48 KiB
熊猫中的设置与拷贝警告:视图与拷贝
NumPy 和 Pandas 是非常全面、高效、灵活的数据操作 Python 工具。这两个库的熟练用户需要理解的一个重要概念是,数据是如何被引用为浅层副本 ( 视图)和深层副本(或者仅仅是副本)。Pandas 有时会发出一个SettingWithCopyWarning来警告用户对视图和副本的潜在不当使用。
在这篇文章中,你将了解到:
- 什么视图和副本在 NumPy 和熊猫
- 如何在 NumPy 和 Pandas 中正确使用视图和副本
- 为什么
SettingWithCopyWarning发生在熊猫身上 - 如何避免在熊猫身上受伤
你首先会看到一个简短的解释什么是SettingWithCopyWarning以及如何避免它。您可能会发现这已经足够满足您的需求,但是您还可以更深入地了解 NumPy 和 Pandas 的细节,以了解更多关于副本和视图的信息。
免费奖励: 点击此处获取免费的 NumPy 资源指南,它会为您指出提高 NumPy 技能的最佳教程、视频和书籍。
先决条件
为了遵循本文中的例子,您将需要 Python 3.7 或 3.8 ,以及库 NumPy 和 Pandas 。本文是为 NumPy 1 . 18 . 1 版和 Pandas 1 . 0 . 3 版编写的。你可以用pip安装它们:
$ python -m pip install -U "numpy==1.18.*" "pandas==1.0.*"
如果你喜欢 Anaconda T1 或 T2 Miniconda T3 发行版,你可以使用 T4 conda T5 软件包管理系统。要了解关于这种方法的更多信息,请查看在 Windows 上为机器学习设置 Python。现在,在您的环境中安装 NumPy 和 Pandas 就足够了:
$ conda install numpy=1.18.* pandas=1.0.*
现在您已经安装了 NumPy 和 Pandas,您可以导入它们并检查它们的版本:
>>> import numpy as np
>>> import pandas as pd
>>> np.__version__
'1.18.1'
>>> pd.__version__
'1.0.3'
就是这样。您已经具备了这篇文章的所有先决条件。您的版本可能略有不同,但下面的信息仍然适用。
**注:**本文要求你先有一些熊猫知识。对于后面的部分,您还需要一些 NumPy 知识。
要更新您的数字技能,您可以查看以下资源:
为了提醒自己关于熊猫的事情,你可以阅读以下内容:
现在你已经准备好开始学习视图、副本和SettingWithCopyWarning!
SettingWithCopyWarning的一个例子
如果你和熊猫一起工作,你很可能已经看过一次行动。这很烦人,有时很难理解。然而,它的发布是有原因的。
关于SettingWithCopyWarning你应该知道的第一件事是,它是而不是一个错误。这是一个警告。它警告您,您可能已经做了一些会在代码中导致不想要的行为的事情。
让我们看一个例子。你将从创建一个熊猫数据帧开始:
>>> data = {"x": 2**np.arange(5),
... "y": 3**np.arange(5),
... "z": np.array([45, 98, 24, 11, 64])}
>>> index = ["a", "b", "c", "d", "e"]
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
- 键
"x"、"y"和"z",它们将是数据帧的列标签 - 三个 NumPy 数组,保存数据帧的数据
用例程 numpy.arange() 创建前两个数组,用 numpy.array() 创建最后一个数组。要了解更多关于arange()的信息,请查看 NumPy arange():如何使用 np.arange() 。
附加在变量index上的列表包含了字符串 "a"、"b"、"c"、"d"和"e",它们将成为数据帧的行标签。
最后,初始化包含来自data和index的信息的数据帧 df。你可以这样想象:
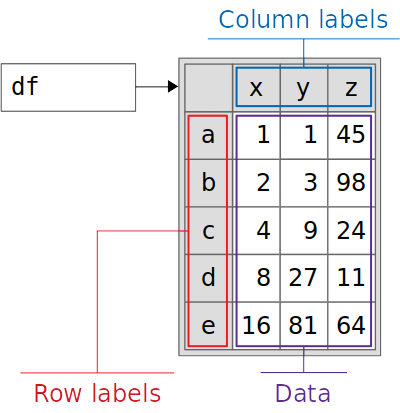
下面是数据帧中包含的主要信息的分类:
- **紫色方框:**数据
- **蓝色框:**列标签
- **红框:**行标签
数据帧存储附加信息或元数据,包括其形状、数据类型等。
现在您已经有了一个数据框架,让我们试着获取一个SettingWithCopyWarning。您将从列z中取出所有小于 50 的值,并用零替换它们。你可以从创建一个遮罩开始,或者用熊猫布尔运算符创建一个滤镜:
>>> mask = df["z"] < 50
>>> mask
a True
b False
c True
d True
e False
Name: z, dtype: bool
>>> df[mask]
x y z
a 1 1 45
c 4 9 24
d 8 27 11
mask是熊猫系列的实例,具有布尔数据和来自df的索引:
True表示df中z的值小于50的行。False表示df中z的值为而非小于50的行。
df[mask]返回来自df的数据帧,其中mask为True。在这种情况下,您会得到行a、c和d。
如果您试图通过使用mask提取行a、c和d来改变df,您将得到一个SettingWithCopyWarning,而df将保持不变:
>>> df[mask]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
如您所见,向列z分配零失败。这张图片展示了整个过程:
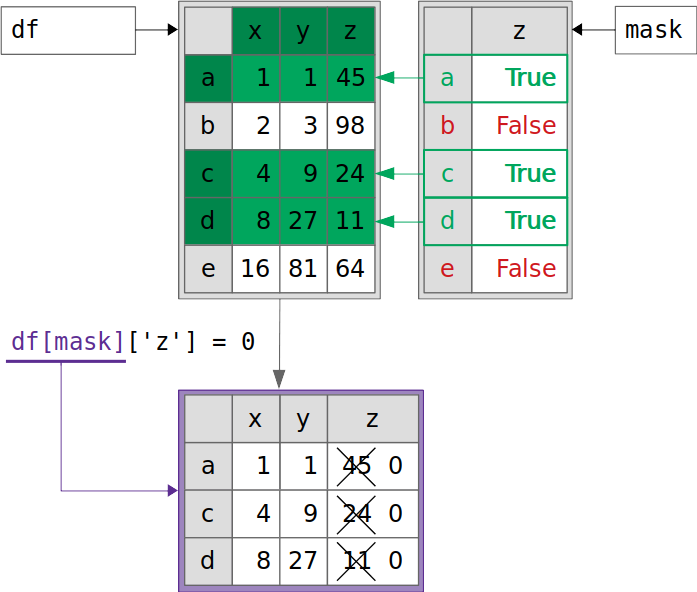
下面是上面代码示例中发生的情况:
df[mask]返回一个全新的数据帧(用紫色标出)。该数据帧保存了来自df的数据的副本,这些数据对应于来自mask的True值(以绿色突出显示)。df[mask]["z"] = 0将新数据帧的列z修改为零,保持df不变。
通常情况下,你不会想要这样的!你想要修改df而不是一些没有被任何变量引用的中间数据结构。这就是为什么熊猫会发出一个SettingWithCopyWarning警告你这个可能的错误。
在这种情况下,修改df的正确方法是应用访问器 .loc[] 、 .iloc[] 、 .at[] 或 .iat[] 中的一个:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask, "z"] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
这种方法使您能够向为 DataFrame 赋值的单个方法提供两个参数mask和"z"。
解决此问题的另一种方法是更改评估顺序:
>>> df = pd.DataFrame(data=data, index=index)
>>> df["z"]
a 45
b 98
c 24
d 11
e 64
Name: z, dtype: int64
>>> df["z"][mask] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
这个管用!您修改了df。这个过程是这样的:
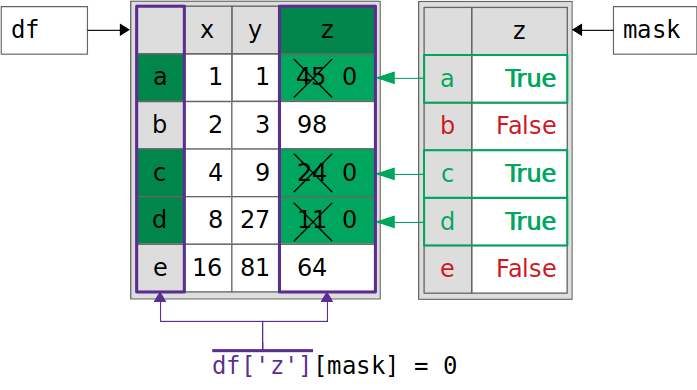
这是图像的分解:
df["z"]返回一个Series对象(用紫色标出),该对象指向与df中的z列相同的数据,而不是其副本。df["z"][mask] = 0通过使用链式赋值将屏蔽值(以绿色突出显示)设置为零来修改此Series对象。df也被修改,因为Series对象df["z"]持有与df相同的数据。
您已经看到df[mask]包含数据的副本,而df["z"]指向与df相同的数据。熊猫用来决定你是否复制的规则非常复杂。幸运的是,有一些简单的方法可以给数据帧赋值并避免SettingWithCopyWarning。
调用访问器通常被认为是比链式赋值更好的实践,原因如下:
- 当你使用单一方法时,修改
df的意图对熊猫来说更加清晰。 - 代码对读者来说更清晰。
- 访问器往往具有更好的性能,尽管在大多数情况下您不会注意到这一点。
然而,使用访问器有时是不够的。他们也可能返回副本,在这种情况下,您可以获得一个SettingWithCopyWarning:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
在这个例子中,和上一个例子一样,您使用了访问器.loc[]。赋值失败是因为df.loc[mask]返回一个新的数据帧,其中包含来自df的数据副本。然后df.loc[mask]["z"] = 0修改新的数据帧,而不是df。
一般来说,为了避免熊猫出现SettingWithCopyWarning,你应该做以下事情:
- 避免像
df["z"][mask] = 0和df.loc[mask]["z"] = 0那样结合两个或更多步进操作的链式分配。 - 只需像
df.loc[mask, "z"] = 0一样进行一次步进操作,即可应用单次分配。这可能涉及(也可能不涉及)访问器的使用,但它们肯定非常有用,而且通常是首选。
有了这些知识,你可以在大多数情况下成功地避免SettingWithCopyWarning和任何不想要的行为。但是,如果你想更深入地了解 NumPy、Pandas、views、copies 以及与SettingWithCopyWarning相关的问题,那么请继续阅读本文的其余部分。
NumPy 和 Pandas 中的视图和副本
理解视图和副本是了解 NumPy 和 Pandas 如何操作数据的重要部分。它还可以帮助您避免错误和性能瓶颈。有时数据从内存的一部分复制到另一部分,但在其他情况下,两个或多个对象可以共享相同的数据,从而节省时间和内存。
了解 NumPy 中的视图和副本
让我们从创建一个 NumPy 数组开始:
>>> arr = np.array([1, 2, 4, 8, 16, 32])
>>> arr
array([ 1, 2, 4, 8, 16, 32])
现在已经有了arr,可以用它来创建其他数组。我们先把arr ( 2和8)的第二个和第四个元素提取出来作为一个新数组。有几种方法可以做到这一点:
>>> arr[1:4:2]
array([2, 8])
>>> arr[[1, 3]]
array([2, 8]))
如果您不熟悉数组索引,也不用担心。稍后你会学到更多关于这些和其他陈述的内容。现在,重要的是要注意这两个语句都返回array([2, 8])。然而,他们在表面下有不同的行为:
>>> arr[1:4:2].base
array([ 1, 2, 4, 8, 16, 32])
>>> arr[1:4:2].flags.owndata
False
>>> arr[[1, 3]].base
>>> arr[[1, 3]].flags.owndata
True
乍一看,这似乎很奇怪。不同之处在于,arr[1:4:2]返回一个浅拷贝,而arr[[1, 3]]返回一个深拷贝。理解这种差异不仅对处理SettingWithCopyWarning至关重要,对用 NumPy 和 Pandas 处理大数据也是如此。
在下面几节中,您将了解更多关于 NumPy 和 Pandas 中的浅拷贝和深拷贝。
数字视图
一个浅拷贝或视图是一个没有自己数据的 NumPy 数组。它查看原始数组中包含的数据。您可以使用 .view() 创建一个数组视图:
>>> view_of_arr = arr.view()
>>> view_of_arr
array([ 1, 2, 4, 8, 16, 32])
>>> view_of_arr.base
array([ 1, 2, 4, 8, 16, 32])
>>> view_of_arr.base is arr
True
您已经获得了数组view_of_arr,这是原始数组arr的一个视图或简单副本。view_of_arr的属性 .base 就是arr本身。换句话说,view_of_arr不拥有任何数据——它使用属于arr的数据。您也可以使用属性 .flags 来验证这一点:
>>> view_of_arr.flags.owndata
False
如你所见,view_of_arr.flags.owndata就是False。这意味着view_of_arr并不拥有数据,而是使用它的.base来获取数据:
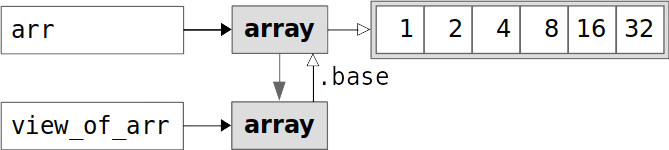
上图显示arr和view_of_arr指向相同的数据值。
份数
NumPy 数组的深度副本,有时也称为副本,是一个独立的 NumPy 数组,拥有自己的数据。深层副本的数据是通过将原始数组的元素复制到新数组中获得的。原件和副本是两个独立的实例。您可以使用 .copy() 创建数组的副本:
>>> copy_of_arr = arr.copy()
>>> copy_of_arr
array([ 1, 2, 4, 8, 16, 32])
>>> copy_of_arr.base is None
True
>>> copy_of_arr.flags.owndata
True
如你所见,copy_of_arr没有.base。更准确的说,copy_of_arr.base的值是 None 。属性.flags.owndata是True。这意味着copy_of_arr拥有数据:
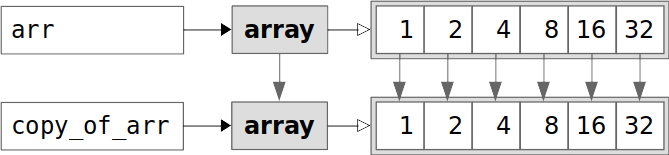
上图显示了arr和copy_of_arr包含数据值的不同实例。
视图和副本之间的差异
视图和副本之间有两个非常重要的区别:
- 视图不需要额外的数据存储,但是副本需要。
- 修改原始阵列会影响其视图,反之亦然。然而,修改原始数组将而不是影响它的副本。
为了说明视图和副本之间的第一个区别,让我们比较一下arr、view_of_arr和copy_of_arr的大小。属性 .nbytes 返回数组元素消耗的内存:
>>> arr.nbytes
48
>>> view_of_arr.nbytes
48
>>> copy_of_arr.nbytes
48
所有数组的内存量都是一样的:48 字节。每个数组查看 6 个 8 字节(64 位)的整数元素。总共有 48 个字节。
但是,如果您使用 sys.getsizeof() 来获得直接归属于每个数组的内存量,那么您会看到不同之处:
>>> from sys import getsizeof
>>> getsizeof(arr)
144
>>> getsizeof(view_of_arr)
96
>>> getsizeof(copy_of_arr)
144
arr和copy_of_arr各保存 144 字节。正如您之前看到的,总共 144 个字节中有 48 个字节是用于数据元素的。剩余的 96 个字节用于其他属性。view_of_arr只保存这 96 个字节,因为它没有自己的数据元素。
为了说明视图和副本之间的第二个区别,您可以修改原始数组的任何元素:
>>> arr[1] = 64
>>> arr
array([ 1, 64, 4, 8, 16, 32])
>>> view_of_arr
array([ 1, 64, 4, 8, 16, 32])
>>> copy_of_arr
array([ 1, 2, 4, 8, 16, 32])
如您所见,视图也发生了变化,但副本保持不变。下图显示了该代码:
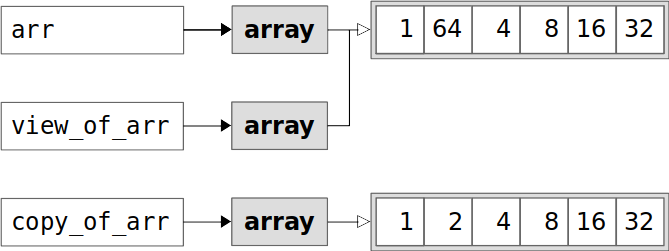
视图被修改是因为它查看了arr的元素,而它的.base是原始数组。副本是不变的,因为它不与原始文件共享数据,所以对原始文件的更改根本不会影响它。
了解 Pandas 中的视图和副本
Pandas 还区分了视图和副本。您可以使用 .copy() 创建数据帧的视图或副本。参数deep决定您是想要查看(deep=False)还是复制(deep=True)。deep默认为True,所以你可以省略它得到一个副本:
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> view_of_df = df.copy(deep=False)
>>> view_of_df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> copy_of_df = df.copy()
>>> copy_of_df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
起初,df的视图和副本看起来是一样的。但是,如果您比较它们的数字表示,那么您可能会注意到这种微妙的差异:
>>> view_of_df.to_numpy().base is df.to_numpy().base
True
>>> copy_of_df.to_numpy().base is df.to_numpy().base
False
这里, .to_numpy() 返回保存数据帧数据的 NumPy 数组。你可以看到df和view_of_df有相同的.base,共享相同的数据。另一方面,copy_of_df包含不同的数据。
可以通过修改df来验证这一点:
>>> df["z"] = 0
>>> df
x y z
a 1 1 0
b 2 3 0
c 4 9 0
d 8 27 0
e 16 81 0
>>> view_of_df
x y z
a 1 1 0
b 2 3 0
c 4 9 0
d 8 27 0
e 16 81 0
>>> copy_of_df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
您已经为df中的列z的所有元素赋了零。这导致了view_of_df的变化,但是copy_of_df保持不变。
行和列标签也表现出相同的行为:
>>> view_of_df.index is df.index
True
>>> view_of_df.columns is df.columns
True
>>> copy_of_df.index is df.index
False
>>> copy_of_df.columns is df.columns
False
df和view_of_df共享相同的行和列标签,而copy_of_df有单独的索引实例。请记住,您不能修改.index和.columns的特定元素。它们是不可变的对象。
熊猫和熊猫的指数和切片
NumPy 中的基本索引和切片类似于列表和元组的索引和切片。但是,NumPy 和 Pandas 都提供了额外的选项来引用对象及其部件并为其赋值。
NumPy 数组和 Pandas 对象 ( DataFrame和Series)实现了的特殊方法,这些方法能够以类似于容器的方式引用、赋值和删除值:
.__getitem__()引用值。.__setitem__()赋值。.__delitem__()删除数值。
当您在类似 Python 容器的对象中引用、分配或删除数据时,通常会调用这些方法:
var = obj[key]相当于var = obj.__getitem__(key)。obj[key] = value相当于obj.__setitem__(key, value)。del obj[key]相当于obj.__delitem__(key)。
参数key代表索引,可以是整数、切片、元组、列表、NumPy 数组等等。
NumPy 中的索引:副本和视图
在索引数组时,NumPy 有一套与副本和视图相关的严格规则。您获得的是原始数据的视图还是副本取决于您用来索引数组的方法:切片、整数索引或布尔索引。
一维数组
切片是 Python 中一种众所周知的操作,用于从数组、列表或元组中获取特定数据。当您对 NumPy 数组进行切片时,您会看到数组的视图:
>>> arr = np.array([1, 2, 4, 8, 16, 32])
>>> a = arr[1:3]
>>> a
array([2, 4])
>>> a.base
array([ 1, 2, 4, 8, 16, 32])
>>> a.base is arr
True
>>> a.flags.owndata
False
>>> b = arr[1:4:2]
>>> b
array([2, 8])
>>> b.base
array([ 1, 2, 4, 8, 16, 32])
>>> b.base is arr
True
>>> b.flags.owndata
False
您已经创建了原始数组arr,并将其分割成两个更小的数组a和b。a和b都以arr为基准,都没有自己的数据。相反,他们看的是arr的数据:
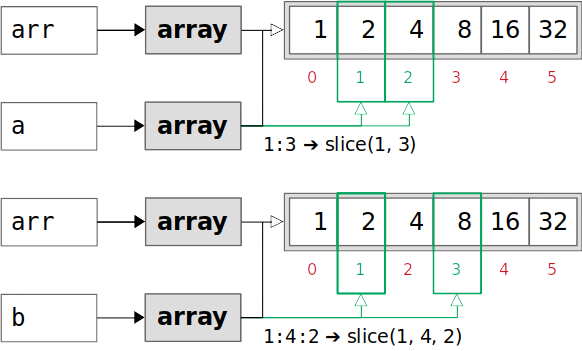
上图中的绿色指数是通过切片获得的。a和b都查看绿色矩形中arr的对应元素。
**注意:**当你有一个很大的原始数组,只需要其中的一小部分时,可以切片后调用.copy(),用del语句删除指向原始的变量。这样,您可以保留副本并从内存中删除原始数组。
虽然切片会返回一个视图,但是在其他情况下,从一个数组创建另一个数组实际上会产生一个副本。
用整数列表索引数组会返回原始数组的副本。副本包含原始数组中的元素,这些元素的索引出现在列表中:
>>> c = arr[[1, 3]]
>>> c
array([2, 8])
>>> c.base is None
True
>>> c.flags.owndata
True
结果数组c包含来自arr的元素,索引为1和3。这些元素具有值2和8。在这种情况下,c是arr的副本,它的.base是None,它有自己的数据:
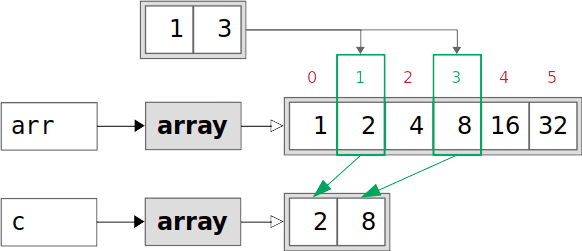
具有所选索引1和3的arr的元素被复制到新数组c中。复印完成后,arr和c是独立的。
还可以用掩码数组或列表来索引 NumPy 数组。遮罩是与原始形状相同的布尔数组或列表。您将得到一个原始数组的副本,它只包含与掩码的True值相对应的元素:
>>> mask = [False, True, False, True, False, False]
>>> d = arr[mask]
>>> d
array([2, 8])
>>> d.base is None
True
>>> d.flags.owndata
True
列表mask在第二和第四位置具有True值。这就是为什么数组d只包含来自arr的第二个和第四个位置的元素。和c的情况一样,d是副本,它的.base是None,它有自己的数据:
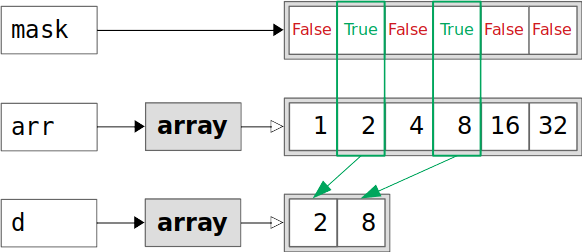
绿色矩形中的arr元素对应于来自mask的True值。这些元素被复制到新数组d中。复制后,arr和d是独立的。
**注意:**可以用另一个 NumPy 的整数数组代替一个 list,但是不是一个 tuple 。
概括一下,这里是您到目前为止创建的引用arr的变量:
# `arr` is the original array:
arr = np.array([1, 2, 4, 8, 16, 32])
# `a` and `b` are views created through slicing:
a = arr[1:3]
b = arr[1:4:2]
# `c` and `d` are copies created through integer and Boolean indexing:
c = arr[[1, 3]]
d = arr[[False, True, False, True, False, False]]
记住,这些例子展示了如何在数组中引用数据。引用数据在切片数组时返回视图,在使用索引和掩码数组时返回副本。另一方面,赋值总是修改数组的原始数据。
现在您已经有了所有这些数组,让我们看看当您改变原始数组时会发生什么:
>>> arr[1] = 64
>>> arr
array([ 1, 64, 4, 8, 16, 32])
>>> a
array([64, 4])
>>> b
array([64, 8])
>>> c
array([2, 8])
>>> d
array([2, 8])
您已经将arr的第二个值从2更改为64。值2也出现在派生数组a、b、c和d中。然而,只有视图a和b被修改:
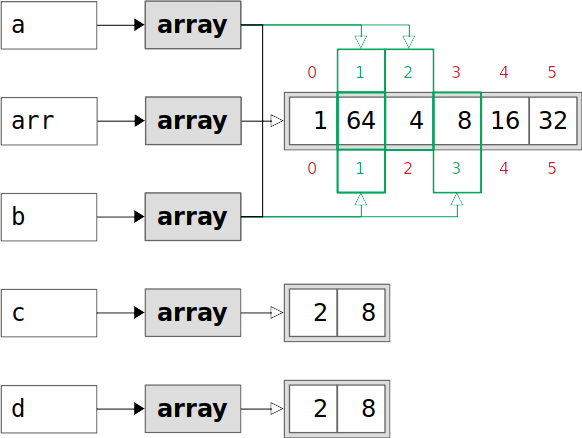
视图a和b查看arr的数据,包括它的第二个元素。这就是你看到变化的原因。副本c和d保持不变,因为它们与arr没有公共数据。它们独立于arr。
数字中的链式索引
这个带有a和b的行为看起来和之前熊猫的例子有什么相似之处吗?有可能,因为链式索引的概念也适用于 NumPy:
>>> arr = np.array([1, 2, 4, 8, 16, 32])
>>> arr[1:4:2][0] = 64
>>> arr
array([ 1, 64, 4, 8, 16, 32])
>>> arr = np.array([1, 2, 4, 8, 16, 32])
>>> arr[[1, 3]][0] = 64
>>> arr
array([ 1, 2, 4, 8, 16, 32])
这个例子说明了在 NumPy 中使用链式索引时副本和视图之间的区别。
在第一种情况下,arr[1:4:2]返回一个视图,该视图引用了arr的数据,并包含元素2和8。语句arr[1:4:2][0] = 64将这些元素中的第一个修改为64。这个变化在arr和arr[1:4:2]返回的视图中都是可见的。
在第二种情况下,arr[[1, 3]]返回一个副本,其中也包含元素2和8。但是这些与arr中的元素不同。它们是新的。arr[[1, 3]][0] = 64修改arr[[1, 3]]返回的副本,保持arr不变。
这与熊猫产生SettingWithCopyWarning的行为本质上是一样的,但这种警告在 NumPy 中并不存在。
多维数组
引用多维数组遵循相同的原则:
- 分割数组会返回视图。
- 使用索引和掩码数组返回副本。
将索引和掩码数组与切片相结合也是可能的。在这种情况下,你会得到副本。
这里有几个例子:
>>> arr = np.array([[ 1, 2, 4, 8],
... [ 16, 32, 64, 128],
... [256, 512, 1024, 2048]])
>>> arr
array([[ 1, 2, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> a = arr[:, 1:3] # Take columns 1 and 2
>>> a
array([[ 2, 4],
[ 32, 64],
[ 512, 1024]])
>>> a.base
array([[ 1, 2, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> a.base is arr
True
>>> b = arr[:, 1:4:2] # Take columns 1 and 3
>>> b
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> b.base
array([[ 1, 2, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> b.base is arr
True
>>> c = arr[:, [1, 3]] # Take columns 1 and 3
>>> c
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> c.base
array([[ 2, 32, 512],
[ 8, 128, 2048]])
>>> c.base is arr
False
>>> d = arr[:, [False, True, False, True]] # Take columns 1 and 3
>>> d
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> d.base
array([[ 2, 32, 512],
[ 8, 128, 2048]])
>>> d.base is arr
False
在这个例子中,你从二维数组arr开始。对行应用切片。使用冒号语法(:),相当于slice(None),意味着您想要获取所有行。
当您使用列的切片1:3和1:4:2时,会返回视图a和b。然而,当你应用列表[1, 3]和遮罩[False, True, False, True]时,你会得到副本c和d。
a和b的.base都是arr本身。c和d都有自己与arr无关的基地。
与一维数组一样,当您修改原始数组时,视图会发生变化,因为它们看到的是相同的数据,但副本保持不变:
>>> arr[0, 1] = 100
>>> arr
array([[ 1, 100, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> a
array([[ 100, 4],
[ 32, 64],
[ 512, 1024]])
>>> b
array([[ 100, 8],
[ 32, 128],
[ 512, 2048]])
>>> c
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> d
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
您将arr中的值2更改为100,并修改了视图a和b中的相应元素。副本c和d不能这样修改。
要了解更多关于索引 NumPy 数组的信息,可以查看官方快速入门教程和索引教程。
熊猫的索引:拷贝和浏览
您已经了解了如何在 NumPy 中使用不同的索引选项来引用实际数据(一个视图,或浅层副本)或新复制的数据(深层副本,或只是副本)。NumPy 对此有一套严格的规则。
Pandas 非常依赖 NumPy 阵列,但也提供了额外的功能和灵活性。正因为如此,返回视图和副本的规则更加复杂,也不那么简单。它们取决于数据的布局、数据类型和其他细节。事实上,Pandas 通常不保证视图或副本是否会被引用。
**注:**熊猫的索引是一个非常广泛的话题。正确使用熊猫数据结构是必不可少的。您可以使用多种技术:
- 字典式的符号
- 类属性(点)符号
- 存取器
.loc[]、.iloc[]、.at[]和.iat
更多信息,请查看官方文档和熊猫数据框架:让数据工作变得愉快。
在这一节中,您将看到两个熊猫与 NumPy 行为相似的例子。首先,您可以看到用一个切片访问df的前三行会返回一个视图:
>>> df = pd.DataFrame(data=data, index=index)
>>> df["a":"c"]
x y z
a 1 1 45
b 2 3 98
c 4 9 24
>>> df["a":"c"].to_numpy().base
array([[ 1, 2, 4, 8, 16],
[ 1, 3, 9, 27, 81],
[45, 98, 24, 11, 64]])
>>> df["a":"c"].to_numpy().base is df.to_numpy().base
True
该视图查看与df相同的数据。
另一方面,用标签列表访问df的前两列会返回一个副本:
>>> df = pd.DataFrame(data=data, index=index)
>>> df[["x", "y"]]
x y
a 1 1
b 2 3
c 4 9
d 8 27
e 16 81
>>> df[["x", "y"]].to_numpy().base
array([[ 1, 2, 4, 8, 16],
[ 1, 3, 9, 27, 81]])
>>> df[["x", "y"]].to_numpy().base is df.to_numpy().base
False
副本的.base与df不同。
在下一节中,您将找到与索引数据帧和返回视图和副本相关的更多细节。你会看到一些情况,熊猫的行为变得更加复杂,与 NumPy 不同。
在 Pandas 中使用视图和副本
正如您已经了解的,当您试图修改数据的副本而不是原始数据时,Pandas 可以发出一个SettingWithCopyWarning。这通常遵循链式索引。
在本节中,您将看到一些产生SettingWithCopyWarning的特定案例。您将确定原因并学习如何通过正确使用视图、副本和访问器来避免它们。
链式索引SettingWithCopyWarning和
在第一个例子中,你已经看到了SettingWithCopyWarning如何与链式索引一起工作。让我们详细说明一下。
您已经创建了对应于df["z"] < 50的数据帧和遮罩Series对象:
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> mask = df["z"] < 50
>>> mask
a True
b False
c True
d True
e False
Name: z, dtype: bool
你已经知道赋值df[mask]["z"] = 0失败了。在这种情况下,您会得到一个SettingWithCopyWarning:
>>> df[mask]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
赋值失败,因为df[mask]返回一个副本。更准确地说,分配是在副本上进行的,而df不受影响。
你也看到了在熊猫身上,评估顺序很重要。在某些情况下,您可以切换操作顺序以使代码正常工作:
>>> df["z"][mask] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
df["z"][mask] = 0成功,你得到没有SettingWithCopyWarning的修改后的df。
建议使用访问器,但是使用它们也会遇到麻烦:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
在这种情况下,df.loc[mask]返回一个副本,赋值失败,Pandas 正确地发出警告。
在某些情况下,Pandas 未能发现问题,并且副本上的作业在没有SettingWithCopyWarning的情况下通过:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[["a", "c", "e"]]["z"] = 0 # Assignment fails, no warning
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
在这里,您不会收到一个SettingWithCopyWarning并且df不会被更改,因为df.loc[["a", "c", "e"]]使用一个索引列表并返回一个副本,而不是一个视图。
在某些情况下,代码是有效的,但 Pandas 还是会发出警告:
>>> df = pd.DataFrame(data=data, index=index)
>>> df[:3]["z"] = 0 # Assignment succeeds, with warning
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 0
b 2 3 0
c 4 9 0
d 8 27 11
e 16 81 64
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc["a":"c"]["z"] = 0 # Assignment succeeds, with warning
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 0
b 2 3 0
c 4 9 0
d 8 27 11
e 16 81 64
在这两种情况下,选择带有切片的前三行并获取视图。视图和df上的分配都成功。但是你还是收到一个SettingWithCopyWarning。
执行此类操作的推荐方式是避免链式索引。访问器在这方面很有帮助:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask, "z"] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
这种方法使用一个方法调用,没有链式索引,代码和您的意图都更加清晰。另外,这是一种稍微更有效的分配数据的方式。
数据类型对视图、副本和SettingWithCopyWarning 的影响
在 Pandas 中,创建视图和创建副本之间的区别也取决于所使用的数据类型。在决定是返回视图还是副本时,Pandas 处理单一数据类型的数据帧与处理多种数据类型的数据帧的方式不同。
让我们关注本例中的数据类型:
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> df.dtypes
x int64
y int64
z int64
dtype: object
您已经创建了包含所有整数列的数据框架。这三列都有相同的数据类型,这一点很重要!在这种情况下,您可以选择带有切片的行并获得视图:
>>> df["b":"d"]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 0
c 4 9 0
d 8 27 0
e 16 81 64
这反映了到目前为止您在本文中看到的行为。df["b":"d"]返回一个视图并允许你修改原始数据。这就是赋值df["b":"d"]["z"] = 0成功的原因。请注意,在这种情况下,无论是否成功更改为df,您都会获得一个SettingWithCopyWarning。
如果您的数据帧包含不同类型的列,那么您可能会得到一个副本而不是一个视图,在这种情况下,相同的赋值将失败:
>>> df = pd.DataFrame(data=data, index=index).astype(dtype={"z": float})
>>> df
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
>>> df.dtypes
x int64
y int64
z float64
dtype: object
>>> df["b":"d"]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
在这种情况下,您使用了。astype() 创建一个有两个整数列和一个浮点列的 DataFrame。与前面的例子相反,df["b":"d"]现在返回一个副本,所以赋值df["b":"d"]["z"] = 0失败,df保持不变。
当有疑问时,避免混淆,在整个代码中使用.loc[]、.iloc[]、.at[]和.iat[]访问方法!
分层索引SettingWithCopyWarning和
分级索引或多索引,是 Pandas 的一个特性,它使您能够根据层次结构在多个级别上组织行或列索引。这是一个强大的功能,增加了熊猫的灵活性,并使数据能够在两个以上的维度上工作。
使用元组作为行或列标签来创建分层索引:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64])},
... index=["a", "b", "c", "d", "e"]
... )
>>> df
powers random
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
现在您有了具有两级列索引的数据框架df:
- 第一级包含标签
powers和random。 - 第二级有标签
x和y,分别属于powers和z,属于random。
表达式df["powers"]将返回一个 DataFrame,其中包含powers下面的所有列,即列x和y。如果你只想得到列x,那么你可以同时通过powers和x。正确的做法是使用表达式df["powers", "x"]:
>>> df["powers"]
x y
a 1 1
b 2 3
c 4 9
d 8 27
e 16 81
>>> df["powers", "x"]
a 1
b 2
c 4
d 8
e 16
Name: (powers, x), dtype: int64
>>> df["powers", "x"] = 0
>>> df
powers random
x y z
a 0 1 45
b 0 3 98
c 0 9 24
d 0 27 11
e 0 81 64
在多级列索引的情况下,这是获取和设置列的一种方式。您还可以对多索引数据帧使用访问器来获取或修改数据:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64])},
... index=["a", "b", "c", "d", "e"]
... )
>>> df.loc[["a", "b"], "powers"]
x y
a 1 1
b 2 3
上面的例子使用了.loc[]来返回一个 DataFrame,其中包含行a和b以及列x和y,它们位于powers的下面。您可以类似地获得特定的列(或行):
>>> df.loc[["a", "b"], ("powers", "x")]
a 1
b 2
Name: (powers, x), dtype: int64
在这个例子中,您指定您想要行a和b与列x的交集,该列在powers的下面。要获得一个单独的列,可以传递索引元组("powers", "x")并获得一个Series对象作为结果。
您可以使用这种方法修改具有分层索引的数据帧的元素:
>>> df.loc[["a", "b"], ("powers", "x")] = 0
>>> df
powers random
x y z
a 0 1 45
b 0 3 98
c 4 9 24
d 8 27 11
e 16 81 64
在上面的例子中,您避免了带访问器(df.loc[["a", "b"], ("powers", "x")])和不带访问器(df["powers", "x"])的链式索引。
正如您之前看到的,链式索引会导致一个SettingWithCopyWarning:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64])},
... index=["a", "b", "c", "d", "e"]
... )
>>> df
powers random
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> df["powers"]
x y
a 1 1
b 2 3
c 4 9
d 8 27
e 16 81
>>> df["powers"]["x"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
powers random
x y z
a 0 1 45
b 0 3 98
c 0 9 24
d 0 27 11
e 0 81 64
这里,df["powers"]返回一个带有列x和y的数据帧。这只是一个指向来自df的数据的视图,所以赋值成功并且df被修改。但是熊猫还是发出了SettingWithCopyWarning。
如果您重复相同的代码,但是在df的列中使用不同的数据类型,那么您将得到不同的行为:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> df
powers random
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
>>> df["powers"]
x y
a 1 1
b 2 3
c 4 9
d 8 27
e 16 81
>>> df["powers"]["x"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
powers random
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
这次,df的数据类型不止一种,所以df["powers"]返回一个副本,df["powers"]["x"] = 0在这个副本上做了更改,df保持不变,给你一个SettingWithCopyWarning。
修改df的推荐方法是避免链式赋值。您已经了解到访问器非常方便,但是并不总是需要它们:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> df["powers", "x"] = 0
>>> df
powers random
x y z
a 0 1 45
b 0 3 98
c 0 9 24
d 0 27 11
e 0 81 64
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> df.loc[:, ("powers", "x")] = 0
>>> df
powers random
x y z
a 0 1 45.0
b 0 3 98.0
c 0 9 24.0
d 0 27 11.0
e 0 81 64.0
在这两种情况下,您都可以获得没有SettingWithCopyWarning的修改后的数据帧df。
改变默认的SettingWithCopyWarning行为
SettingWithCopyWarning是一个警告,不是一个错误。您的代码在发布时仍然会执行,即使它可能不会像预期的那样工作。
要改变这种行为,可以用 pandas.set_option() 修改熊猫mode.chained_assignment选项。您可以使用以下设置:
pd.set_option("mode.chained_assignment", "raise")引出一个SettingWithCopyException。pd.set_option("mode.chained_assignment", "warn")发出一个SettingWithCopyWarning。这是默认行为。pd.set_option("mode.chained_assignment", None)抑制警告和错误。
例如,这段代码将引发一个SettingWithCopyException,而不是发出一个SettingWithCopyWarning:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> pd.set_option("mode.chained_assignment", "raise")
>>> df["powers"]["x"] = 0
除了修改默认行为,您还可以使用 get_option() 来检索与mode.chained_assignment相关的当前设置:
>>> pd.get_option("mode.chained_assignment")
'raise'
在这种情况下,您得到了"raise",因为您用set_option()改变了行为。正常情况下,pd.get_option("mode.chained_assignment")返回"warn"。
虽然您可以抑制它,但是请记住,SettingWithCopyWarning在通知您不正确的代码时非常有用。
结论
在本文中,您了解了 NumPy 和 Pandas 中的视图和副本,以及它们的行为有何不同。您还看到了什么是SettingWithCopyWarning以及如何避免它所指向的细微错误。
具体来说,您已经了解了以下内容:
- NumPy 和 Pandas 中基于索引的赋值可以返回视图或副本。
- 视图和副本都是有用的,但是它们有不同的行为。
- 必须特别注意避免在副本上设置不需要的值。
- Pandas 中的访问器对于正确分配和引用数据是非常有用的对象。
理解视图和副本是正确使用 NumPy 和 Pandas 的重要要求,尤其是在处理大数据时。现在,您已经对这些概念有了坚实的理解,您已经准备好深入数据科学这个激动人心的世界了!
如果你有任何问题或意见,请写在下面的评论区。******