9.5 KiB
MNN Chat Android App
简介
这是我们的全功能多模态语言模型(LLM)安卓应用。


功能亮点
-
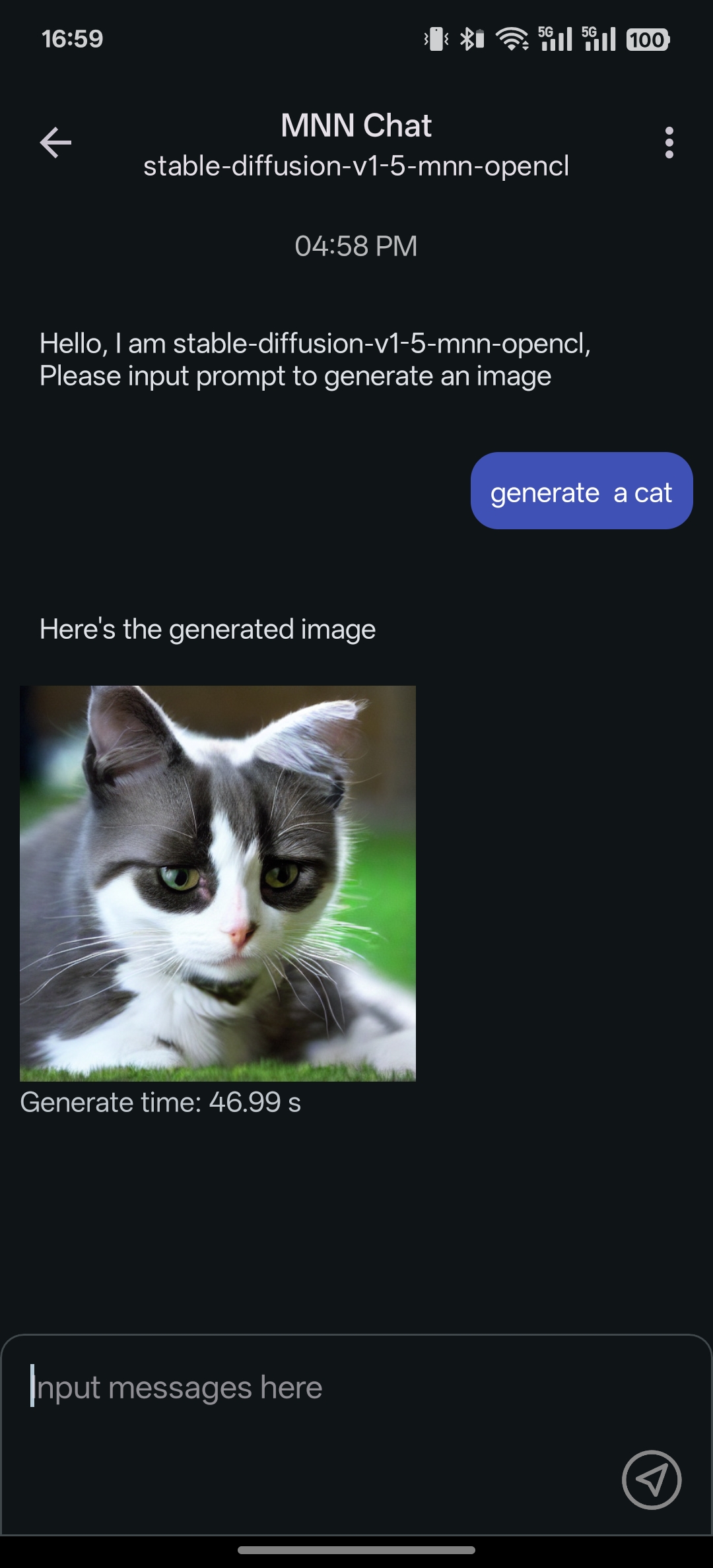
多模态支持: 提供多种任务功能,包括文本生成文本、图像生成文本、音频转文本及文本生成图像(基于扩散模型)。
-
CPU推理优化: 在安卓平台上,MNN-LLM展现了卓越的CPU性能,预填充速度相较于llama.cpp提高了8.6倍,相较于fastllm提升了20.5倍,解码速度分别快了2.3倍和8.9倍。下图为 llama.cpp 与 MNN-LLM 与 llama.cpp 的比较。
-
广泛的模型兼容性: 支持多种领先的模型提供商,包括Qwen、Gemma、Llama(涵盖TinyLlama与MobileLLM)、Baichuan、Yi、DeepSeek、InternLM、Phi、ReaderLM和Smolm。
-
本地运行: 完全在设备本地运行,确保数据隐私,无需将信息上传至外部服务器。
使用说明
您可以通过 Releases 下载应用,或者 自行构建(#开发)。
- 安装应用后,您可以浏览所有支持的模型,下载所需模型,并直接在应用内与模型交互。
- 此外,您可以通过侧边栏访问聊天历史,轻松查看和管理之前的对话记录。
!!!warning!!! 此版本目前仅在 OnePlus 13 和 小米 14 Ultra 上进行了测试。由于大型语言模型(LLM)对设备性能要求较高,许多低配置设备可能会遇到以下问题:推理速度缓慢、应用不稳定甚至无法运行。对于其他设备的稳定性无法保证。如果您在使用过程中遇到问题,请随时提交问题以获取帮助。
开发
- 克隆代码库:
git clone https://github.com/alibaba/MNN.git - 构建库:
cd project/android mkdir build_64 ../build_64.sh "-DMNN_LOW_MEMORY=true -DMNN_CPU_WEIGHT_DEQUANT_GEMM=true -DMNN_BUILD_LLM=true -DMNN_SUPPORT_TRANSFORMER_FUSE=true -DMNN_ARM82=true -DMNN_USE_LOGCAT=true -DMNN_OPENCL=true -DLLM_SUPPORT_VISION=true -DMNN_BUILD_OPENCV=true -DMNN_IMGCODECS=true -DLLM_SUPPORT_AUDIO=true -DMNN_BUILD_AUDIO=true -DMNN_BUILD_DIFFUSION=ON -DMNN_SEP_BUILD=OFF -DCMAKE_INSTALL_PREFIX=." make install - 构建 Android 应用项目并安装:
cd ../../../apps/Android/MnnLlmChat ./installDebug.sh
Releases
Version 0.7.5
- 点击这里 下载
- 新增 Qwen3-VL 支持(4B、8B、30B-A3B)
- 支持 smolvlm-video 系列的视频输入
Version 0.7.3
- 点击这里 下载
- 优化 API 服务
版本 0.7.2
- 点击这里 下载
- 问题修复:
- 修复通义千问思考/不思考开关有时不生效的问题。
- 界面更新:
- 更新历史记录和性能测试界面。
版本 0.7.1
- 点击此处下载
- 新增模型:
- MiniCPM-V-4:可在手机上运行的、达到 GPT-4V 水准的多模态大语言模型,支持单图、多图和视频理解
- WebSailor-3B:一种完整的后训练方法论,旨在教会大语言模型代理在复杂网页导航和信息检索任务中进行高级推理
- Lingshu-7B:面向医疗领域的多模态大语言模型
- 问题修复:
- 选择图片时崩溃的问题
Version 0.7.0
- Click here to download
- 增加新模型: gpt-oss-20b
0.6.8
- 点击这里 下载
- 新增模型支持 :现已支持 SmolLM3-3B 和 gemma-3-1b 模型。
- 采样器功能增强 :在混合采样器模式中新增对 penalty sampler 的支持,提升生成质量与多样性。
- 模型切换优化 :在聊天界面中支持 实时切换模型 ,提升使用灵活性。
- 模型热更新支持 :当远程模型发生变化时,无需删除原有模型即可完成更新,避免重复下载。
- 下载源优化 :优化了 HuggingFace 模型的下载源,提升下载速度与稳定性。
- 新增语音通话功能 :支持 实时语音对话 ,集成语音识别(ASR)与语音合成(TTS)功能,带来更丰富的交互体验。
Version 0.5.1.2
- 点击这里 下载
- 解决 huggingface 下载失败问题。
- 解决未下载时候状态显示错误。
Version 0.5.1.1
- 点击这里 下载
- 升级 MNN 引擎到 v3.2.0
- 修复一些 bug
Version 0.5.1
- 点击这里 下载
- 支持 DeepSeek-R1-0528-Qwen3
- 修复了一些 bug:
- 首次安装时,如果系统语言是中文,则使用 ModelScope
- 如果不是强制检查更新(forceCheckUpdate),则不显示对话框
- 显示本地模型的模型大小
Version 0.5.0
- 点击这里 下载
- 支持 Qwen3-30B-A3B
- 支持 新的视觉模型 SmoVLM 与 FastVLM
- 支持增加本地模型(adb push)
- 增加高级配置选项: precision, 线程数
- UI更新:
- 支持是否已经下载,模态、供应商过滤模型列表。
- 支持隐藏思考过程。
Version 0.4.4.1
- 点击这里 下载
- 解决无法选择 Assistant文本问题。
- 解决魔乐下载校验失败问题
Version 0.4.4
- 点击这里 下载
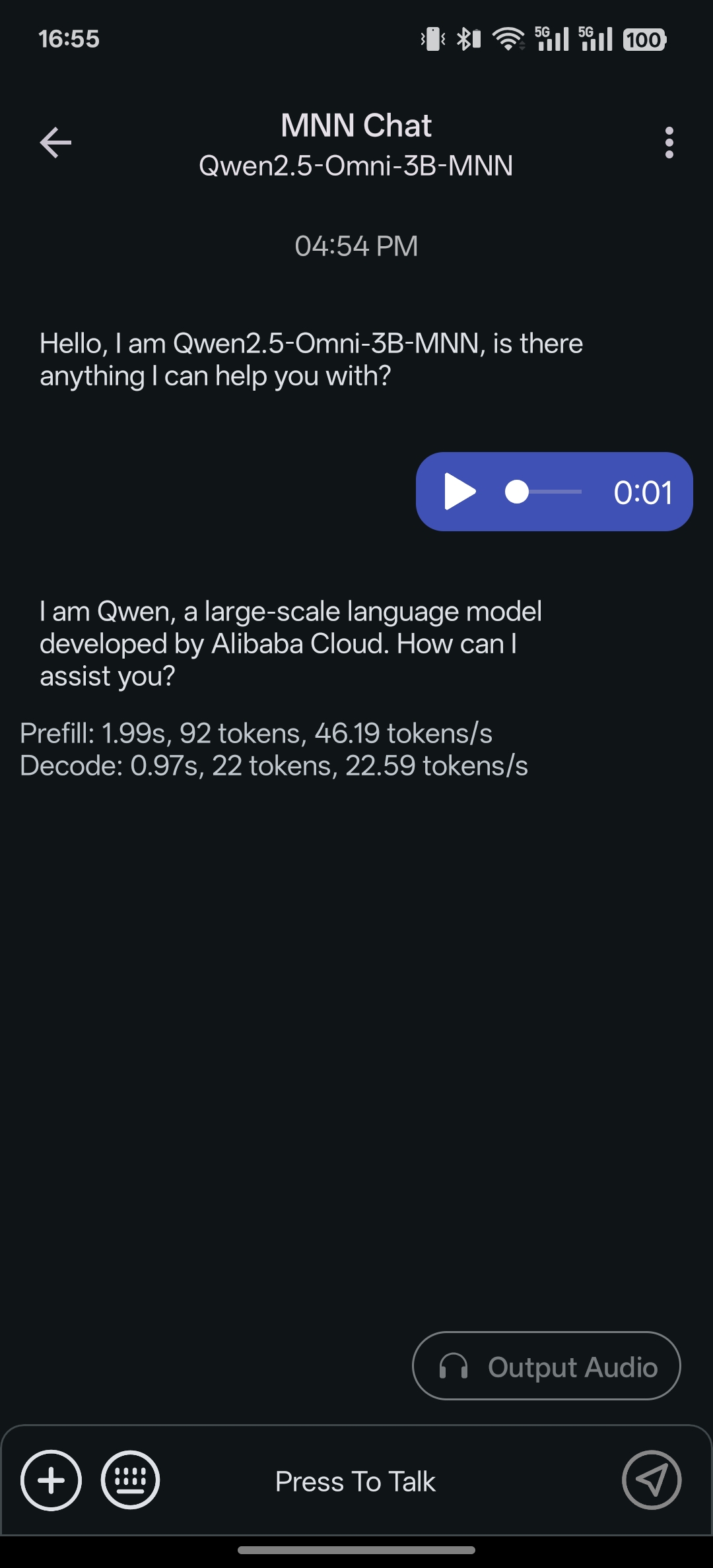
- Qwen Omni 的支持语音输出开关
- 模型列表可显示模型大小
Version 0.4.3
- 点击这里 下载
- 支持小米 mimo 模型 UI
- 新增对 Qwen Omni 的支持
- 聊天页面界面发送后隐藏附件
- 显示总解码时间和预填充时间
- 聊天界面支持复制用户消息
- 解决下载错误
- 修复在某些设备上下载崩溃的问题
- 支持上报崩溃日志
- 支持多模态模型的多轮对话
- 重构下载模块,Chat模块
Version 0.4.0
- 点击这里 下载
- 兼容 Qwen3 模型,支持开启/关闭“深度思考”模式
- 新增深色模式,全面适配 Material 3 设计规范
- 优化聊天界面,支持多行输入
- 增加「设置」页面,可自定义采样器类型(sampler type)、系统提示(system prompt)、最大生成 Token(max new tokens)等参数
Version 0.3.0
- 点击这里 下载
- 将 MNN 引擎升级至 v3.1.0
- 新增设置页面
- 显示下载速度
- 支持筛选已下载的模型
- 支持从 modelers.cn 下载模型
Version 0.2.2
- 点击这里 下载
- 支持 mmap 增加启动速度
- 增加 版本更新检查
Version 0.2.1
- 点击这里下载
- 支持 modelscope 下载,
- 优化deepseek 多轮会话能力以及展示 ui
- 支持 反馈 issue 时候增加调试信息
Version 0.2.0
- 点击这里下载
- 针对 DeepSeek R1 1.5B 进行了优化
- 新增支持 Markdown 格式
- 修复了一些已知问题
Version 0.1
- 点击这里下载
- 这是我们的首个公开发布版本,您可以:
- 搜索我们支持的所有模型,在应用中下载并与其聊天;
- 生成扩散模型:
- stable-diffusion-v1-5
- 音频模型:
- qwen2-audio-7b
- 视觉模型:
- qwen-vl-chat
- qwen2-vl-2b
- qwen2-vl-7b
关于 MNN-LLM
MNN-LLM 是一个多功能的推理框架,旨在优化和加速大语言模型在移动设备和本地 PC 上的部署。通过模型量化、混合存储和硬件特定优化等创新措施,解决高内存消耗和计算成本等挑战。在 CPU 基准测试中,MNN-LLM 表现优异,其预填充速度比 llama.cpp 快 8.6 倍,比 fastllm 快 20.5 倍,同时解码速度分别快 2.3 倍和 8.9 倍。在基于 GPU 的评估中,由于 MLC-LLM 的对称量化技术优势,MNN-LLM 的性能在使用 Qwen2-7B 进行较短提示时略有下降。MNN-LLM 的预填充速度比 llama.cpp 快 25.3 倍,解码速度快 7.1 倍,相较于 MLC-LLM 也分别提高 2.8 倍和 1.7 倍。如需更详细的信息,请参考论文:MNN-LLM: A Generic Inference Engine for Fast Large LanguageModel Deployment on Mobile Devices
致谢
该项目基于以下开源项目: