPtr = reinterpret_cast<int*>(sum) + i;
|
||||
|
|
@ -287,7 +292,7 @@ static void MNNSumByAxisLForMatmul_A(float* dest, int8_t* source, const float* s
|
|||
|
||||
for (int k = 0; k < blockNum; ++k) {
|
||||
// const auto src_x = srcInt8 + w * LP;
|
||||
const auto src_x = srcInt8 + k * (EP * LP * blockSizeQuad);
|
||||
const auto src_x = srcInt8 + k * (step * LP * blockSizeQuad);
|
||||
for (int w = 0; w < step; ++w) {
|
||||
float dequantScale = scale[0];
|
||||
if (oneScale == 0) {
|
||||
|
|
@ -296,7 +301,7 @@ static void MNNSumByAxisLForMatmul_A(float* dest, int8_t* source, const float* s
|
|||
int sumint32 = 0;
|
||||
const auto src_y = src_x + w * LP;
|
||||
for (int j = 0; j < blockSizeQuad; ++j) {
|
||||
const auto src_z = src_y + j * (EP * LP);
|
||||
const auto src_z = src_y + j * (step * LP);
|
||||
for (int i = 0; i < LP; ++i) {
|
||||
sumint32 += src_z[i];
|
||||
}
|
||||
|
|
@ -2762,7 +2767,7 @@ void MNNComputeMatMulForE_1(const float* A, const float* B, float* C, const floa
|
|||
Vec4 sumValue = Vec4(0.0f);
|
||||
auto by = B + y * l;
|
||||
for (int x=0; x<lC4; ++x) {
|
||||
sumValue = sumValue + Vec4::load(A + x * 4) * Vec4::load(by + x * 4);
|
||||
sumValue = Vec4::fma(sumValue, Vec4::load(A + x * 4), Vec4::load(by + x * 4));
|
||||
}
|
||||
float sumRemain = 0.0f;
|
||||
for (int x=lR; x<l; ++x) {
|
||||
|
|
@ -2791,10 +2796,10 @@ void MNNComputeMatMulForE_1(const float* A, const float* B, float* C, const floa
|
|||
auto srcY = A + y * l;
|
||||
for (int x=0; x<l; ++x) {
|
||||
auto a = Vec4(A[x]);
|
||||
sumValue0 = sumValue0 + a * Vec4::load(bs + h * x);
|
||||
sumValue1 = sumValue1 + a * Vec4::load(bs + h * x + 4);
|
||||
sumValue2 = sumValue2 + a * Vec4::load(bs + h * x + 8);
|
||||
sumValue3 = sumValue3 + a * Vec4::load(bs + h * x + 12);
|
||||
sumValue0 = Vec4::fma(sumValue0, a, Vec4::load(bs + h * x));
|
||||
sumValue1 = Vec4::fma(sumValue1, a, Vec4::load(bs + h * x + 4));
|
||||
sumValue2 = Vec4::fma(sumValue2, a, Vec4::load(bs + h * x + 8));
|
||||
sumValue3 = Vec4::fma(sumValue3, a, Vec4::load(bs + h * x + 12));
|
||||
}
|
||||
Vec4::save(C + 16 * y, sumValue0);
|
||||
Vec4::save(C + 16 * y + 4, sumValue1);
|
||||
|
|
|
|||
|
|
@ -113,9 +113,6 @@ static bool _reorderWeightInside(Backend* bn, const Convolution2DCommon* common,
|
|||
int oc = common->outputCount(), ic = common->inputCount(), kernelCount = common->kernelX() * common->kernelY();
|
||||
std::vector<int> shape;
|
||||
int pack = gcore->pack;
|
||||
if (gcore->bytes == 2 && gcore->pack == 8) {
|
||||
pack = 4;
|
||||
}
|
||||
if (SRC_UNIT > pack) {
|
||||
MNN_ASSERT(SRC_UNIT % pack == 0);
|
||||
shape = {UP_DIV(oc, UNIT), UP_DIV(UP_DIV(ic, pack) * kernelCount, SRC_UNIT / pack), UNIT, SRC_UNIT};
|
||||
|
|
@ -178,8 +175,10 @@ static void GetResourceInt8(std::shared_ptr<CPUConvolution::ResourceInt8> resour
|
|||
}
|
||||
auto alphaPtr = resource->mOriginScale->host<float>();
|
||||
auto biasPtr = reinterpret_cast<float*>(reinterpret_cast<uint8_t*>(alphaPtr) + scaleSize * bytes);
|
||||
::memset(alphaPtr, 1, scaleSize * bytes);
|
||||
if (outputCount % core->pack != 0) {
|
||||
::memset(alphaPtr, 0, scaleSize * bytes);
|
||||
::memset(biasPtr, 0, scaleSize * bytes);
|
||||
}
|
||||
auto quanInfoPtr = quantCommon->alpha.get();
|
||||
int h = quantCommon->alpha.size();
|
||||
if (quantCommon->asymmetric) {
|
||||
|
|
@ -444,19 +443,11 @@ static void _computeAlphaScale(Backend* backend, const Convolution2D* conv2d, st
|
|||
auto wZero = resourceInt8->mWeightQuantZero->host<int32_t>(); // has packed to outputUp4
|
||||
auto wScale = resourceInt8->mOriginScale->host<float>();
|
||||
int h = ocUp4;
|
||||
if (core->bytes == 2) {
|
||||
std::unique_ptr<int16_t[]> tmp(new int16_t[h]);
|
||||
core->MNNFp32ToLowp(wScale, tmp.get(), h);
|
||||
for (int i=0; i< h; ++i) {
|
||||
reinterpret_cast<int16_t*>(alphaPtr)[i] = tmp[i];
|
||||
reinterpret_cast<int16_t*>(biasPtr)[i] = (-1.f) * wZero[i] * tmp[i];
|
||||
}
|
||||
} else {
|
||||
MNN_ASSERT(4 == core->bytes);
|
||||
for (int i=0; i< h; ++i) {
|
||||
alphaPtr[i] = wScale[i];
|
||||
biasPtr[i] = (-1.f) * wZero[i] * wScale[i];
|
||||
}
|
||||
}
|
||||
resourceInt8->mOriginScale = scaleBias;
|
||||
|
||||
// Compute float weightKernelSum
|
||||
|
|
@ -582,11 +573,8 @@ ErrorCode DenseConvInt8TiledExecutor::onResize(const std::vector<Tensor*>& input
|
|||
}
|
||||
// A axisSum kernel
|
||||
mSumByAxisLFunc = gcore->MNNSumByAxisLForMatmul_A;
|
||||
if (gcore->bytes == 2 && gcore->pack == 8) { // use fp16
|
||||
ConvolutionTiledExecutor::setIm2ColParameter(mIm2ColParamter, mCommon, inputs[0], outputs[0], mPadX, mPadY, gcore, core, 4);
|
||||
} else {
|
||||
ConvolutionTiledExecutor::setIm2ColParameter(mIm2ColParamter, mCommon, inputs[0], outputs[0], mPadX, mPadY, gcore, core);
|
||||
}
|
||||
|
||||
int ocUp4 = ROUND_UP(outputs[0]->channel(), gcore->pack);
|
||||
int alphaSize = mResourceInt8->mOriginScale->size() / (sizeof(float) * 2);
|
||||
mBlockNum = alphaSize / ocUp4;
|
||||
|
|
@ -864,6 +852,15 @@ ErrorCode DenseConvInt8TiledExecutor::onExecute(const std::vector<Tensor*>& inpu
|
|||
}
|
||||
|
||||
/* Dynamic quant */
|
||||
if (mCommon->padX() > 0 || mCommon->padY() > 0) { // Ensure "0.0f" included in range.
|
||||
if (minVal > 0.f) {
|
||||
minVal = 0.f;
|
||||
} else if (maxVal < 0.f){
|
||||
maxVal = 0.f;
|
||||
} else {
|
||||
//
|
||||
}
|
||||
}
|
||||
float range = maxVal - minVal;
|
||||
if (fabs(range) < 1e-7) {
|
||||
zeropoint = maxVal;
|
||||
|
|
@ -875,12 +872,22 @@ ErrorCode DenseConvInt8TiledExecutor::onExecute(const std::vector<Tensor*>& inpu
|
|||
zeropoint = roundf(-minVal * 255.f / range) - 128.0f;
|
||||
}
|
||||
auto sizeDiv = UP_DIV(inputsize, PackUnit);
|
||||
int inputPlane = input->batch() * mIm2ColParamter.iw * mIm2ColParamter.ih;
|
||||
if (gcore->bytes == 2 && gcore->pack == 8 && inputPlane > 1) { // C8->C4
|
||||
mQuantAndReorderFunc(floatptr, int8ptr, inputPlane, &quantscale, -128, 127, &zeropoint, UP_DIV(input->channel(), PackUnit), 4 * inputPlane);
|
||||
|
||||
threadNeed = mThreadNums;
|
||||
inputSizeCount = UP_DIV(sizeDiv, mThreadNums);
|
||||
if (inputSizeCount < 9) {
|
||||
threadNeed = 1;
|
||||
inputSizeCount = sizeDiv;
|
||||
} else {
|
||||
mQuantFunc(floatptr, int8ptr, sizeDiv, &quantscale, -128, 127, &zeropoint, 0);
|
||||
threadNeed = ALIMIN(UP_DIV(sizeDiv, inputSizeCount), mThreadNums);
|
||||
inputSizeCount = UP_DIV(sizeDiv, threadNeed);
|
||||
}
|
||||
MNN_CONCURRENCY_BEGIN(tId, threadNeed) {
|
||||
auto perThreadWorkCount = ALIMIN(inputSizeCount, sizeDiv - tId * inputSizeCount);
|
||||
auto inptr_ = (float*)(((int8_t*)floatptr) + tId * inputSizeCount * PackUnit * gcore->bytes);
|
||||
mQuantFunc(inptr_ , int8ptr + tId * inputSizeCount * PackUnit, perThreadWorkCount, &quantscale, -128, 127, &zeropoint, 0);
|
||||
}
|
||||
MNN_CONCURRENCY_END();
|
||||
|
||||
/* bias float */
|
||||
#ifdef MNN_USE_SSE
|
||||
|
|
@ -1078,7 +1085,7 @@ ErrorCode DenseConvInt8TiledExecutor::onExecute(const std::vector<Tensor*>& inpu
|
|||
quanParam.weightQuanBias = weightDequanBiasTid + k * ocUp4;
|
||||
quanParam.scale = (float*)(scaleFloatTid + k * ocUp4);
|
||||
|
||||
mGemmKernel(outputInTilePtr, colAddrTemp + k * blockL * src_step_Y, weightPtrTid + k * blockL * weight_step_Y * UP_DIV(output->channel(), UNIT__), blockL, dstZStep * dstBytes, ocDivThread, &quanParam, step);
|
||||
mGemmKernel(outputInTilePtr, colAddrTemp + k * blockL * step * SRC_UNIT, weightPtrTid + k * blockL * weight_step_Y * UP_DIV(output->channel(), UNIT__), blockL, dstZStep * dstBytes, ocDivThread, &quanParam, step);
|
||||
}
|
||||
ptrX += (step * mBlockNum);
|
||||
realDstCount-=step;
|
||||
|
|
@ -1093,6 +1100,7 @@ ErrorCode DenseConvInt8TiledExecutor::onExecute(const std::vector<Tensor*>& inpu
|
|||
if (!mSplitByOc) {
|
||||
MNN_CONCURRENCY_BEGIN(tId, threads) {
|
||||
ThreadFunction((int)tId, mDivides[tId], mDivides[tId + 1], 1, 0);
|
||||
|
||||
}
|
||||
MNN_CONCURRENCY_END();
|
||||
} else {
|
||||
|
|
|
|||
|
|
@ -323,7 +323,7 @@ ErrorCode ConvInt8Winograd::onExecute(const std::vector<Tensor *> &inputs, const
|
|||
|
||||
std::vector<float> scale(pack, inputQuant[0]);
|
||||
int size = bn->getTensorSize(mInputFloat.get());
|
||||
core->MNNInt8ScaleToFloat(mInputFloat->host<float>(), inputs[0]->host<int8_t>(), scale.data(), size / pack, inputQuant[1]);
|
||||
core->MNNInt8ScaleToFloat(mInputFloat->host<float>(), inputs[0]->host<int8_t>(), &inputQuant[0], size / pack, &inputQuant[1], 0);
|
||||
std::vector<Tensor*> tmp_outputs;
|
||||
for (auto& unit : mUnits) {
|
||||
unit.input->buffer().host = TensorUtils::getDescribeOrigin(unit.input.get())->mem->chunk().ptr();
|
||||
|
|
@ -557,7 +557,7 @@ ErrorCode ConvInt8Winograd::WinoExecution::onExecute(const std::vector<Tensor *>
|
|||
quanParam.extraScale = nullptr;
|
||||
quanParam.bias = nullptr;
|
||||
quanParam.blockNum = 1;
|
||||
gemmFunc((int8_t*)_dstFloatPtr, _srcInt8Ptr, _weightInt8Ptr, mTempInputBuffer->length(2), xC * pack * sizeof(float), dc_4, &quanParam, xC);
|
||||
gemmFunc((int8_t*)_dstFloatPtr, _srcInt8Ptr, _weightInt8Ptr, mTempInputBuffer->length(2), xC * pack * sizeof(float), dc_4, &quanParam, DST_XUNIT);
|
||||
}
|
||||
#ifndef MNN_WINO_TRANFORM_TEST_CLOSE
|
||||
{
|
||||
|
|
|
|||
|
|
@ -56,13 +56,18 @@ static Execution* _createUnit(const Tensor* input, const Tensor* output, Backend
|
|||
return new DenseConvolutionTiledExecutor(common, backend, originWeight, originWeightSize, bias, biasSize, weightQuantInfo);
|
||||
}
|
||||
}
|
||||
#ifndef MNN_LOW_MEMORY
|
||||
if (cpuBackend->memoryMode() == BackendConfig::Memory_Low) {
|
||||
return new DenseConvolutionTiledExecutor(common, backend, originWeight, originWeightSize, bias, biasSize, weightQuantInfo);
|
||||
}
|
||||
#endif
|
||||
if (fastWay && cpuBackend->functions()->matmulBytes == 0) {
|
||||
return new Convolution1x1Strassen(common, backend, originWeight, originWeightSize, bias, biasSize, weightQuantInfo);
|
||||
}
|
||||
if (originWeightSize == 0) {
|
||||
return new DenseConvolutionTiledExecutor(common, backend, originWeight, originWeightSize, bias, biasSize, weightQuantInfo);
|
||||
}
|
||||
if (!ConvolutionWinogradBridge::canUseWinograd(common)) {
|
||||
if (cpuBackend->getRuntime()->hint().winogradMemoryUsed == 0 || (!ConvolutionWinogradBridge::canUseWinograd(common))) {
|
||||
return new DenseConvolutionTiledExecutor(common, backend, originWeight, originWeightSize, bias, biasSize, nullptr);
|
||||
}
|
||||
PerfConfig convPerfconfig = DenseConvolutionTiledExecutor::bestTileConvolutionConfig(common, input, output, cpuBackend->threadNumber(), backend);
|
||||
|
|
|
|||
|
|
@ -645,6 +645,11 @@ WinogradConfig ConvolutionPackFreeWinograd::updateBestWinogradUnit(const Convolu
|
|||
auto oc4 = UP_DIV(oc, pack);
|
||||
int ePackMax, hPack, lPack;
|
||||
core->MNNGetMatMulPackMode(&ePackMax, &lPack, &hPack);
|
||||
auto winogradMemoryLevel = static_cast<CPUBackend*>(b)->getRuntime()->hint().winogradMemoryUsed;
|
||||
int unitMaxLimit = CONVOLUTION_WINOGRAD_MAX_UNIT;
|
||||
if (winogradMemoryLevel != 3) {
|
||||
unitMaxLimit = CONVOLUTION_WINOGRAD_MIN_UNIT;
|
||||
}
|
||||
|
||||
WinogradConfig bestConfig(0, false, 0, 0, 0, std::numeric_limits<float>().max());
|
||||
auto kernelSize = common->kernelY();
|
||||
|
|
@ -659,7 +664,7 @@ WinogradConfig ConvolutionPackFreeWinograd::updateBestWinogradUnit(const Convolu
|
|||
for (int ePack = ePackUnit; ePack <= ePackUnit; ePack += ePackUnit) {
|
||||
int unit2 = UP_DIV(batch * ow * oh, ePack);
|
||||
int maxUnit = (int)::sqrtf((float)unit2);
|
||||
maxUnit = std::min(maxUnit, CONVOLUTION_WINOGRAD_MAX_UNIT);
|
||||
maxUnit = std::min(maxUnit, unitMaxLimit);
|
||||
maxUnit = std::max(maxUnit, CONVOLUTION_WINOGRAD_MIN_UNIT);
|
||||
std::set<int> supportSu{4, 6, 8};
|
||||
|
||||
|
|
|
|||
|
|
@ -200,11 +200,10 @@ ErrorCode GemmInt8Executor::onExecute(const std::vector<Tensor *> &inputs, const
|
|||
auto threadFunction = [&](int tId) {
|
||||
auto colAddr = im2colPtr + tId * mInputCol->stride(0);
|
||||
auto col_buffer_size = mInputCol->stride(0);
|
||||
int32_t info[6];
|
||||
int32_t info[5];
|
||||
info[1] = mIm2ColParamter.iw * mIm2ColParamter.ih * batch;
|
||||
info[2] = DST_XUNIT;
|
||||
info[3] = mIm2ColParamter.strideX;
|
||||
info[5] = mIm2ColParamter.kernelCountUnit;
|
||||
float paramsf[1];
|
||||
paramsf[0] = dequantScale;
|
||||
auto srcPtr = (int8_t const **)(mBlitInfo.ptr() + tId * mBlitInfoStride.first);
|
||||
|
|
|
|||
|
|
@ -154,6 +154,9 @@ ErrorCode IdstConvolutionInt8::onExecute(const std::vector<Tensor*>& inputs, con
|
|||
int PackUnit = static_cast<CPUBackend*>(backend())->functions()->pack;
|
||||
|
||||
auto gemmKernel = coreInt->Int8GemmKernel;
|
||||
if (SRC_UNIT > PackUnit) {
|
||||
memset(mTempBuffer.host<int8_t>(), 0, mTempBuffer.size());
|
||||
}
|
||||
|
||||
// AUTOTIME;
|
||||
auto input = inputs[0];
|
||||
|
|
@ -210,7 +213,7 @@ ErrorCode IdstConvolutionInt8::onExecute(const std::vector<Tensor*>& inputs, con
|
|||
auto srcPtr = (int8_t const **)(mBlitInfo.ptr() + tId * mBlitInfoStride.first);
|
||||
auto el = (int32_t *)(srcPtr + mBlitInfoStride.second);
|
||||
|
||||
int32_t info[4];
|
||||
int32_t info[5];
|
||||
info[1] = mIm2ColParamter.iw * mIm2ColParamter.ih;
|
||||
info[2] = DST_XUNIT;
|
||||
info[3] = mIm2ColParamter.strideX;
|
||||
|
|
@ -225,6 +228,7 @@ ErrorCode IdstConvolutionInt8::onExecute(const std::vector<Tensor*>& inputs, con
|
|||
::memset(colAddr, zeroPoint, col_buffer_size);
|
||||
}
|
||||
info[0] = number;
|
||||
info[4] = realDstCount;
|
||||
if (number > 0) {
|
||||
blitProc(colAddr, srcPtr, info, el);
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1440,7 +1440,7 @@ static void MNNGemmInt8AddBiasScale_16x4_Unit(int8_t* dst, const int8_t* src, co
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + weight_step_Y * sz;
|
||||
const auto src_z = src_x + sz * GEMM_INT8_DST_XUNIT * GEMM_INT8_SRC_UNIT;
|
||||
const auto src_z = src_x + sz * realCount * GEMM_INT8_SRC_UNIT;
|
||||
|
||||
for (int j = 0; j < GEMM_INT8_UNIT; ++j) {
|
||||
const auto weight_j = weight_sz + j * GEMM_INT8_SRC_UNIT;
|
||||
|
|
@ -1506,7 +1506,7 @@ static void MNNGemmInt8AddBiasScale_16x4_w4_Unit(int8_t* dst, const int8_t* src,
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = (uint8_t*)weight_dz + weight_step_Y * sz;
|
||||
const auto src_z = src_x + sz * GEMM_INT8_DST_XUNIT * GEMM_INT8_SRC_UNIT;
|
||||
const auto src_z = src_x + sz * realCount * GEMM_INT8_SRC_UNIT;
|
||||
|
||||
int w8[64]; // 64=GEMM_INT8_UNIT * GEMM_INT8_SRC_UNIT
|
||||
for (int k = 0; k < 32; ++k) {
|
||||
|
|
@ -1671,12 +1671,20 @@ void MNNFloat2Int8(const float* src, int8_t* dst, size_t sizeQuad, const float*
|
|||
}
|
||||
}
|
||||
|
||||
void MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t size, ssize_t zeroPoint) {
|
||||
void MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t size, const float* zeroPoint, ssize_t quantParamVec) {
|
||||
float scale_[4] = {scale[0], scale[0], scale[0], scale[0]};
|
||||
float zero_[4] = {zeroPoint[0], zeroPoint[0], zeroPoint[0], zeroPoint[0]};
|
||||
if (quantParamVec & 1) {
|
||||
::memcpy(scale_, scale, 4 * sizeof(float));
|
||||
}
|
||||
if (quantParamVec >> 1) {
|
||||
::memcpy(zero_, zeroPoint, 4 * sizeof(float));
|
||||
}
|
||||
for (int i = 0; i < size; ++i) {
|
||||
const auto srcStart = src + i * 4;
|
||||
auto dstStart = dst + i * 4;
|
||||
for (int j = 0; j < 4; ++j) {
|
||||
dstStart[j] = static_cast<float>(srcStart[j] - zeroPoint) * scale[j];
|
||||
dstStart[j] = static_cast<float>(srcStart[j] - zero_[j]) * scale_[j];
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -2033,22 +2041,39 @@ static void _ArmBasicMNNPackC4ForMatMul_A(int8_t* destOrigin, int8_t const** sou
|
|||
int eDest = EP;
|
||||
int offset = info[3];
|
||||
const int LUNIT = LP / sizeof(float);
|
||||
int realDstCount = info[4];
|
||||
for (int n=0; n<number; ++n) {
|
||||
int e = el[4 * n + 0];
|
||||
int e = el[4 * n + 0]; // to fill
|
||||
int l = el[4 * n + 1];
|
||||
int eOffset = el[4 * n + 2];
|
||||
int eOffset = el[4 * n + 2]; // have filled
|
||||
int lOffset = el[4 * n + 3];
|
||||
int lC = lOffset / LP;
|
||||
int lR = lOffset % LP;
|
||||
int eC = eOffset / eDest;
|
||||
int eR = eOffset % eDest;
|
||||
int eS = eDest - eR;
|
||||
// printf("e=%d, eC=%d, lC=%d, eR=%d, lR=%d\n", e, eC, lC, eR, lR);
|
||||
bool lastBag = false;
|
||||
int eOutsideStride4LastBag = eOutsideStride;
|
||||
if (realDstCount % EP > 0) {
|
||||
int jobsE = realDstCount - eOffset - e;
|
||||
if (jobsE == 0 || (jobsE < (realDstCount % EP))) {
|
||||
lastBag = true;
|
||||
}
|
||||
}
|
||||
auto dest = (int32_t*)(destOrigin + lC * eDest * LP + lR + eC * info[2] + eR * LP);
|
||||
auto source = (int32_t*)sourceGroup[n];
|
||||
int lRemain = l / 4;
|
||||
int lR4 = lR / LUNIT;
|
||||
int lR4 = lR / 4;
|
||||
int lS = LUNIT - lR4;
|
||||
int eS = eDest - eR;
|
||||
|
||||
if (lastBag && e + eR < EP) {
|
||||
int elast = ALIMAX(eR + e, realDstCount % EP);
|
||||
dest = (int32_t*)(destOrigin + lC * elast * LP + lR + eC * info[2] + eR * LP);
|
||||
}
|
||||
// Step for start
|
||||
int offsetLC = lC * LUNIT + lR / 4;
|
||||
|
||||
if (lR4 > 0) {
|
||||
int step = ALIMIN(lS, lRemain);
|
||||
for (int x=0; x<step; ++x) {
|
||||
|
|
@ -2061,7 +2086,13 @@ static void _ArmBasicMNNPackC4ForMatMul_A(int8_t* destOrigin, int8_t const** sou
|
|||
d[yi * LUNIT] = s[yi * offset];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag ||eRemain >= EP) {
|
||||
d += (eOutsideStride - eR * LUNIT);
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - ((offsetLC / LUNIT) * EP * LUNIT);
|
||||
d += (eOutsideStride4LastBag - eR * LUNIT + (offsetLC / LUNIT) * eFill * LUNIT);
|
||||
}
|
||||
s += eS * offset;
|
||||
}
|
||||
while (eRemain > 0) {
|
||||
|
|
@ -2070,14 +2101,29 @@ static void _ArmBasicMNNPackC4ForMatMul_A(int8_t* destOrigin, int8_t const** sou
|
|||
d[yi * LUNIT] = s[yi * offset];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag || eRemain >= EP) {
|
||||
d+= eOutsideStride;
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - ((offsetLC / LUNIT) * EP * LUNIT);
|
||||
d+= (eOutsideStride4LastBag + (offsetLC / LUNIT) * eFill * LUNIT);
|
||||
}
|
||||
s+= eStep * offset;
|
||||
}
|
||||
offsetLC++;
|
||||
}
|
||||
lRemain -= step;
|
||||
dest += step;
|
||||
if (lastBag && e + eR < EP) {
|
||||
int eFill = ALIMAX(realDstCount % EP, e + eR);
|
||||
int nextLP = (eFill * LP - lR) / sizeof(int32_t);
|
||||
dest += nextLP;
|
||||
} else {
|
||||
int nextLP = (eDest * LP - lR) / sizeof(int32_t);
|
||||
dest += nextLP;
|
||||
}
|
||||
source += eReal * step;
|
||||
}
|
||||
|
||||
while (lRemain > 0) {
|
||||
int step = ALIMIN(lRemain, LUNIT);
|
||||
for (int x=0; x<step; ++x) {
|
||||
|
|
@ -2090,7 +2136,13 @@ static void _ArmBasicMNNPackC4ForMatMul_A(int8_t* destOrigin, int8_t const** sou
|
|||
d[yi * LUNIT] = s[yi * offset];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag ||eRemain >= EP) {
|
||||
d += (eOutsideStride - eR * LUNIT);
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - ((offsetLC / LUNIT) * EP * LUNIT);
|
||||
d += (eOutsideStride4LastBag - eR * LUNIT + (offsetLC / LUNIT) * eFill * LUNIT);
|
||||
}
|
||||
s += eS * offset;
|
||||
}
|
||||
while (eRemain > 0) {
|
||||
|
|
@ -2099,12 +2151,25 @@ static void _ArmBasicMNNPackC4ForMatMul_A(int8_t* destOrigin, int8_t const** sou
|
|||
d[yi * LUNIT] = s[yi * offset];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag || eRemain >= EP) {
|
||||
d+= eOutsideStride;
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - ((offsetLC / LUNIT) * EP * LUNIT);
|
||||
d+= (eOutsideStride4LastBag + (offsetLC / LUNIT) * eFill * LUNIT);
|
||||
}
|
||||
s+= eStep * offset;
|
||||
}
|
||||
offsetLC++;
|
||||
}
|
||||
|
||||
lRemain -= step;
|
||||
if (lastBag && e + eR < EP) {
|
||||
int efill = ALIMAX(e + eR, realDstCount % EP);
|
||||
dest += efill * LUNIT;
|
||||
} else {
|
||||
dest += eDest * LUNIT;
|
||||
}
|
||||
source += eReal * step;
|
||||
}
|
||||
}
|
||||
|
|
@ -2136,17 +2201,33 @@ static void _ArmBasicMNNPackC4ForMatMul_A_L4(int8_t* destOrigin, int8_t const**
|
|||
int offset = info[3];
|
||||
const int LP = 4;
|
||||
int eOutsideStride = info[2] / sizeof(float);
|
||||
int kernelCountUnit = eOutsideStride;
|
||||
int realDstCount = info[4];
|
||||
for (int n=0; n<number; ++n) {
|
||||
int e = el[4 * n + 0];
|
||||
int l = el[4 * n + 1];
|
||||
int eOffset = el[4 * n + 2];
|
||||
int lOffset = el[4 * n + 3];
|
||||
int eC = eOffset / eDest;
|
||||
int eR = eOffset % eDest;
|
||||
auto dest = (int32_t*)(destOrigin + lOffset * eDest + eC * info[2] + eR * LP);
|
||||
int eC = eOffset / EP;
|
||||
int eR = eOffset % EP;
|
||||
int eS = eDest - eR;
|
||||
bool lastBag = false;
|
||||
int eOutsideStride4LastBag = eOutsideStride;
|
||||
int eres = realDstCount - eOffset;
|
||||
if (realDstCount % EP > 0) {
|
||||
int jobsE = realDstCount - eOffset - e;
|
||||
if (jobsE == 0 || (jobsE < (realDstCount % EP))) {
|
||||
lastBag = true;
|
||||
}
|
||||
}
|
||||
auto dest = (int32_t*)(destOrigin + lOffset * eDest + eC * info[2] + eR * LP);
|
||||
auto source = (int32_t*)sourceGroup[n];
|
||||
int lRemain = l / sizeof(float);
|
||||
if (lastBag && e + eR < EP) {
|
||||
int elast = ALIMIN(ALIMAX(eR + e, realDstCount % EP), EP);
|
||||
dest = (int32_t*)(destOrigin + lOffset * elast + eC * info[2] + eR * LP);
|
||||
}
|
||||
int offsetLC = lOffset / 4;
|
||||
for (int x=0; x<lRemain; ++x) {
|
||||
int eRemain = e;
|
||||
auto d = dest;
|
||||
|
|
@ -2156,14 +2237,26 @@ static void _ArmBasicMNNPackC4ForMatMul_A_L4(int8_t* destOrigin, int8_t const**
|
|||
int eStep = ALIMIN(eRemain, eS);
|
||||
::memcpy(d, s, eStep * sizeof(int32_t));
|
||||
eRemain-=eStep;
|
||||
if (!lastBag ||eRemain >= EP) {
|
||||
d += (eOutsideStride - eR);
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * 4 * offsetLC / sizeof(float));
|
||||
d += (eOutsideStride4LastBag - eR + offsetLC * eFill);
|
||||
}
|
||||
s += eS * offset;
|
||||
}
|
||||
while (eRemain > 0) {
|
||||
int eStep = ALIMIN(eDest, eRemain);
|
||||
::memcpy(d, s, eStep * sizeof(int32_t));
|
||||
eRemain-=eStep;
|
||||
if (!lastBag || eRemain >= EP) {
|
||||
d+= eOutsideStride;
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * 4 * offsetLC / sizeof(float));
|
||||
d+= (eOutsideStride4LastBag + offsetLC * eFill);
|
||||
}
|
||||
s+= eStep * offset;
|
||||
}
|
||||
} else {
|
||||
|
|
@ -2173,7 +2266,13 @@ static void _ArmBasicMNNPackC4ForMatMul_A_L4(int8_t* destOrigin, int8_t const**
|
|||
d[yi] = s[yi * offset];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag ||eRemain >= EP) {
|
||||
d += (eOutsideStride - eR);
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * 4 * offsetLC / sizeof(float));
|
||||
d += (eOutsideStride4LastBag - eR + offsetLC * eFill);
|
||||
}
|
||||
s += eS * offset;
|
||||
}
|
||||
while (eRemain > 0) {
|
||||
|
|
@ -2182,12 +2281,24 @@ static void _ArmBasicMNNPackC4ForMatMul_A_L4(int8_t* destOrigin, int8_t const**
|
|||
d[yi] = s[yi * offset];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag || eRemain >= EP) {
|
||||
d+= eOutsideStride;
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * 4 * offsetLC / sizeof(float));
|
||||
d+= (eOutsideStride4LastBag + offsetLC * eFill);
|
||||
}
|
||||
s+= eStep * offset;
|
||||
}
|
||||
}
|
||||
dest += eDest;
|
||||
source += eReal;
|
||||
if (lastBag && e + eR < EP ) { // eR=0;eR>0
|
||||
int efill = ALIMAX(e + eR, realDstCount % EP);
|
||||
dest += efill;
|
||||
} else {
|
||||
dest += eDest;
|
||||
}
|
||||
offsetLC++;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
@ -2237,7 +2348,7 @@ void MNNCoreInt8FunctionInit() {
|
|||
gCoreFunc->Int8GemmKernelFast = MNNGemmInt8AddBiasScale_ARMV82_Unit;
|
||||
gCoreFunc->MNNGetGemmUnit = MNNGetGemmUnitSdot;
|
||||
// Im2Col
|
||||
gCoreFunc->MNNPackC4Int8ForMatMul_A = _ArmBasicMNNPackC4ForMatMul_A_L4<12, 4>;
|
||||
gCoreFunc->MNNPackC4Int8ForMatMul_A = _ArmBasicMNNPackC4ForMatMul_A_L4<12, 8>;
|
||||
// ConvDepthwise
|
||||
gCoreFunc->ConvDepthwise3x3LineInt8_ARM82 = MNNLineDepthWiseInt8AddBiasScale_ARMV82_Unit3X3;
|
||||
core->MNNSumByAxisLForMatmul_A = MNNSumByAxisLForMatmul_A_ARM82;
|
||||
|
|
|
|||
|
|
@ -62,7 +62,7 @@ struct QuanPrePostParameters{
|
|||
};
|
||||
void MNNFloat2Int8(const float* src, int8_t* dst, size_t sizeQuad, const float* scalep, ssize_t minValue,
|
||||
ssize_t maxValue, const float* zeroPoint, ssize_t quanParamVec);
|
||||
void MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t size, ssize_t zeroPoint);
|
||||
void MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t size, const float* zeroPoint, ssize_t quanParamVec);
|
||||
void MNNInt8FunctionInit();
|
||||
void MNNPackedSparseQuantMatMulEpx1(int8_t* C, const int8_t* A, const int8_t* B, const size_t* sparseQuantParam, const QuanPostTreatParameters* post, unsigned int* NNZMap, int* dataOffsetMap);
|
||||
void MNNPackedSparseQuantMatMulEpx4(int8_t* C, const int8_t* A, const int8_t* B, const size_t* sparseQuantParam, const QuanPostTreatParameters* post, unsigned int* NNZMap, int* dataOffsetMap);
|
||||
|
|
@ -104,7 +104,7 @@ struct CoreInt8Functions {
|
|||
void(*DynamicQuanInput_ARM82)(const float* src, int8_t* dst, size_t sizeQuad, const float* scalep, ssize_t minValue, ssize_t maxValue, const float* zeroPoint, ssize_t quanParamVec) = nullptr;
|
||||
void (*DynamicQuanInputAndReorder_ARM82)(const float* src, int8_t* dst, size_t planeSize, const float* scale, ssize_t aMin, ssize_t aMax, const float* zeroPoint, size_t ocQuad, size_t offset) = nullptr;
|
||||
void(*MNNFloat2Int8)(const float* src, int8_t* dst, size_t sizeQuad, const float* scalep, ssize_t minValue, ssize_t maxValue, const float* zeroPoint, ssize_t quanParamVec);
|
||||
void(*MNNInt8ScaleToFloat)(float* dst, const int8_t* src, const float* scale, size_t size, ssize_t zeroPoint);
|
||||
void(*MNNInt8ScaleToFloat)(float* dst, const int8_t* src, const float* scale, size_t size, const float* zeroPoint, ssize_t quanParamVec);
|
||||
|
||||
void(*MNNScaleAndAddBias)(float* dst, const float* src, const float* bias, const float* alpha, size_t planeNumber, size_t biasNumber);
|
||||
|
||||
|
|
|
|||
|
|
@ -7,12 +7,7 @@
|
|||
//
|
||||
|
||||
#include <algorithm>
|
||||
#if defined(_MSC_VER)
|
||||
#include <intrin.h>
|
||||
#else
|
||||
#include <x86intrin.h>
|
||||
#endif
|
||||
|
||||
#include "core/SimdHeader.h"
|
||||
#include "AVX2Functions.hpp"
|
||||
#include "AVX2Backend.hpp"
|
||||
#include "core/BufferAllocator.hpp"
|
||||
|
|
|
|||
|
|
@ -22,6 +22,12 @@ static void _MNNGetMatMulPackMode(int* eP, int *lP, int* hP) {
|
|||
*hP = ghP;
|
||||
}
|
||||
|
||||
#ifndef MNN_USE_AVX
|
||||
bool AVX2Functions::init(int cpuFlags) {
|
||||
return false;
|
||||
}
|
||||
#else
|
||||
|
||||
bool AVX2Functions::init(int cpuFlags) {
|
||||
gAVX2CoreFunctions = new CoreFunctions;
|
||||
auto coreFunction = gAVX2CoreFunctions;
|
||||
|
|
@ -99,11 +105,12 @@ bool AVX2Functions::init(int cpuFlags) {
|
|||
#endif
|
||||
return true;
|
||||
}
|
||||
#endif
|
||||
|
||||
CoreFunctions* AVX2Functions::get() {
|
||||
return gAVX2CoreFunctions;
|
||||
}
|
||||
CoreInt8Functions* AVX2Functions::getInt8() {
|
||||
return gAVX2CoreInt8Functions;
|
||||
}
|
||||
|
||||
};
|
||||
|
|
|
|||
|
|
@ -5,6 +5,12 @@ IF(MSVC AND (DEFINED ENV{MNN_ASSEMBLER}) AND "${CMAKE_SIZEOF_VOID_P}" STREQUAL "
|
|||
set(WIN_USE_ASM ON)
|
||||
ENDIF()
|
||||
message(STATUS "WIN_USE_ASM: ${WIN_USE_ASM}")
|
||||
if (EMSCRIPTEN)
|
||||
set(MNN_AVX2 OFF)
|
||||
endif()
|
||||
if (NOT MNN_AVX2)
|
||||
set(MNN_AVX512 OFF)
|
||||
endif()
|
||||
function (process_asm TARGET_NAME FILE_SRCS)
|
||||
if(NOT MSVC)
|
||||
return()
|
||||
|
|
@ -32,7 +38,7 @@ function (process_asm TARGET_NAME FILE_SRCS)
|
|||
set(EXTRA_OBJS ${EXTRA_OBJS} PARENT_SCOPE)
|
||||
endfunction()
|
||||
|
||||
if(CMAKE_SYSTEM_PROCESSOR MATCHES "(x86_64)|(X86_64)|(x64)|(X64)|(amd64)|(AMD64)|(i686)")
|
||||
if(CMAKE_SYSTEM_PROCESSOR MATCHES "(x86_64)|(X86_64)|(x64)|(X64)|(amd64)|(AMD64)|(i686)|(x86)")
|
||||
message(STATUS "${CMAKE_SYSTEM_PROCESSOR}: Open SSE")
|
||||
target_compile_options(MNNCPU PRIVATE -DMNN_USE_SSE)
|
||||
option(MNN_AVX512_VNNI "Enable AVX512 VNNI" ON)
|
||||
|
|
@ -55,6 +61,7 @@ if(CMAKE_SYSTEM_PROCESSOR MATCHES "(x86_64)|(X86_64)|(x64)|(X64)|(amd64)|(AMD64)
|
|||
if (MNN_AVX512_VNNI)
|
||||
target_compile_options(MNNAVX512 PRIVATE -DMNN_AVX512_VNNI)
|
||||
add_library(MNNAVX512_VNNI OBJECT ${MNNAVX512_VNNI_SRC})
|
||||
target_compile_options(MNNAVX512_VNNI PRIVATE -DMNN_USE_SSE)
|
||||
target_compile_options(MNNAVX512_VNNI PRIVATE -DMNN_AVX512_VNNI)
|
||||
if (MSVC)
|
||||
target_compile_options(MNNAVX512 PRIVATE /arch:AVX512)
|
||||
|
|
@ -68,27 +75,29 @@ if(CMAKE_SYSTEM_PROCESSOR MATCHES "(x86_64)|(X86_64)|(x64)|(X64)|(amd64)|(AMD64)
|
|||
process_asm(MNNAVXFMA MNN_AVXFMA_SRC)
|
||||
process_asm(MNNSSE MNN_SSE_SRC)
|
||||
add_library(MNNX8664 OBJECT ${MNN_X8664_SRC})
|
||||
add_library(MNNAVX OBJECT ${MNN_AVX_SRC})
|
||||
add_library(MNNAVXFMA OBJECT ${MNN_AVXFMA_SRC})
|
||||
add_library(MNNSSE OBJECT ${MNN_SSE_SRC})
|
||||
target_compile_options(MNNX8664 PRIVATE -DMNN_USE_SSE)
|
||||
target_compile_options(MNNSSE PRIVATE -DMNN_USE_SSE)
|
||||
if (MNN_AVX2)
|
||||
target_compile_options(MNNX8664 PRIVATE -DMNN_USE_AVX)
|
||||
add_library(MNNAVX OBJECT ${MNN_AVX_SRC})
|
||||
add_library(MNNAVXFMA OBJECT ${MNN_AVXFMA_SRC})
|
||||
target_compile_options(MNNAVX PRIVATE -DMNN_USE_SSE)
|
||||
target_compile_options(MNNAVXFMA PRIVATE -DMNN_USE_SSE)
|
||||
endif()
|
||||
if(MSVC)
|
||||
if (MNN_AVX2)
|
||||
target_compile_options(MNNAVX PRIVATE /arch:AVX)
|
||||
target_compile_options(MNNAVXFMA PRIVATE /arch:AVX2)
|
||||
endif()
|
||||
else()
|
||||
target_compile_options(MNNSSE PRIVATE -msse4.1)
|
||||
if (MNN_AVX2)
|
||||
target_compile_options(MNNAVX PRIVATE -mavx2 -DMNN_X86_USE_ASM)
|
||||
target_compile_options(MNNAVXFMA PRIVATE -mavx2 -mfma -DMNN_X86_USE_ASM)
|
||||
endif()
|
||||
if (MNN_SUPPORT_BF16)
|
||||
target_compile_options(MNNAVXFMA PRIVATE -DMNN_SUPPORT_BF16)
|
||||
if (MNN_SSE_USE_FP16_INSTEAD)
|
||||
target_compile_options(MNNAVXFMA PRIVATE -DMNN_SSE_USE_FP16_INSTEAD -mf16c)
|
||||
endif()
|
||||
endif()
|
||||
|
||||
if (MNN_LOW_MEMORY)
|
||||
target_compile_options(MNNX8664 PRIVATE -DMNN_LOW_MEMORY)
|
||||
target_compile_options(MNNSSE PRIVATE -DMNN_LOW_MEMORY)
|
||||
|
|
@ -101,8 +110,12 @@ if(CMAKE_SYSTEM_PROCESSOR MATCHES "(x86_64)|(X86_64)|(x64)|(X64)|(amd64)|(AMD64)
|
|||
target_compile_options(MNNAVX PRIVATE -DMNN_CPU_WEIGHT_DEQUANT_GEMM)
|
||||
target_compile_options(MNNAVXFMA PRIVATE -DMNN_CPU_WEIGHT_DEQUANT_GEMM)
|
||||
endif()
|
||||
list(APPEND MNN_OBJECTS_TO_LINK $<TARGET_OBJECTS:MNNX8664> $<TARGET_OBJECTS:MNNAVXFMA> $<TARGET_OBJECTS:MNNAVX> $<TARGET_OBJECTS:MNNSSE>)
|
||||
if (MSVC AND WIN_USE_ASM)
|
||||
list(APPEND MNN_OBJECTS_TO_LINK $<TARGET_OBJECTS:MNNX8664> $<TARGET_OBJECTS:MNNSSE>)
|
||||
if (MNN_AVX2)
|
||||
list(APPEND MNN_OBJECTS_TO_LINK $<TARGET_OBJECTS:MNNAVXFMA> $<TARGET_OBJECTS:MNNAVX>)
|
||||
endif()
|
||||
|
||||
if (MSVC AND WIN_USE_ASM AND MNN_AVX2)
|
||||
target_compile_options(MNNAVX PRIVATE -DMNN_X86_USE_ASM)
|
||||
target_compile_options(MNNAVXFMA PRIVATE -DMNN_X86_USE_ASM)
|
||||
list(APPEND MNN_OBJECTS_TO_LINK ${EXTRA_OBJS})
|
||||
|
|
|
|||
|
|
@ -17,11 +17,6 @@
|
|||
#include "cpu_id.h"
|
||||
#include "sse/FunctionSummary.hpp"
|
||||
// https://stackoverflow.com/a/11230437
|
||||
#if defined(_MSC_VER)
|
||||
#include <intrin.h>
|
||||
#else
|
||||
#include <x86intrin.h>
|
||||
#endif
|
||||
|
||||
struct FunctionGroup {
|
||||
int tileNumber = 8;
|
||||
|
|
@ -45,6 +40,11 @@ void _SSEMNNGetMatMulPackMode(int* eP, int *lP, int* hP) {
|
|||
}
|
||||
void MNNFunctionInit() {
|
||||
auto cpuFlags = libyuv::InitCpuFlags();
|
||||
#ifdef __EMSCRIPTEN__
|
||||
// TODO: Find better way
|
||||
cpuFlags |= libyuv::kCpuHasSSE41;
|
||||
cpuFlags |= libyuv::kCpuHasSSSE3;
|
||||
#endif
|
||||
auto coreFunction = MNN::MNNGetCoreFunctions();
|
||||
if (cpuFlags & libyuv::kCpuHasSSSE3) {
|
||||
coreFunction->MNNGetMatMulPackMode = _SSEMNNGetMatMulPackMode;
|
||||
|
|
@ -65,6 +65,7 @@ void MNNFunctionInit() {
|
|||
// Dynamic Quant
|
||||
coreFunction->MNNCountMaxMinValue = _SSE_MNNComputeScaleZeroScalar;
|
||||
}
|
||||
#ifdef MNN_USE_AVX
|
||||
if (cpuFlags & libyuv::kCpuHasAVX2) {
|
||||
MNN::AVX2Functions::init(cpuFlags);
|
||||
gFunc.MNNExpC8 = _AVX_MNNExpC8;
|
||||
|
|
@ -76,6 +77,7 @@ void MNNFunctionInit() {
|
|||
}
|
||||
gFunc.MNNNorm = _AVX_MNNNorm;
|
||||
}
|
||||
#endif
|
||||
_SSE_ImageProcessInit(coreFunction, cpuFlags);
|
||||
}
|
||||
|
||||
|
|
|
|||
|
|
@ -6,11 +6,7 @@
|
|||
// Copyright © 2018, Alibaba Group Holding Limited
|
||||
//
|
||||
|
||||
#if defined(_MSC_VER)
|
||||
#include <intrin.h>
|
||||
#else
|
||||
#include <x86intrin.h>
|
||||
#endif
|
||||
#include "core/SimdHeader.h"
|
||||
#include <MNN/MNNDefine.h>
|
||||
#include <stdint.h>
|
||||
|
||||
|
|
@ -56,7 +52,7 @@ void _AVX_MNNPackC4ForMatMul_A(float* destOrigin, float const** sourceGroup, con
|
|||
void _AVX_MNNExpC8(float* dest, const float* source, float* offset, const float* parameters, size_t countC8);
|
||||
void _AVX_MNNSoftmax(float* dest, const float* source, size_t size);
|
||||
void _AVX_MNNFloat2Int8(const float* src, int8_t* dst, size_t sizeQuad, const float* scalep, ssize_t minV, ssize_t maxV, const float* zeroPoint, ssize_t quanParamVec);
|
||||
void _AVX_MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t sizeQuad, ssize_t zeroPoint);
|
||||
void _AVX_MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t sizeQuad, const float* zeroPoint, ssize_t quanParamVec);
|
||||
void _AVX_MNNLineDepthWiseInt8AddBiasScaleUnit(int8_t* dstO, const int8_t* srcO, const int8_t* weightO, const QuanPostTreatParameters* parameters, size_t width, size_t src_w_step, size_t fw, size_t fh, size_t dilateX_step, size_t dilateY_step, int8_t* idxOrder);
|
||||
void _AVX_MNNComputeMatMulForE_1(const float* A, const float* B, float* C, const float* biasPtr, const MatMulParam* param, size_t tId);
|
||||
void _AVX_MNNPackC4ForMatMul_A_BF16(float* destOrigin, float const** sourceGroup, const int32_t* info, const int32_t* el);
|
||||
|
|
|
|||
|
|
@ -117,6 +117,7 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_w4(int8_t* dst, const int8_t* src, const
|
|||
}
|
||||
}
|
||||
}
|
||||
auto oneValue = _mm256_set1_epi16(1);
|
||||
//printf("e=%d, sz=%d, dz=%d\n", realDst, src_depth_quad, dst_depth_quad);
|
||||
if (GEMMINT8_AVX2_E == realDst) {
|
||||
for (int dz = 0; dz < dst_depth_quad; ++dz) {
|
||||
|
|
@ -130,40 +131,26 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_w4(int8_t* dst, const int8_t* src, const
|
|||
__m256i D01 = _mm256_set1_epi32(0);
|
||||
__m256i D02 = _mm256_set1_epi32(0);
|
||||
__m256i D03 = _mm256_set1_epi32(0);
|
||||
__m256i D10 = _mm256_set1_epi32(0);
|
||||
__m256i D11 = _mm256_set1_epi32(0);
|
||||
__m256i D12 = _mm256_set1_epi32(0);
|
||||
__m256i D13 = _mm256_set1_epi32(0);
|
||||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * weight_step_Y;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
LOAD_INT4_TO_INT8;
|
||||
auto W0 = _mm256_cvtepi8_epi16(w_0);
|
||||
auto W1 = _mm256_cvtepi8_epi16(w_1);
|
||||
auto w0 = _mm256_set_m128i(w_1, w_0);
|
||||
auto s0 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 0));
|
||||
auto s1 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 1));
|
||||
auto s2 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 2));
|
||||
auto s3 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 3));
|
||||
|
||||
auto s0 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 0));
|
||||
auto s1 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 1));
|
||||
auto s2 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 2));
|
||||
auto s3 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 3));
|
||||
auto S0 = _mm256_cvtepu8_epi16(s0);
|
||||
auto S1 = _mm256_cvtepu8_epi16(s1);
|
||||
auto S2 = _mm256_cvtepu8_epi16(s2);
|
||||
auto S3 = _mm256_cvtepu8_epi16(s3);
|
||||
|
||||
COMPUTE(0, 0);
|
||||
COMPUTE(1, 0);
|
||||
COMPUTE(0, 1);
|
||||
COMPUTE(1, 1);
|
||||
COMPUTE(0, 2);
|
||||
COMPUTE(1, 2);
|
||||
COMPUTE(0, 3);
|
||||
COMPUTE(1, 3);
|
||||
D00 = _mm256_add_epi32(D00, _mm256_madd_epi16(_mm256_maddubs_epi16(s0, w0), oneValue));
|
||||
D01 = _mm256_add_epi32(D01, _mm256_madd_epi16(_mm256_maddubs_epi16(s1, w0), oneValue));
|
||||
D02 = _mm256_add_epi32(D02, _mm256_madd_epi16(_mm256_maddubs_epi16(s2, w0), oneValue));
|
||||
D03 = _mm256_add_epi32(D03, _mm256_madd_epi16(_mm256_maddubs_epi16(s3, w0), oneValue));
|
||||
}
|
||||
auto D0 = NORMAL_HADD(D00, D10);
|
||||
auto D1 = NORMAL_HADD(D01, D11);
|
||||
auto D2 = NORMAL_HADD(D02, D12);
|
||||
auto D3 = NORMAL_HADD(D03, D13);
|
||||
auto D0 = D00;
|
||||
auto D1 = D01;
|
||||
auto D2 = D02;
|
||||
auto D3 = D03;
|
||||
auto scaleValue = _mm256_loadu_ps(scale_dz);
|
||||
auto weightBiasValue = _mm256_loadu_ps((float*)weightBias_dz);
|
||||
|
||||
|
|
@ -251,35 +238,23 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_w4(int8_t* dst, const int8_t* src, const
|
|||
__m256i D01 = _mm256_set1_epi32(0);
|
||||
__m256i D02 = _mm256_set1_epi32(0);
|
||||
|
||||
__m256i D10 = _mm256_set1_epi32(0);
|
||||
__m256i D11 = _mm256_set1_epi32(0);
|
||||
__m256i D12 = _mm256_set1_epi32(0);
|
||||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * weight_step_Y;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
LOAD_INT4_TO_INT8;
|
||||
|
||||
auto W0 = _mm256_cvtepi8_epi16(w_0);
|
||||
auto W1 = _mm256_cvtepi8_epi16(w_1);
|
||||
auto w0 = _mm256_set_m128i(w_1, w_0);
|
||||
auto s0 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 0));
|
||||
auto s1 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 1));
|
||||
auto s2 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 2));
|
||||
|
||||
auto s0 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 0));
|
||||
auto s1 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 1));
|
||||
auto s2 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 2));
|
||||
auto S0 = _mm256_cvtepu8_epi16(s0);
|
||||
auto S1 = _mm256_cvtepu8_epi16(s1);
|
||||
auto S2 = _mm256_cvtepu8_epi16(s2);
|
||||
|
||||
COMPUTE(0, 0);
|
||||
COMPUTE(1, 0);
|
||||
COMPUTE(0, 1);
|
||||
COMPUTE(1, 1);
|
||||
COMPUTE(0, 2);
|
||||
COMPUTE(1, 2);
|
||||
D00 = _mm256_add_epi32(D00, _mm256_madd_epi16(_mm256_maddubs_epi16(s0, w0), oneValue));
|
||||
D01 = _mm256_add_epi32(D01, _mm256_madd_epi16(_mm256_maddubs_epi16(s1, w0), oneValue));
|
||||
D02 = _mm256_add_epi32(D02, _mm256_madd_epi16(_mm256_maddubs_epi16(s2, w0), oneValue));
|
||||
}
|
||||
auto D0 = NORMAL_HADD(D00, D10);
|
||||
auto D1 = NORMAL_HADD(D01, D11);
|
||||
auto D2 = NORMAL_HADD(D02, D12);
|
||||
auto D0 = D00;
|
||||
auto D1 = D01;
|
||||
auto D2 = D02;
|
||||
auto scaleValue = _mm256_loadu_ps(scale_dz);
|
||||
auto weightBiasValue = _mm256_loadu_ps((float*)weightBias_dz);
|
||||
|
||||
|
|
@ -358,23 +333,17 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_w4(int8_t* dst, const int8_t* src, const
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * weight_step_Y;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
LOAD_INT4_TO_INT8;
|
||||
auto W0 = _mm256_cvtepi8_epi16(w_0);
|
||||
auto W1 = _mm256_cvtepi8_epi16(w_1);
|
||||
auto w0 = _mm256_set_m128i(w_1, w_0);
|
||||
auto s0 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 0));
|
||||
auto s1 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 1));
|
||||
|
||||
auto s0 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 0));
|
||||
auto s1 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 1));
|
||||
auto S0 = _mm256_cvtepu8_epi16(s0);
|
||||
auto S1 = _mm256_cvtepu8_epi16(s1);
|
||||
|
||||
COMPUTE(0, 0);
|
||||
COMPUTE(1, 0);
|
||||
COMPUTE(0, 1);
|
||||
COMPUTE(1, 1);
|
||||
D00 = _mm256_add_epi32(D00, _mm256_madd_epi16(_mm256_maddubs_epi16(s0, w0), oneValue));
|
||||
D01 = _mm256_add_epi32(D01, _mm256_madd_epi16(_mm256_maddubs_epi16(s1, w0), oneValue));
|
||||
}
|
||||
auto D0 = NORMAL_HADD(D00, D10);
|
||||
auto D1 = NORMAL_HADD(D01, D11);
|
||||
auto D0 = D00;
|
||||
auto D1 = D01;
|
||||
auto scaleValue = _mm256_loadu_ps(scale_dz);
|
||||
auto weightBiasValue = _mm256_loadu_ps((float*)weightBias_dz);
|
||||
|
||||
|
|
@ -438,18 +407,14 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_w4(int8_t* dst, const int8_t* src, const
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * weight_step_Y;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
LOAD_INT4_TO_INT8;
|
||||
auto W0 = _mm256_cvtepi8_epi16(w_0);
|
||||
auto W1 = _mm256_cvtepi8_epi16(w_1);
|
||||
auto w0 = _mm256_set_m128i(w_1, w_0);
|
||||
auto s0 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 0));
|
||||
|
||||
auto s0 = _mm_castps_si128(_mm_broadcast_ss((float*)src_z + 0));
|
||||
auto S0 = _mm256_cvtepu8_epi16(s0);
|
||||
|
||||
COMPUTE(0, 0);
|
||||
COMPUTE(1, 0);
|
||||
D00 = _mm256_add_epi32(D00, _mm256_madd_epi16(_mm256_maddubs_epi16(s0, w0), oneValue));
|
||||
}
|
||||
auto D0 = NORMAL_HADD(D00, D10);
|
||||
auto D0 = D00;
|
||||
auto scaleValue = _mm256_loadu_ps(scale_dz);
|
||||
auto weightBiasValue = _mm256_loadu_ps((float*)weightBias_dz);
|
||||
|
||||
|
|
@ -569,7 +534,7 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_Unit(int8_t* dst, const int8_t* src, cons
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * (GEMMINT8_AVX2_L * GEMMINT8_AVX2_H);
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
auto w0 = mm_loadu_si128(weight_sz + 16 * 0);
|
||||
auto w1 = mm_loadu_si128(weight_sz + 16 * 1);
|
||||
auto W0 = _mm256_cvtepi8_epi16(w0);
|
||||
|
|
@ -697,7 +662,7 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_Unit(int8_t* dst, const int8_t* src, cons
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * (GEMMINT8_AVX2_L * GEMMINT8_AVX2_H);
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
auto w0 = mm_loadu_si128(weight_sz + 16 * 0);
|
||||
auto w1 = mm_loadu_si128(weight_sz + 16 * 1);
|
||||
auto W0 = _mm256_cvtepi8_epi16(w0);
|
||||
|
|
@ -803,7 +768,7 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_Unit(int8_t* dst, const int8_t* src, cons
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * (GEMMINT8_AVX2_L * GEMMINT8_AVX2_H);
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
auto w0 = mm_loadu_si128(weight_sz + 16 * 0);
|
||||
auto w1 = mm_loadu_si128(weight_sz + 16 * 1);
|
||||
auto W0 = _mm256_cvtepi8_epi16(w0);
|
||||
|
|
@ -888,7 +853,7 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_Unit(int8_t* dst, const int8_t* src, cons
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * (GEMMINT8_AVX2_L * GEMMINT8_AVX2_H);
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
auto w0 = mm_loadu_si128(weight_sz + 16 * 0);
|
||||
auto w1 = mm_loadu_si128(weight_sz + 16 * 1);
|
||||
auto W0 = _mm256_cvtepi8_epi16(w0);
|
||||
|
|
@ -994,7 +959,7 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_Unit_Fast(int8_t* dst, const int8_t* src,
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * (GEMMINT8_AVX2_L * GEMMINT8_AVX2_H);
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
auto w0 = _mm256_loadu_si256((__m256i*)weight_sz);
|
||||
|
||||
auto s0 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 0));
|
||||
|
|
@ -1080,7 +1045,7 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_Unit_Fast(int8_t* dst, const int8_t* src,
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * (GEMMINT8_AVX2_L * GEMMINT8_AVX2_H);
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
auto w0 = _mm256_loadu_si256((__m256i*)weight_sz);
|
||||
|
||||
auto s0 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 0));
|
||||
|
|
@ -1152,7 +1117,7 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_Unit_Fast(int8_t* dst, const int8_t* src,
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * (GEMMINT8_AVX2_L * GEMMINT8_AVX2_H);
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
auto w0 = _mm256_loadu_si256((__m256i*)weight_sz);
|
||||
|
||||
auto s0 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 0));
|
||||
|
|
@ -1206,7 +1171,7 @@ void _AVX_MNNGemmInt8AddBiasScale_16x4_Unit_Fast(int8_t* dst, const int8_t* src,
|
|||
|
||||
for (int sz = 0; sz < src_depth_quad; ++sz) {
|
||||
const auto weight_sz = weight_dz + sz * (GEMMINT8_AVX2_L * GEMMINT8_AVX2_H);
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * GEMMINT8_AVX2_E;
|
||||
const auto src_z = src_x + sz * GEMMINT8_AVX2_L * realDst;
|
||||
auto w0 = _mm256_loadu_si256((__m256i*)weight_sz);
|
||||
|
||||
auto s0 = _mm256_castps_si256(_mm256_broadcast_ss((float*)src_z + 0));
|
||||
|
|
@ -1353,12 +1318,18 @@ void _AVX_MNNFloat2Int8(const float* src, int8_t* dst, size_t sizeQuad, const fl
|
|||
}
|
||||
}
|
||||
|
||||
void _AVX_MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t sizeQuad, ssize_t zeroPoint) {
|
||||
void _AVX_MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale, size_t sizeQuad, const float* zeroPoint, ssize_t quanParamVec) {
|
||||
auto sizeC4 = sizeQuad / 4;
|
||||
auto sizeRemain = sizeQuad % 4;
|
||||
auto zero = _mm256_set1_epi32(0);
|
||||
auto scaleValue = _mm256_loadu_ps(scale);
|
||||
auto zeroPointValue = _mm256_set1_epi32(zeroPoint + 128);
|
||||
auto scaleValue = _mm256_set1_ps(scale[0]);
|
||||
auto zeroPointValue = _mm256_set1_ps(zeroPoint[0] + 128.f);
|
||||
if (quanParamVec & 1) {
|
||||
scaleValue = _mm256_loadu_ps(scale);
|
||||
}
|
||||
if (quanParamVec >> 1) {
|
||||
zeroPointValue = _mm256_add_ps(_mm256_loadu_ps(zeroPoint), _mm256_set1_ps(128.f));
|
||||
}
|
||||
for (int i = 0; i < sizeC4; ++i) {
|
||||
auto s = _mm256_castps_si256(_mm256_loadu_ps((const float*)(src)));
|
||||
auto s0_16 = _mm256_permute4x64_epi64(_mm256_unpacklo_epi8(s, zero), 0XD8);
|
||||
|
|
@ -1367,14 +1338,14 @@ void _AVX_MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale,
|
|||
auto s1_32 = _mm256_unpacklo_epi16(s1_16, zero);
|
||||
auto s2_32 = _mm256_unpackhi_epi16(s0_16, zero);
|
||||
auto s3_32 = _mm256_unpackhi_epi16(s1_16, zero);
|
||||
s0_32 = _mm256_sub_epi32(s0_32, zeroPointValue);
|
||||
s1_32 = _mm256_sub_epi32(s1_32, zeroPointValue);
|
||||
s2_32 = _mm256_sub_epi32(s2_32, zeroPointValue);
|
||||
s3_32 = _mm256_sub_epi32(s3_32, zeroPointValue);
|
||||
auto s0_f = _mm256_cvtepi32_ps(s0_32);
|
||||
auto s1_f = _mm256_cvtepi32_ps(s1_32);
|
||||
auto s2_f = _mm256_cvtepi32_ps(s2_32);
|
||||
auto s3_f = _mm256_cvtepi32_ps(s3_32);
|
||||
s0_f = _mm256_sub_ps(s0_f, zeroPointValue);
|
||||
s1_f = _mm256_sub_ps(s1_f, zeroPointValue);
|
||||
s2_f = _mm256_sub_ps(s2_f, zeroPointValue);
|
||||
s3_f = _mm256_sub_ps(s3_f, zeroPointValue);
|
||||
_mm256_storeu_ps(dst + 8 * 0, _mm256_mul_ps(s0_f, scaleValue));
|
||||
_mm256_storeu_ps(dst + 8 * 1, _mm256_mul_ps(s1_f, scaleValue));
|
||||
_mm256_storeu_ps(dst + 8 * 2, _mm256_mul_ps(s2_f, scaleValue));
|
||||
|
|
@ -1392,14 +1363,14 @@ void _AVX_MNNInt8ScaleToFloat(float* dst, const int8_t* src, const float* scale,
|
|||
auto s1_32 = _mm256_unpacklo_epi16(s1_16, zero);
|
||||
auto s2_32 = _mm256_unpackhi_epi16(s0_16, zero);
|
||||
auto s3_32 = _mm256_unpackhi_epi16(s1_16, zero);
|
||||
s0_32 = _mm256_sub_epi32(s0_32, zeroPointValue);
|
||||
s1_32 = _mm256_sub_epi32(s1_32, zeroPointValue);
|
||||
s2_32 = _mm256_sub_epi32(s2_32, zeroPointValue);
|
||||
s3_32 = _mm256_sub_epi32(s3_32, zeroPointValue);
|
||||
auto s0_f = _mm256_cvtepi32_ps(s0_32);
|
||||
auto s1_f = _mm256_cvtepi32_ps(s1_32);
|
||||
auto s2_f = _mm256_cvtepi32_ps(s2_32);
|
||||
auto s3_f = _mm256_cvtepi32_ps(s3_32);
|
||||
s0_f = _mm256_sub_ps(s0_f, zeroPointValue);
|
||||
s1_f = _mm256_sub_ps(s1_f, zeroPointValue);
|
||||
s2_f = _mm256_sub_ps(s2_f, zeroPointValue);
|
||||
s3_f = _mm256_sub_ps(s3_f, zeroPointValue);
|
||||
switch (sizeRemain) {
|
||||
case 3:
|
||||
_mm256_storeu_ps(dst + 8 * 0, _mm256_mul_ps(s0_f, scaleValue));
|
||||
|
|
@ -1436,23 +1407,37 @@ static void _AVXMNNPackC4ForMatMul_A(int8_t* destOrigin, int8_t const** sourceGr
|
|||
const int EP = GEMMINT8_AVX2_E;
|
||||
int eDest = EP;
|
||||
const int LP = GEMMINT8_AVX2_L;
|
||||
int realDstCount = info[4];
|
||||
for (int n=0; n<number; ++n) {
|
||||
int e = el[4 * n + 0];
|
||||
int l = el[4 * n + 1];
|
||||
int eOffset = el[4 * n + 2];
|
||||
int lOffset = el[4 * n + 3];
|
||||
int eC = eOffset / eDest;
|
||||
int eR = eOffset % eDest;
|
||||
int eC = eOffset / EP;
|
||||
int eR = eOffset % EP;
|
||||
int eS = eDest - eR;
|
||||
bool lastBag = false;
|
||||
int eOutsideStride4LastBag = eOutsideStride;
|
||||
if (realDstCount % EP > 0) {
|
||||
int jobsE = realDstCount - eOffset - e;
|
||||
if (jobsE == 0 || (jobsE < (realDstCount % EP))) {
|
||||
lastBag = true;
|
||||
}
|
||||
}
|
||||
auto source = (int32_t*)sourceGroup[n];
|
||||
auto dest = (int32_t*)(destOrigin + eC * info[2] + eR * LP + lOffset * EP);
|
||||
//printf("e=%d, l=%d, eOffset=%d, lOffset=%d, eDest=%d\n", e, l, eOffset, lOffset, eDest);
|
||||
l = l / 4; // Use float instead of int8 * 4
|
||||
int eS = eDest - eR;
|
||||
if (lastBag && e + eR < EP) {
|
||||
int elast = ALIMAX(eR + e, realDstCount % EP);
|
||||
dest = (int32_t*)(destOrigin + lOffset * elast + eC * info[2] + eR * LP);
|
||||
}
|
||||
int offsetLC = lOffset / 4;
|
||||
for (int x = 0; x < l; ++x) {
|
||||
int eRemain = e;
|
||||
auto xR = x % PUNIT;
|
||||
auto xC = x / PUNIT;
|
||||
auto d = dest + x * eDest;
|
||||
auto d = dest;
|
||||
auto s = source + xC * eReal * FLOATPACK + xR;
|
||||
if (eR > 0) {
|
||||
int eStep = ALIMIN(eRemain, eS);
|
||||
|
|
@ -1460,7 +1445,13 @@ static void _AVXMNNPackC4ForMatMul_A(int8_t* destOrigin, int8_t const** sourceGr
|
|||
d[yi] = s[yi * xS4];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag ||eRemain >= EP) {
|
||||
d += (eOutsideStride - eR);
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * 4 * offsetLC / sizeof(float));
|
||||
d += (eOutsideStride4LastBag - eR + offsetLC * eFill);
|
||||
}
|
||||
s += eS * xS4;
|
||||
}
|
||||
while (eRemain > 0) {
|
||||
|
|
@ -1469,9 +1460,22 @@ static void _AVXMNNPackC4ForMatMul_A(int8_t* destOrigin, int8_t const** sourceGr
|
|||
d[yi] = s[yi * xS4];
|
||||
}
|
||||
eRemain-=eStep;
|
||||
if (!lastBag || eRemain >= EP) {
|
||||
d+= eOutsideStride;
|
||||
} else {
|
||||
int eFill = ALIMAX(eRemain, realDstCount % EP); // maybe padding>0
|
||||
eOutsideStride4LastBag = eOutsideStride - (EP * 4 * offsetLC / sizeof(float));
|
||||
d+= (eOutsideStride4LastBag + offsetLC * eFill);
|
||||
}
|
||||
s+= eStep * xS4;
|
||||
}
|
||||
if (lastBag && e + eR < EP) {
|
||||
int efill = ALIMAX(e + eR, realDstCount % EP);
|
||||
dest += efill;
|
||||
} else {
|
||||
dest += eDest;
|
||||
}
|
||||
offsetLC++;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
|
|
|||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue